About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
High-performance SnapML preprocessing for machine learning on IBM Z
Learn how SnapML uses efficient preprocessing, C++ execution, and consistent scikit‑learn pipelines to deliver accurate and low latency machine learning inference on IBM Z
On this page
Scikit‑learn compatible preprocessing is essential for high‑performance SnapML inference on IBM Z. When developers use clean and well‑structured data during training, SnapML applies the same transformations in optimized C++ during inference. This process delivers accurate, consistent, and low‑latency predictions for enterprise workloads.
SnapML provides high‑throughput and low‑latency machine learning inference by running models and preprocessing logic in optimized C++ on IBM Z systems. To get these performance benefits, developers must define preprocessing steps clearly and fit them during training. This preparation ensures that SnapML can apply the same preprocessing steps during inference, which improves accuracy and consistency.
Machine learning models do not work on raw data. Machine learning models learn patterns from numerical values that come from preprocessing. In enterprise areas such as financial fraud detection, credit scoring, and risk analytics, raw datasets often contain missing values, categorical features, uneven distributions, and inconsistent scales. If a developer sends this raw data directly into a model, the model produces unstable training results, weak generalization, and unreliable predictions. No matter how powerful the algorithm is, poor preprocessing or inadequate preprocessing prevents the model from generating accurate and reliable predictions.
Preprocessing makes sure that data is cleaned, normalized, encoded, and organized in a way that matches the mathematical requirements of machine learning algorithms. In SnapML, preprocessing has an additional purpose. Preprocessing defines the transformations that SnapML will run efficiently in C++ during inference. This approach removes Python overhead and supports latency and throughput that are suitable for production environments.
For real‑time and latency‑sensitive workloads such as transaction scoring or fraud detection, efficient preprocessing is as important as fast model execution.
SnapML preprocessing for scikit‑learn workflows
SnapML combines the usability of scikit‑learn with the performance of optimized C++ execution. During model development, data scientists create preprocessing pipelines by using familiar scikit‑learn transformers in Python. These pipelines are trained and validated in the same way as a standard scikit‑learn workflow.
During inference, SnapML applies the same preprocessing logic by using it's C++ backend. This approach removes Python overhead and keeps the preprocessing steps consistent between training and production.
SnapML supports many preprocessing techniques, including FunctionTransformer, KBinsDiscretizer, Normalizer, and categorical encoders such as OneHotEncoder, OrdinalEncoder, and TargetEncoder.
Graph feature preprocessor for graph-based feature engineering
The graph feature preprocessor (GFP) solves a common problem in tabular preprocessing by capturing relationships between entities. GFP creates a dynamic graph where nodes represent entities such as customers, merchants, and devices, and edges represent interactions such as transactions, transfers, and logins.
GFP computes structural features and temporal features from this graph. These features include fan in degree, fan out degree, sudden changes in connectivity, repeated interaction cycles, and neighborhood patterns. These features reveal behavioral signals that do not appear in tabular data.
Research shows that GFP features can perform better than features from graph neural network models for fraud detection and anomaly detection while still supporting low latency inference on multi-core CPUs.
Preprocessing pipeline export for training and production consistency
SnapML allows developers to export preprocessing pipelines that are trained in scikit‑learn into a JSON file. This JSON file records every transformation that the training pipeline applies. This process ensures that the same transformations are applied during inference.
