About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Vibe coding your way through expense reports
Learn how to turn hotel receipts into clean, structured JSON using natural language prompts and large language models. No coding required
On this page
Expense reports are tedious, and traditional tools often make mistakes. Can Generative AI handle them with zero coding? Let’s find out.
Skip the traditional expense tools
Here’s the bottom line: I uploaded hotel receipts to a large language model (LLM) and got clean, structured JSON; no coding needed. Just simple natural language prompts using watsonx.ai.
This tutorial explores a new way of working called vibe coding. Instead of writing code, you describe the task, and the AI does the rest. You guide the output, not build it line-by-line.
Most expense tools are clunky and often get things wrong. So, I skipped them and tested if an LLM could handle receipts with zero tech setup. It worked better than expected.
What you get: clean, structured expense data from receipts
Here’s an example of the output I generated using just a natural language prompt:
{
"expenses": [
{
"hotelName": "HOTEL GOOD TIMES WESTCHESTER, NY",
"dateOfExpense": "2024-09-16",
"typeOfExpense": "room rate",
"amountCharged": 196.94,
"currencyType": "dollar"
},
{
"hotelName": " HOTEL GOOD TIMES WESTCHESTER, NY",
"dateOfExpense": "2024-09-16",
"typeOfExpense": "taxes",
"amountCharged": 16.49,
"currencyType": "dollar"
}
]
}
This JSON is clean, consistent, and ready for automation. No code was written, just a prompt to the LLM.
Where this was tested and how it runs
I used IBM’s watsonx.ai, which runs as a Software as a Service (SaaS). That means no setup or maintenance, just log in through the IBM Cloud Catalog and start working.
Businesses can choose from two deployment options:
Multi-tenant: Shared platform with separate spaces for each user.
Single-tenant: A private, isolated version for one organization.
For this experiment, I used the multi-tenant SaaS version. It was quick to get started, and everything ran smoothly out-of-the-box.
Why use JSON?
JSON is a simple, structured format that works well for both humans and machines. It’s the standard way to move data between systems such as APIs, databases, or apps.
If an LLM can turn receipts into JSON, you can skip manual data entry and plug the results straight into expense tools or approval systems, no extra clicks or complicated interfaces.
How it was done step-by-step
Step 1. Getting started with IBM Cloud and watsonx.ai
Sign up for IBM watsonx.ai trial:
a. Go to https://www.ibm.com/products/watsonx-ai.
b. Click Start your free trial.
c. Sign in with your IBM ID or create a new IBM Cloud account.
Access watsonx.ai and create a project:
a. After signing in, go to the IBM Cloud Console.
b. Click the Navigation menu (☰) > watsonx > watsonx.ai
c. On the watsonx.ai dashboard, go to Navigation menu (☰) > Projects > View All Projects
i. Click **New Project** ii. Attach an existing object storage instance or create a new one.Open Prompt Lab:
a. In your project dashboard, go to the Chat and build prompts with foundation models tab.
b. Click on the Chat tab.
Pick a Model:
a. At the top right, select the model you want to use.
Upload document and ask questions:
a. In the prompt editor, click the arrow next to the chat box and select Add documents.
b. Click Browse and choose a PDF, DOC, or TXT file from your computer.
c. After uploading, you can start chatting with the document.
Step 2. Write a prompt to create a schema
A schema defines the structure and rules for JSON data. Using IBM watsonx.ai Prompt Lab, I asked the model this prompt:
Create a JSON schema to capture hotel expenses. Each expense should include: Hotel name, Date of expense, Type of expense, Amount charged, and Currency Type. The type of expense can only be one of these: taxes, room rate, dining, parking, tips, or miscellaneous. Currency Type can be dollar, euro, real, etc.
The model quickly generated this schema:
{
"$schema": "[http://json-schema.org/draft-07/schema#](http://json-schema.org/draft-07/schema#)",
"title": "HotelExpense",
"type": "object",
"properties": {
"expenses": {
"type": "array",
"items": {
"type": "object",
"properties": {
"hotelName": {
"type": "string",
"minLength": 1,
"maxLength": 100
},
"dateOfExpense": {
"type": "string",
"format": "date",
"minLength": 10,
"maxLength": 10
},
"typeOfExpense": {
"type": "string",
"enum": ["taxes", "room rate", "dining", "parking", "tips", "miscellaneous"]
},
"amountCharged": {
"type": "number",
"minimum": 0
},
"currencyType": {
"type": "string",
"enum": ["dollar", "euro", "real", "pound", "yen", "swiss franc"]
}
},
"required": ["hotelName", "dateOfExpense", "typeOfExpense", "amountCharged", "currencyType"]
}
}
}
}
This gave me a good base schema in seconds. I also checked it with a free online JSON validator.
Step 3. Use a prompt to extract data
Next, I wrote a prompt to extract the needed data from the hotel receipts using the JSON schema from Step 2.
Process the attached PDF hotel receipt and create output following the JSON schema. If the document is not a hotel receipt, do not produce any output. Only include expense line items and exclude payments or credits. Carefully analyze each line item and description to categorize the expense_type attribute.
The JSON schema is: [Pasted JSON schema from Step 2.]
Testing with real hotel receipts
To make this a real-world test, I used actual hotel receipts — not clean, ideal samples. The goal was to see how the model handles messy, varied formats and where it performs best.
PDF receipts from different hotels
Why: Every hotel uses a different format.
How it went: The model did well here. It accurately parsed PDFs with clear line items, headers, and layouts.

