About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
The data services underlying IBM watsonx
A data fabric approach for defining, organizing, managing, and delivering trusted data to train and tune AI models
Powerful AI models start with training data that is high quality and that is, more importantly, accessible. Thus, organizations seeking to be "AI first" must also be "data first." IBM’s data services, underlying IBM watsonx and a foundational layer IBM's generative AI tech stack, are engineered to deliver data at speed and scale across the enterprise.
Data has the potential to be a core differentiator in driving growth and transformation for an organization's business processeses. Both a data strategy and a robust data architecture are necessary to make the most of an organization's data. Managing multiple complex data stores often leads to data silos, which are groups of data that are not easily accessed across the organization. Cumbersome access procedures to organizational data all but ensure that their full potential are never unlocked. A modern architectural approach to data like data fabric is the tool modern organizations rely on to shape and transform a data-first enterprise.
Data fabric
Data fabric is an architectural approach that pulls data together from various systems, including data lakes, warehouses, SQL databases and apps to equip organizations with a hollistic view of and comprehensive access to their data. This data fabric approach enables access to data wherever it lives in a hybrid-cloud environment, whether it is on-premises, in multiple clouds, or both.

Learn more about the data fabric architectural approach.
IBM Data Services
IBM’s data services layer is driven by 4 core services that deliver the key functionalities of a data fabric architecture:
- Platform connections to data sources
- Extract, Transform, Load capability
- Synthetic Data Generation
- Data Processing & Refinement
Platform Connections
Within watsonx, different data assets such as databases, cloud object storage buckets, query engines, and data catalogs are organized into platform catalogs. These catalogs house connectors to access the various data sources:
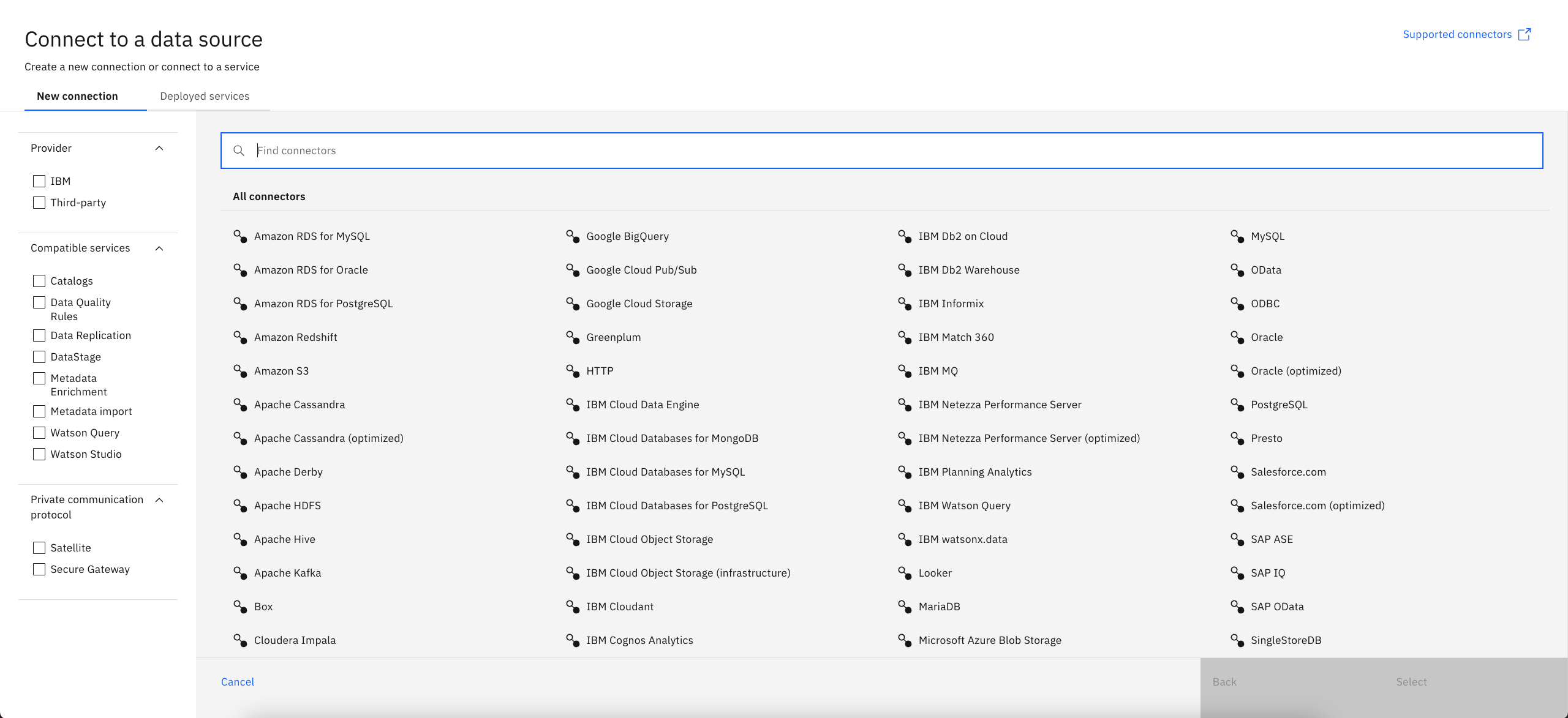
After you select an asset to add to a catalog, you will be prompted to enter necessary credentials to create a permanent platform connection. These assets can then be added to IBM watsonx or Cloud Pak for Data projects, and data can be simply queried using the connectors, or virtualized with Watson Query. Connections address the challenges of siloed data sources by unifying data from multiple sources into a single platform, enabling real-time data analysis and insights.
