About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Advance machine learning workflows with IBM Watson Pipelines
Create logical conditions, define global objects, add loops, and integrate with IBM Cloud services
On this page
Archived content
Archive date: 2024-12-10
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.Data scientists face significant difficulties in executing machine learning (ML) tasks. Especially when they need to automate complicated ML tasks and scale them up cloud natively along with programmatic logic such as conditional statements, iterations, error handling, and parallel execution. In 2022, IBM introduced IBM Watson Pipelines (previously IBM Watson Studio Pipelines) to help developers orchestrate the flow of assets from creation through deployment on IBM Cloud. You can further enhance and scale your cloud-based ML pipelines with different Watson services, such as AutoAI and IBM DataStage, by automating parts of your workflows.
In a previous tutorial, I demonstrated how to create pipelines with a gallery sample to learn how Watson Pipelines orchestrates AutoAI for model training and production model deployment. In this article, I explain how to use more advanced Watson Pipelines features and integrate DataStage to make your existing ML pipelines more intelligent and flexible, covering more use cases.
Prerequisites
- Register for an IBM Cloud account.
- Complete the Watson Pipelines introduction tutorial.
Conditions
With Watson Pipelines, you can create logical conditions to determine whether a task needs to be skipped or stopped during a pipeline runtime. You can expand your pipelines with more flexible pipelines and cover different pipeline edge cases. For example, to determine whether your data is ready to train, specify a condition after the data step to ensure the pipeline environment has the proper resource to train the ML model. As the following animation demonstrates, you can insert a condition to check whether the pipeline pushes to your expected workspace. If the condition fails, the trained model does not deploy into production since the workspace condition is not matched.

Figure 1. To define a condition, hover over the link between two connected nodes on the canvas and click Add condition to create logical conditions for child tasks. Rewatch animation.
For more information about adding conditions to pipelines, refer to the product documentation.
Global objects
With Watson Pipelines, you can define global objects, such as parameters and variables, that are configurable and updated during any task within the same pipeline. For example, you can define global parameters that are configurable for every run and easily inserted into any task. All of the pipeline configurations can be done in the same page.
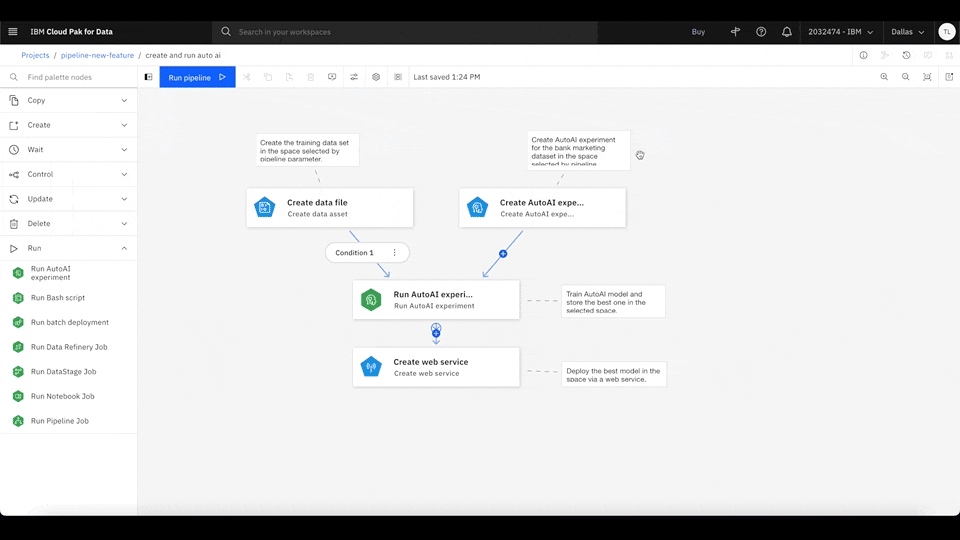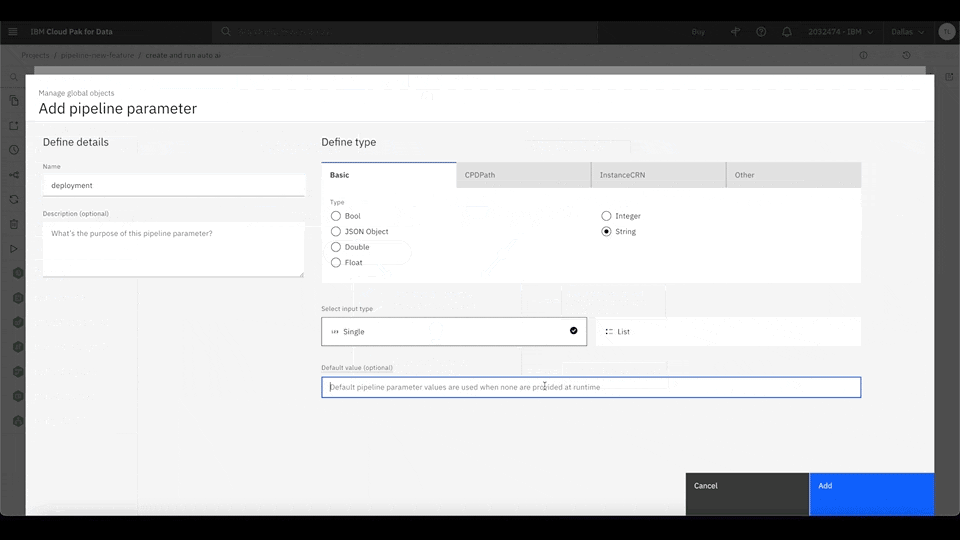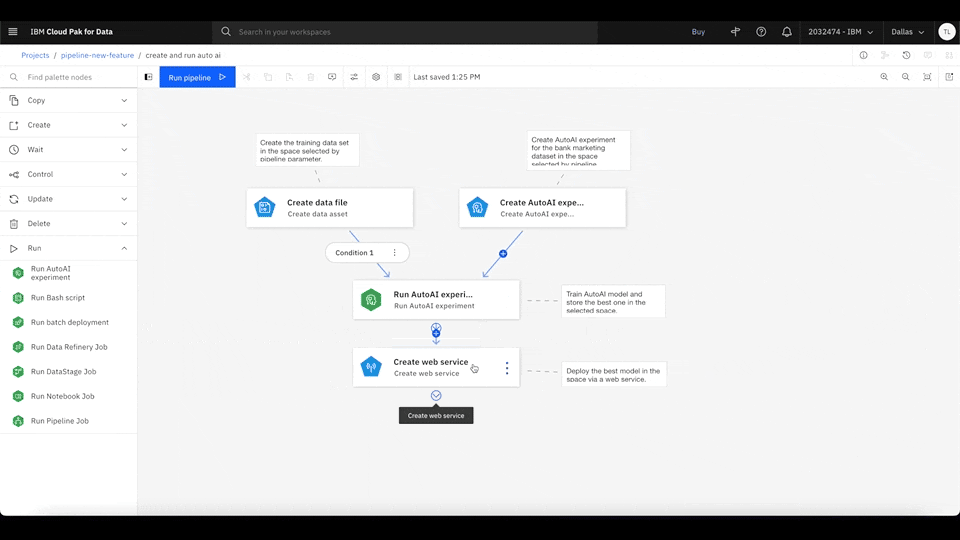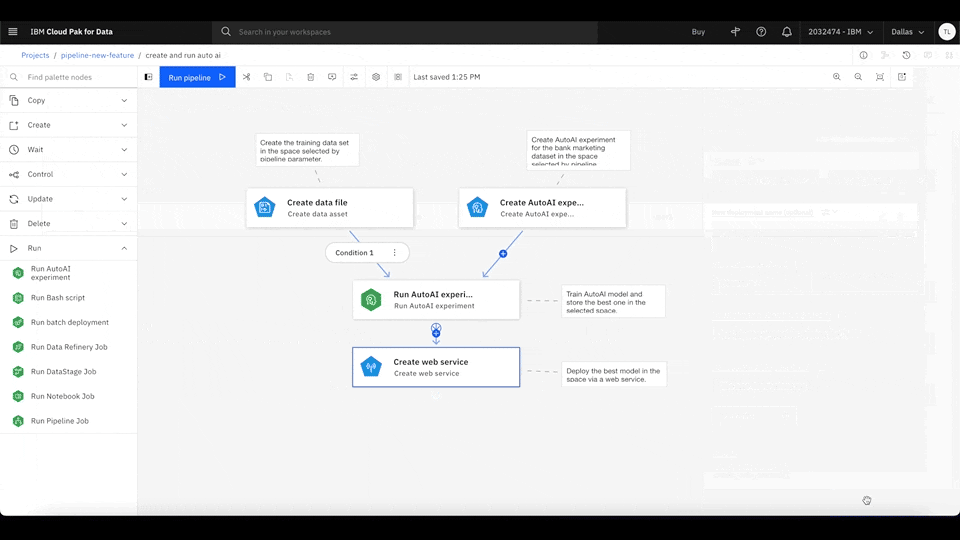
Figure 2. Click the Global objects icon on the canvas menu and select Add pipeline parameter to create a new string parameter. Then, open the Create web service node configuration panel and assign your new pipeline parameter as the node input. Rewatch animation.