Email receipts
Why: Emails are often messy, with headers, footers, disclaimers, and a lot of extra content.
How it went: Results were mixed. The model sometimes missed duplicate charges or miscategorized items. Adding more specific instructions to the prompt such as “List all charges, even if repeated, and follow the JSON schema for categories” helped improve the output.

Photos of printed receipts (Vision LLM test)
Why: People often snap photos of printed receipts for expense reports.
How it went: This was the toughest challenge. Vision models had trouble with unclear or crumpled images. The JSON output was sometimes incomplete or incorrectly categorized. These models show promise but still need human review to ensure accuracy.

Model comparison
Here’s how different models performed in extracting structured data from receipts:
| Model | JSON Valid | Field Accuracy | Common Issues | Notes |
|---|---|---|---|---|
| granite-8b-instruct | Yes | High | Occasional small errors | Best results |
| granite-3-2b-instruct | Yes | Medium | Some mislabeled fields | Lighter, but less accurate |
| granite-vision-3-2-2b | NA: Used JSON generated from instruct models | Low | Hallucinates | Not reliable yet |
| llama-guard-11b-vision | NA: Used JSON generated from instruct models | Medium | Some mislabeled fields | Decent with human corrections |
The larger granite-8b-instruct model gave the best results. Vision models such as llama-guard-11b-vision show potential but need some help from humans. All of this was done without writing code. Just using a strong foundation model and thoughtful prompts.
Using the watsonx.ai API
While this example used the watsonx.ai interface, the platform also offers a powerful API for automation. You can send prompts to the model programmatically similar to typing them in the UI.
For this tutorial, I copied text from a hotel receipt and submitted it to the API. The response came back as clean, structured JSON.
In the Prompt Lab UI, there’s an option to copy the exact curl command used behind the scenes. This makes it easy to understand how the API works and reuse it in your own apps or scripts. Just type your prompt, click copy, and you’re ready to go.
To use the API, you need to include a Bearer token in the authorization header (replace YOUR_ACCESS_TOKEN with your actual token). I wasn’t sure what that meant, so I just asked the model and got a clear answer.
Why use the API? Because it helps you automate. Instead of manually uploading files or typing prompts in the UI, your app can send requests and get back structured data. It’s a quick way to go from idea to production.
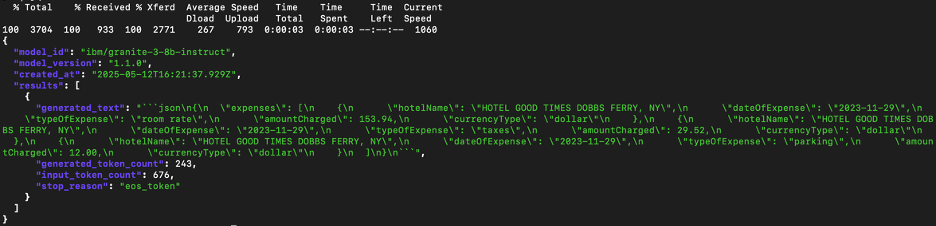
Is this ready for real use?
For PDFs, yes, it works well. For images, not quite yet. You can still use the model and make small adjustments to the output to get what you need.
Use it, but double-check
Large language models are great for speeding up tasks, but don’t trust them blindly. They can make mistakes such as missing duplicate charges or mislabeling expenses. When that happens, try refining your prompt or correcting the output manually.
Summary and next steps
You don’t need to write any code to build a working expense report prototype—just a natural language prompt and some receipts.
Using JSON for structure and LLMs for extraction is a strong combo. Just remember to keep a human in the loop to review results.
This simple test showed that LLMs can handle real business tasks with minimal setup. Want to go further? IBM Cloud has tools to help you build, deploy, and scale AI solutions. Explore more at IBM Cloud Catalog.