Extract, Transform, Load
Extract, Transform, Load (ETL) is a process of combining and harmonizing data from multiple sources into a single, consistent data set for loading into a target system for various analytical, operational, and decision-making purposes. Frequently, insights are needed from data that are stored in multiple sources.
ETL starts with copying or exporting data from a source location into a staging area. Then the data is processed for its intended analysis through data cleansing and transformation. Finally, once the data is in it’s desired form, the data is loaded into a target source for analysis and business intelligence.
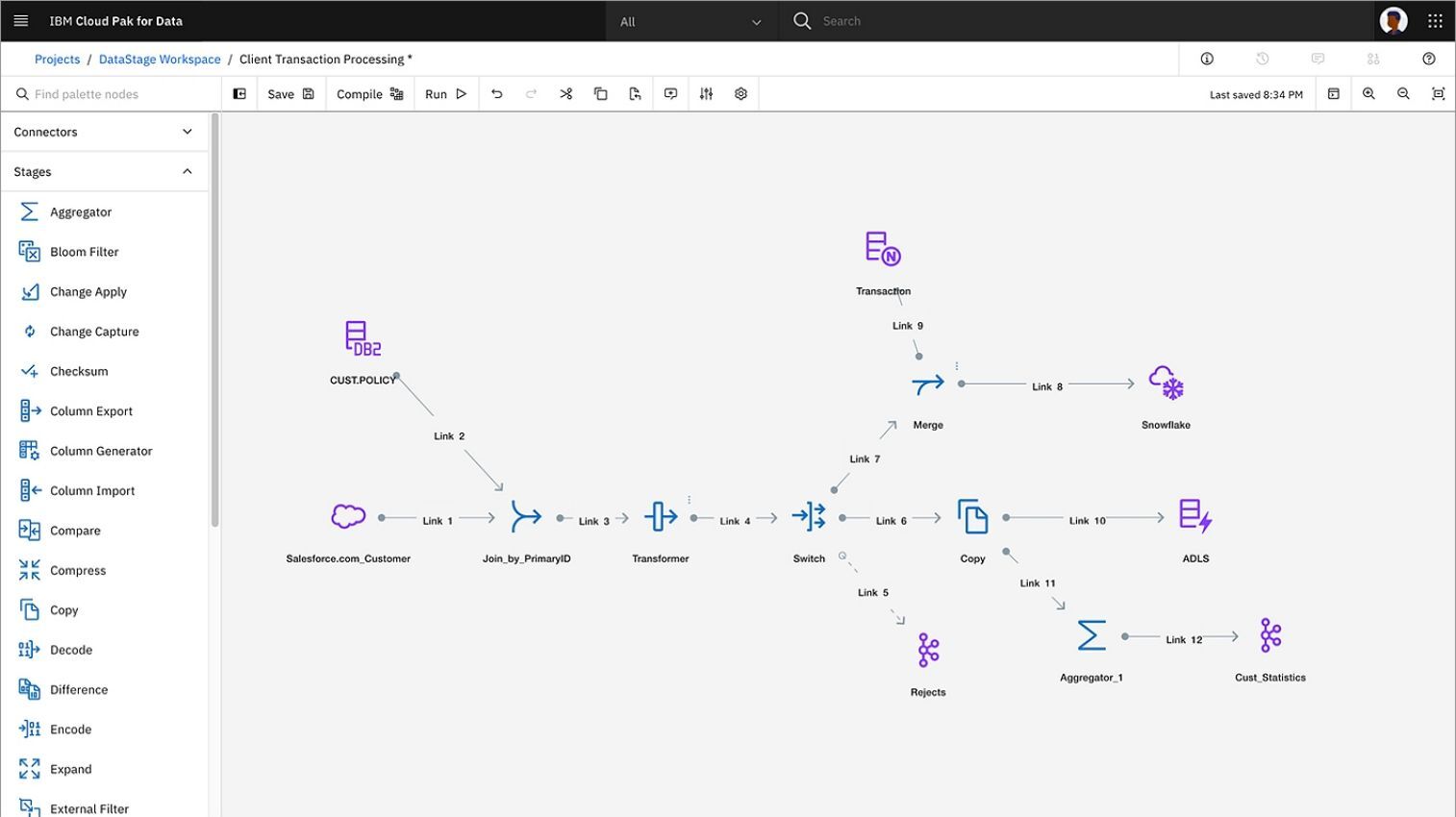
IBM DataStage is IBM’s data integration tool which helps you to design, develop, and execute jobs in order to move and transform data. Using a graphical interface in DataStage, you can design data flows that support the processes of ETL. DataStage is compatable with a myriad of IBM & third party data sources and can load data directly into an IBM watsonx.data data lakehouse.
Synthetic Data Generator