For more information about configuring global objects, refer to the product documentation.
Loops
With Watson Pipelines, you can create loops among several task sequences and iterate each task sequence with different inputs. There are two types of loops: sequence and parallel. A loop in sequence traverses each parameter one at a time as its inputs, which is good when you want programmatic looping logic such as break and continue. In comparison, a loop in parallel distributes all parameters at once and runs simultaneously, which is better suited for finishing the pipeline as soon as possible.
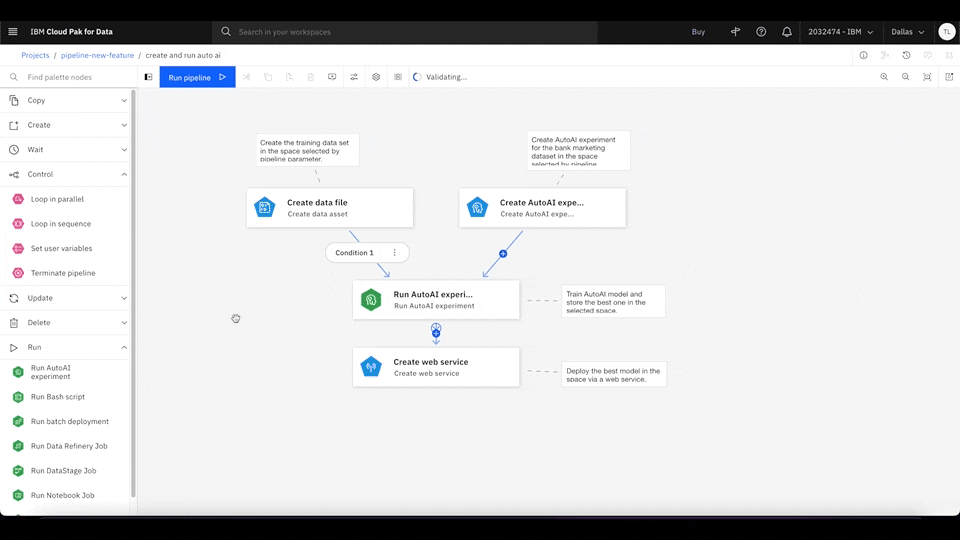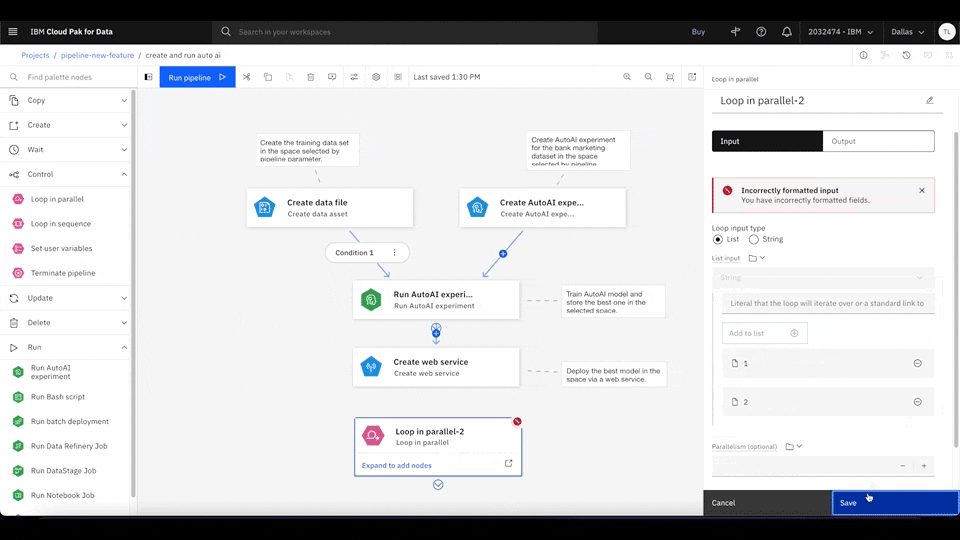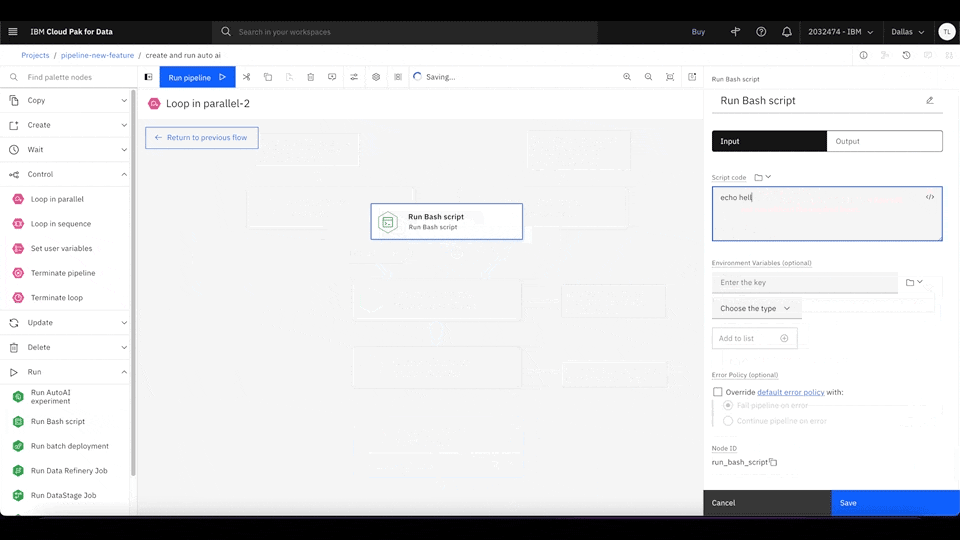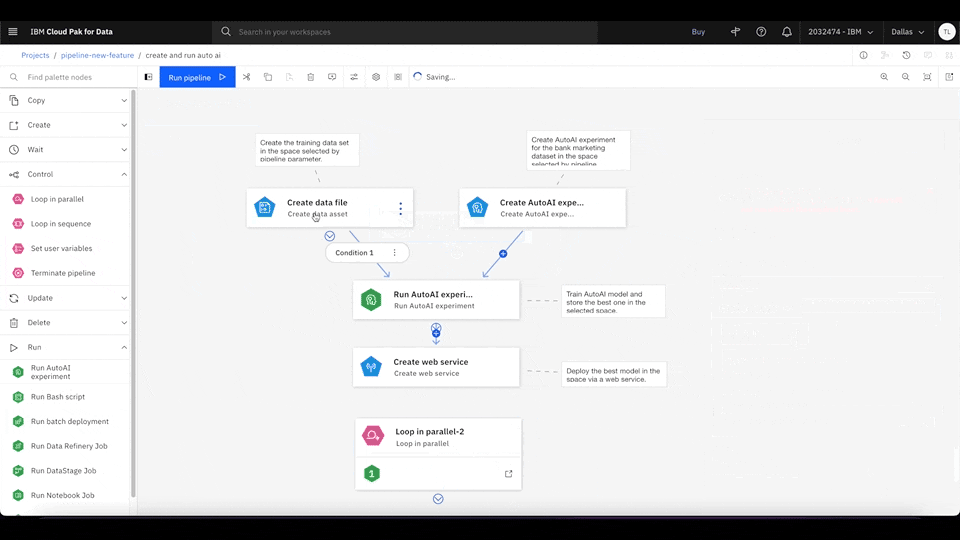
Figure 3. Drag the Loop in parallel node from the Palette menu to the main canvas. Insert two new parameter strings (1 and 2) for the loop node to iterate. Click Expand to add nodes to enter the inner canvas and define the nodes that the loop iterates through. Rewatch animation.
