

Retrieval augmented generation — a search problem
Search is critical infrastructure for working with large language models (LLMs) to build the best generative AI experiences. You get one chance to prompt an LLM to deliver the right answer with your data, so relevance is essential. Ground your LLMs with retrieval augmented generation (RAG) using Elastic.
Try out this self-paced hands-on learning to learn how to build a RAG application.
Try hands-on learningBuild RAG into your apps, and try different LLMs with a vector database.
Discover more on Elasticsearch labsLearn about how to build advanced RAG-based applications using the Elasticsearch Relevance Engine™.
See quick start videoThe Elastic advantage
Production ready for enterprise scale



TRUSTED BY THE FORTUNE 500 TO drive GENERATIVE AI INNOVATION





Make your data ready for RAG
RAG extends the power of LLMs by accessing relevant proprietary data without retraining. When using RAG with Elastic, you benefit from:
- Cutting-edge search techniques
- Easy model selection and the ability to swap models effortlessly
- Secure document and role-based access to ensure your data stays protected
Transform search experiences
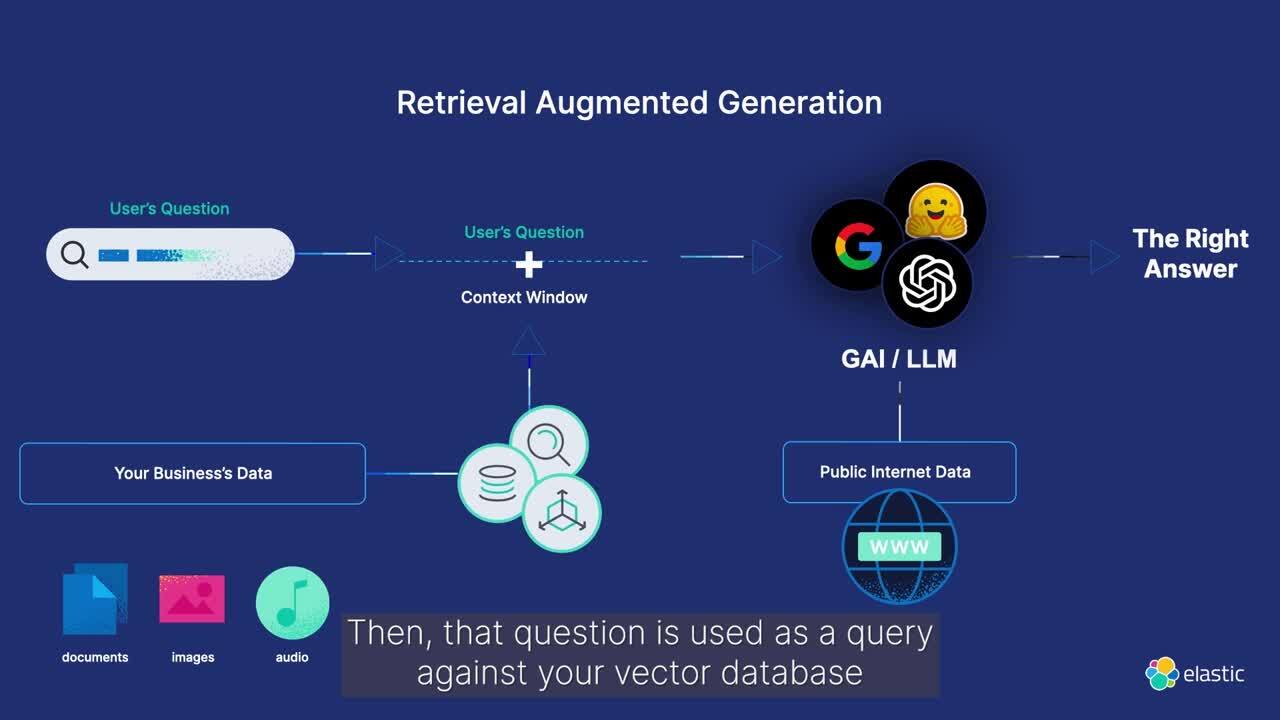
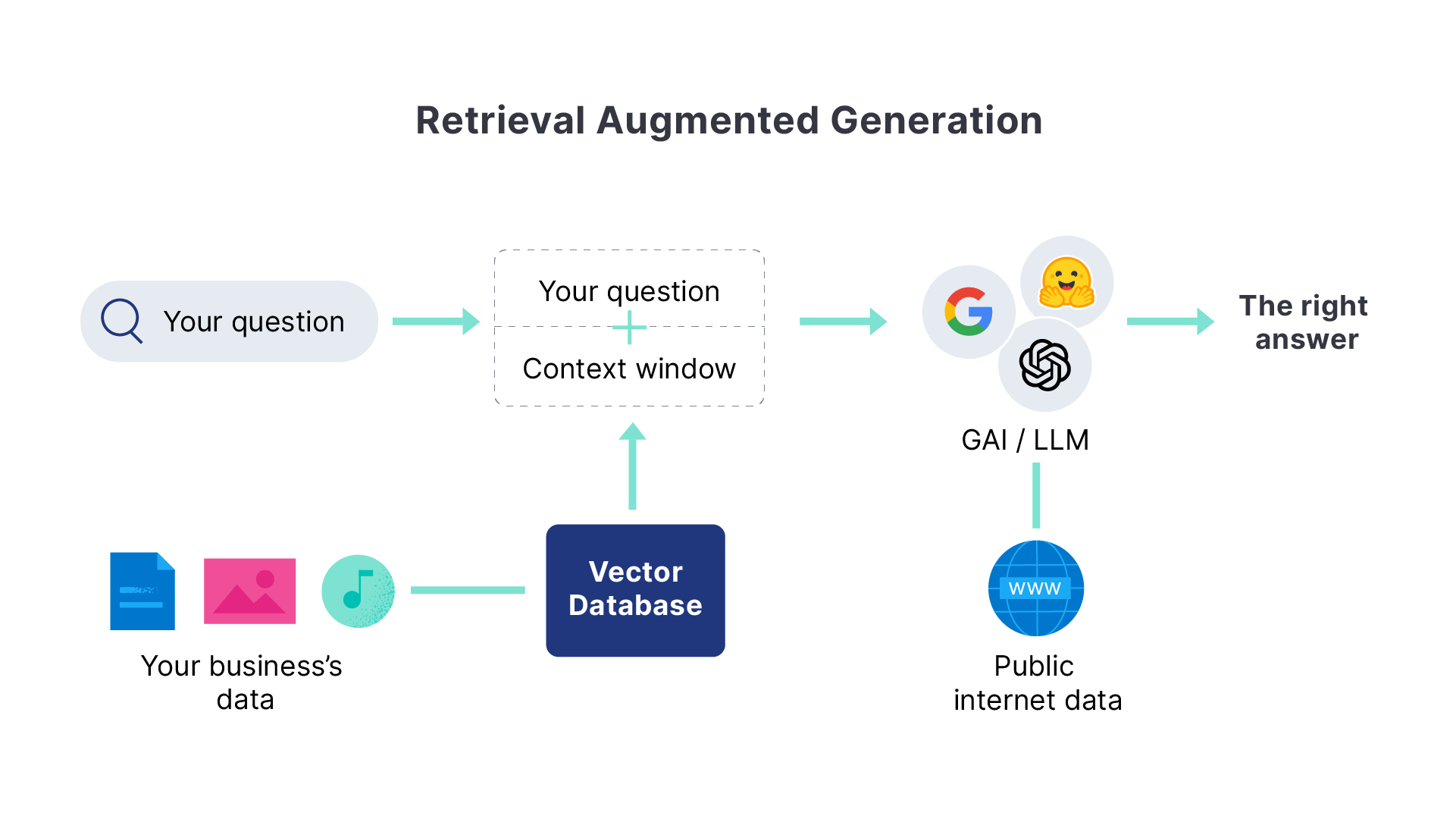
What is retrieval augmented generation?
Retrieval augmented generation (RAG) is a pattern that enhances text generation by integrating relevant information from proprietary data sources. By supplying domain-specific context to the generative model, RAG improves the accuracy and relevance of the generated text responses.
Use Elasticsearch for high relevance context windows that draw on your proprietary data to improve LLM output and deliver the information in a secure and efficient conversational experience.
HOW RAG WORKS WITH ELASTIC
Enhance your RAG workflows with Elasticsearch
Discover how using Elastic for RAG workflows enhances generative AI experiences. Easily sync to real-time information using proprietary data sources to get the best, most relevant generative AI responses.
The machine learning inference pipeline uses Elasticsearch ingest processors to extract embeddings efficiently. Seamlessly combining text (BM25 match) and vector (kNN) searches, it retrieves top-scoring documents for context-aware response generation.
USE CASE
Q&A service that runs on your private data set
Implement Q&A experiences using RAG, powered by Elasticsearch as a vector database.