Synthetic data is data based off of real data sets but artificially generated through computer simulations or algorithms. Synthetic data is important because it can aid with research, testing, and development when there is a limited amount of real data. In industries like healthcare or finance where data privacy is important, synthetic data can help ensure compliance with regulations and organizational politices. Synthetic data is also commonly used to generate data sets for training large language models. (Read more about this on the IBM Research Blog.)
In IBM Cloud Pak for Data and IBM watsonx, the Synthetic Data Generator is a graphical flow tool that you can use to generate synthetic tabular data based on either imported data, production data, or a custom schema. Learn more about generating synthetic tabular data in the documentation.
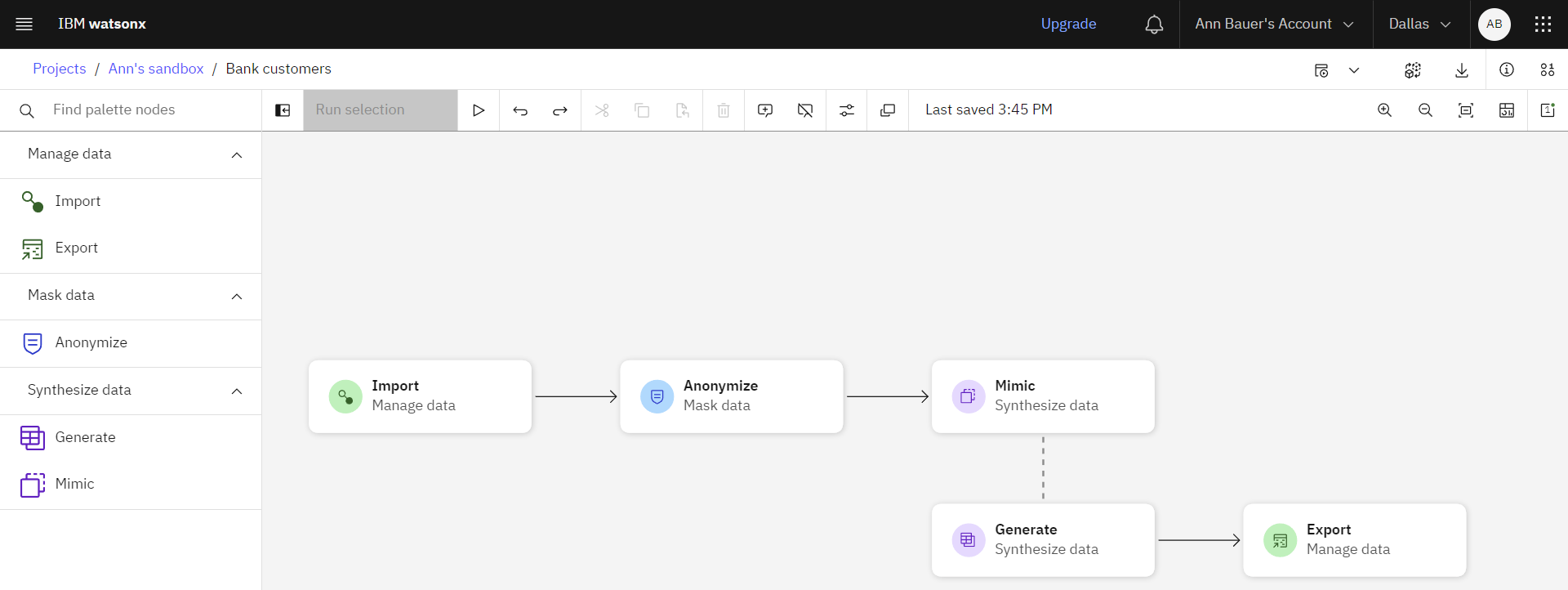
This no-code solution for synthetic data generation makes it simple for organizations to get reliable and usable datasets that can ultimately be used to accelerate the process of data-driven decision making.