For more information about adding loops, refer to the product documentation.
Integrating IBM Cloud services with Watson Pipelines
Waston Pipelines seamlessly integrates with several IBM Cloud services, which makes ML orchestration much easier. For example, to integrate data by using a DataStage job as part of your ML pipeline, simply drag the Run DataStage Job node into the main canvas and select the job that you want to use. You can use different IBM Cloud services to run complex and advanced ML workloads, such as data processing and model training, all in the same place.
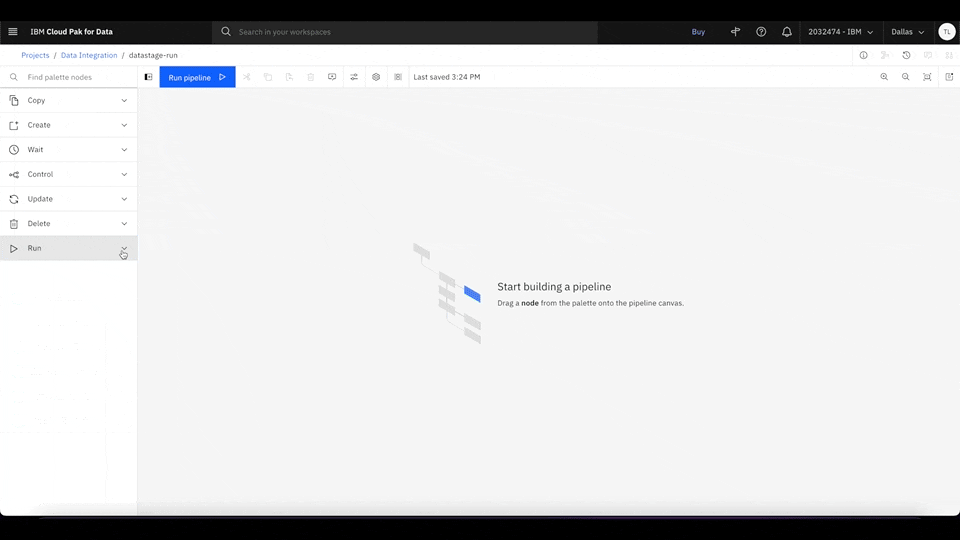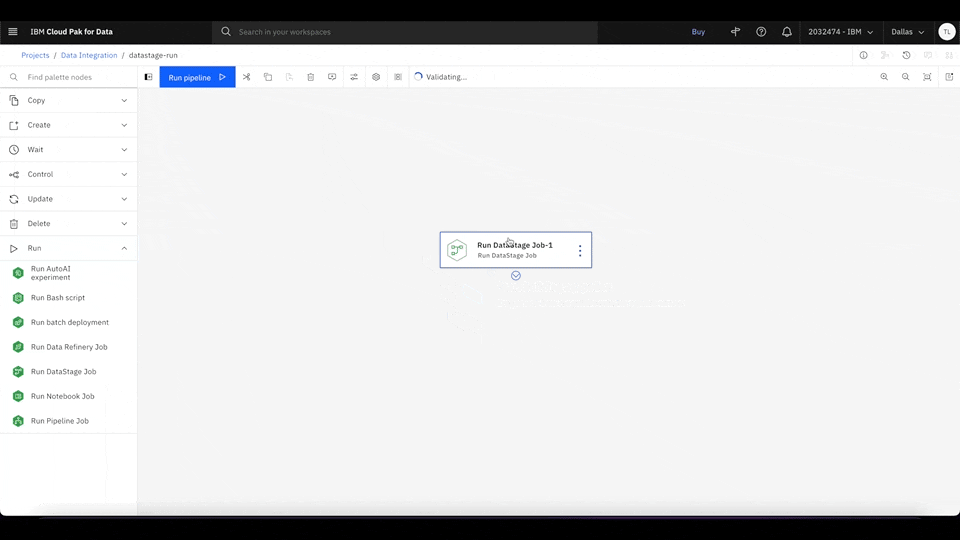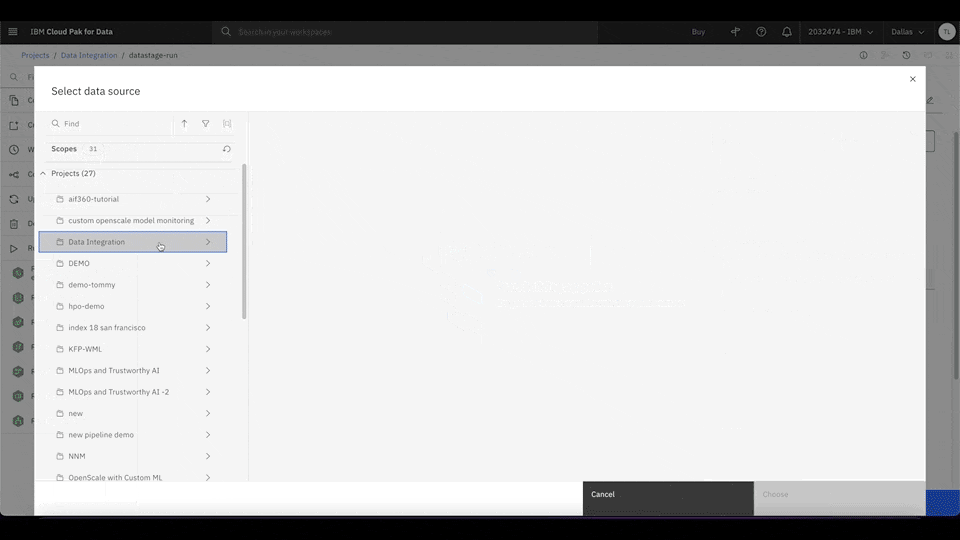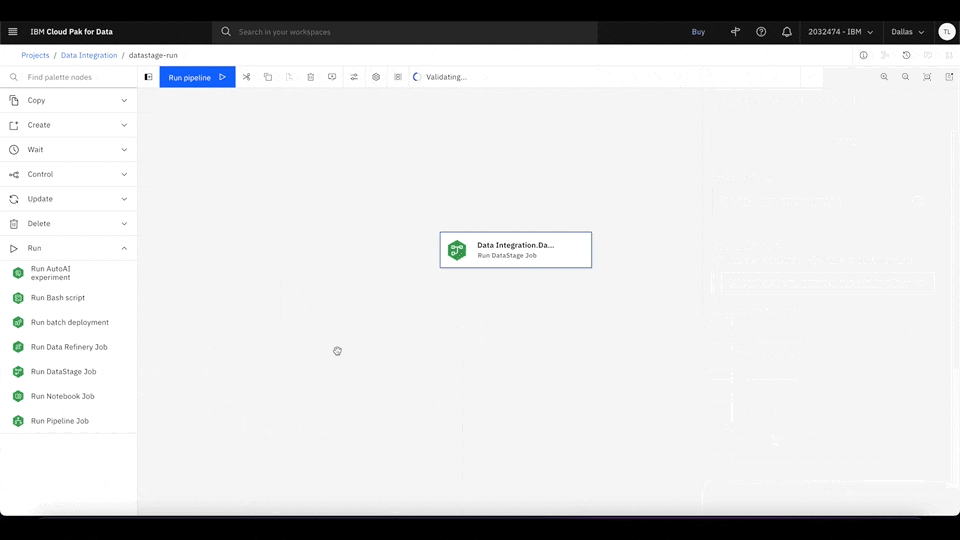
Figure 4. Drag the Run DataStage Job node into the main canvas. Click Select Job to select the DataStage data integration job for Watson Pipelines to run. Rewatch animation.
For more information about integrating other IBM Cloud services and running custom scripts, refer to the product documentation.
Summary
In this article, you learned about three advanced features of Watson Pipelines and how to integrate with other IBM Cloud services. However, there are more new Watson Pipelines features that I did not cover. If you want to learn how to handle pipeline errors, configure pipeline environments, and use different data storage, visit the Creating a pipeline section of the product documentation.