An example of training and preprocessing a pipeline follows:
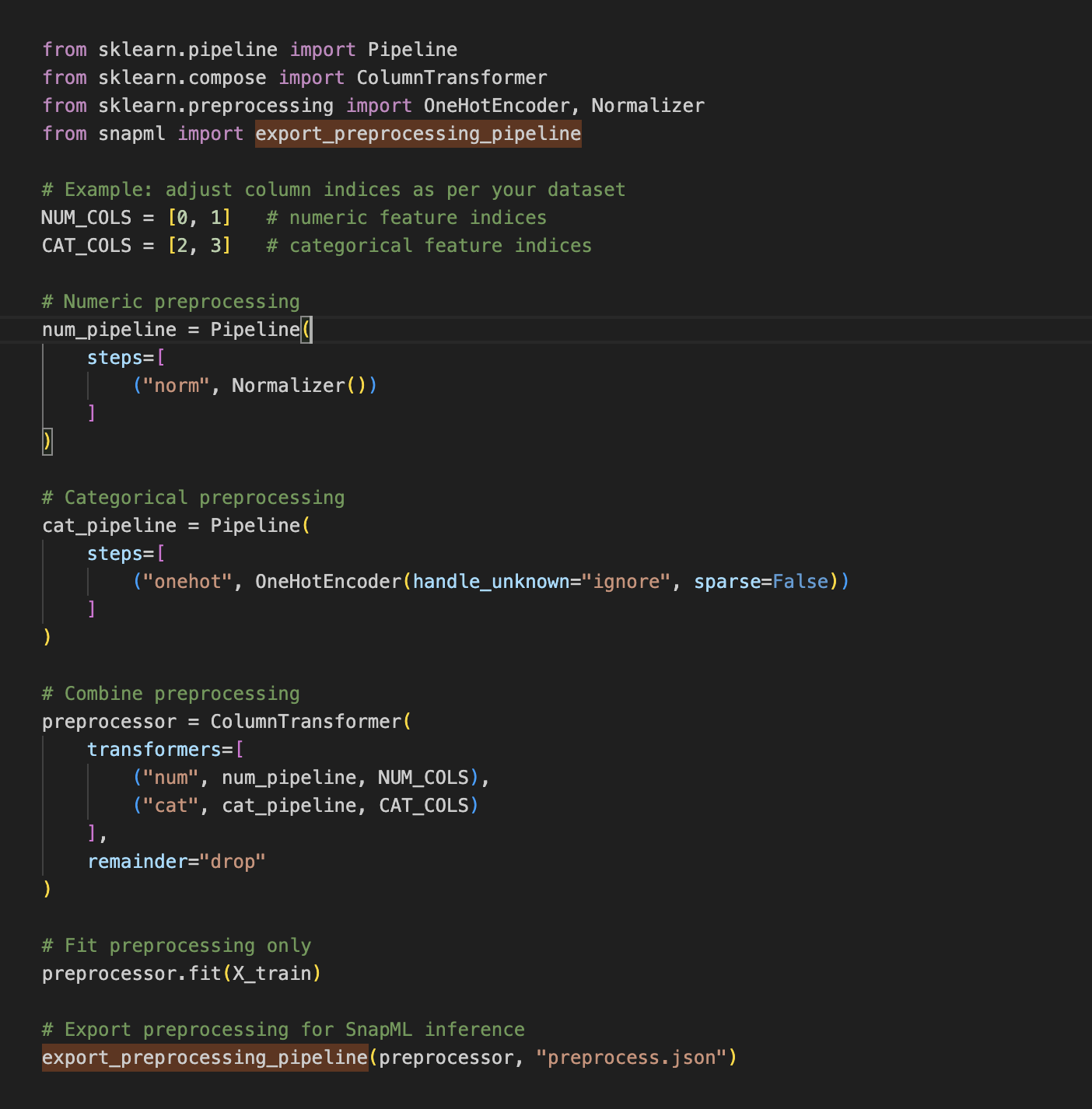
Example of a training and preprocessing pipeline
The exported JSON file is used by SnapML during deployment. SnapML runs the preprocessing steps in optimized C++ instead of Python. This approach provides consistency, reproducibility, and high performance in production environments.
Summary
Preprocessing is an essential step for accurate and stable machine learning models. SnapML improves traditional preprocessing pipelines by allowing developers to define transformations with familiar scikit‑learn APIs and then run those same transformations efficiently in C++ during inference.
SnapML supports numerical transformations, categorical encodings, and graph‑based feature engineering. These features help enterprise workloads achieve high accuracy and low latency. The pipeline export feature keeps preprocessing consistent between training and production and removes training and serving mismatch.
Disclaimer
The information in this article is for informational use and educational use only. The information may change based on product updates, official documentation, and real‑world conditions.