Data Refinery
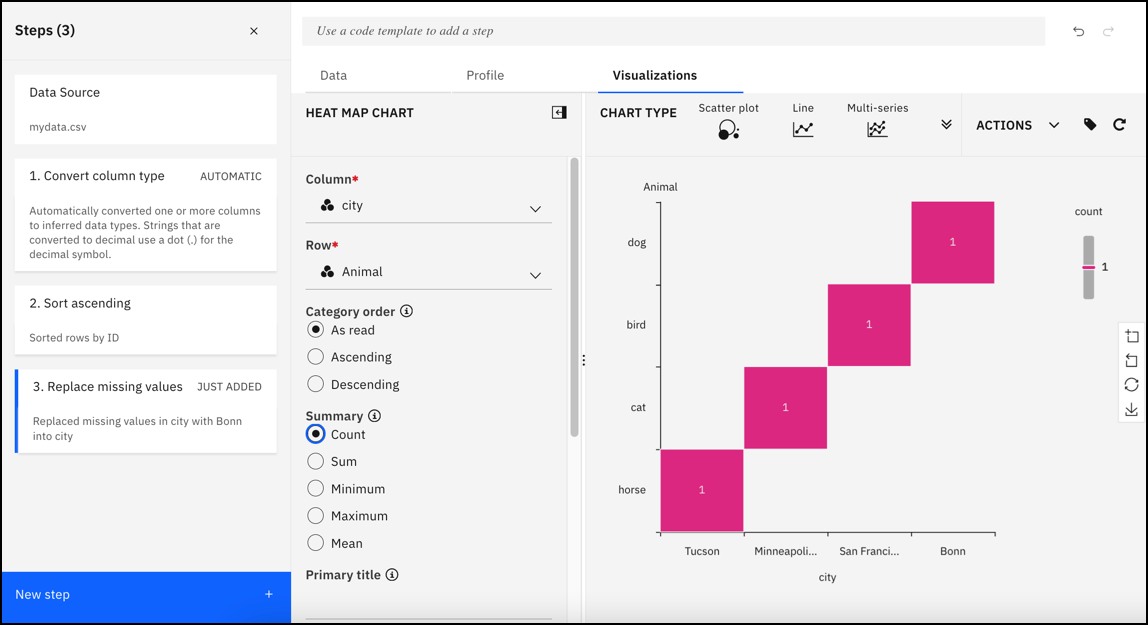
Data refinery is a tool offered in IBM watsonx.ai and IBM Knowledge Catalog. Its function is to simplfy data transformation, by cleaning and processing raw data before it is used for analytics.
This is acomplished through over 100 out-of-the-box operations for data cleansing and reshaping. The tool also provides visual representations of your data’s quality and distribution with charts and graphs. This is extremely helpful for performing quick Exploratory Data Analysis for Machine Learning without the need for code.
Summary and next steps
As you can see, data services form the foundation for a strong data frabric approach to managing enterprise data. These capabilities are provided through the different data services tools offered in watsonx and Cloud Pak for Data, including platform conncetions, ETL, synthetic data generation, and data refinery. Learn more about how IBM watsonx can help your organization become AI first.
Learn more about watsonx and IBM's generative AI tech stack
Now that you've learned all about the IBM data services, learn more about IBM's portfolio of AI products, watsonx, which is the foundation for the generative AI tech stack.
Try watsonx.data -- IBM's data lakehouse. Try watsonx.ai -- next-generation studio for AI builders.
Explore more articles and tutorials about watsonx on IBM Developer.