Elasticsearch — the most widely deployed vector database
AI Search — in action
Customer spotlight

Consensus upgrades academic research platform with advanced semantic search and AI tools from Elastic.
Customer spotlight

Cisco creates AI-powered search experiences with Elastic on Google Cloud.
Customer spotlight

Georgia State University increases data insights and explores helping students apply for financial aid with AI‑powered search.
Frequently asked questions
Retrieval augmented generation (commonly referred to as RAG) is a natural language processing pattern that enables enterprises to search proprietary data sources and provide context that grounds large language models. This allows for more accurate, real-time responses in generative AI applications.
When implemented optimally, RAG provides secure access to relevant, domain-specific proprietary data in real time. It can reduce the incidence of hallucination in generative AI applications and increase the precision of responses.
RAG is a complex technique that relies on:
- The quality of data fed into it
- The effectiveness of search retrieval
- Data security
- The ability to cite the sources of generative AI responses in order to fine tune the results
In addition, choosing the right generative AI or large language model (LLM) in a fast moving ecosystem can pose challenges for organizations. And the costs, performance, and scalability associated with RAG can hinder the speed at which enterprises launch applications into production.
Elasticsearch is a flexible AI platform and vector database that can index and store structured and unstructured data from any source. It provides efficient and customizable information retrieval and automatic vectorization across billions of documents. And it offers enterprise security with role and document-level access control. Elastic also provides a standard interface for accessing innovations across an expanding GenAI ecosystem, including hyperscalers, model repositories, and frameworks. Finally, Elastic is proven in production-scale environments, serving over 50% of the Fortune 500. Explore how to build RAG systems in Elastic with Playground.
Elastic provides cross-cluster search (CCS) and cross-cluster replication (CCR) to help you manage and secure data across private, on-prem, and cloud environments. With CCS and CCR, you can:
- Ensure high availability
- Maintain compliance with global data protection regulations
- Achieve data privacy and sovereignty
- Build an effective disaster recovery strategy
Elastic also offers role-based and document-level access control that authorizes customers and employees to only receive responses with data they have access to. And our users can gain insights from comprehensive observability and monitoring for any deployment.

