Accelerating generative AI experiences
Search powered AI and developer tools built for speed and scale


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Daily breakthroughs in large language models (LLMs) and generative AI have put developers at the forefront of the movement, influencing its direction and possibilities. In this blog, I’ll share how Elastic's search customers are using Elastic's vector database and open platform for search powered AI and developer tools to accelerate and scale generative AI experiences, giving them new avenues for growth.
Results from a recent developer survey conducted by Dimensional Research and supported by Elastic indicate that 87% of developers already have a use case for generative AI — whether it’s data analysis, customer support, workplace search, or chatbots. But only 11% have successfully implemented these use cases into production environments.
There are several factors getting in their way:
Model deployment and management: Choosing the right model requires experimentation and rapid iteration. Deploying LLMs for generative AI applications is time-consuming and complex with a steep learning curve for many organizations.
Legal and compliance concerns: These concerns are especially important when dealing with sensitive data and can be a barrier to model adoption.
- Scaling: Domain specific data is crucial for LLMs to understand context and generate accurate outputs. Retrieving that as your data scales requires equally scalable support for the workloads that generate vector embeddings, increasing the demand for memory and computational resources rapidly. With vast data sets, context windows are large and costly to pass to an LLM, and more context does not necessarily mean more relevance. Only a robust platform of tools can shape the context and balance the tradeoffs between relevance and scale to achieve a viable future proof architecture for innovation.
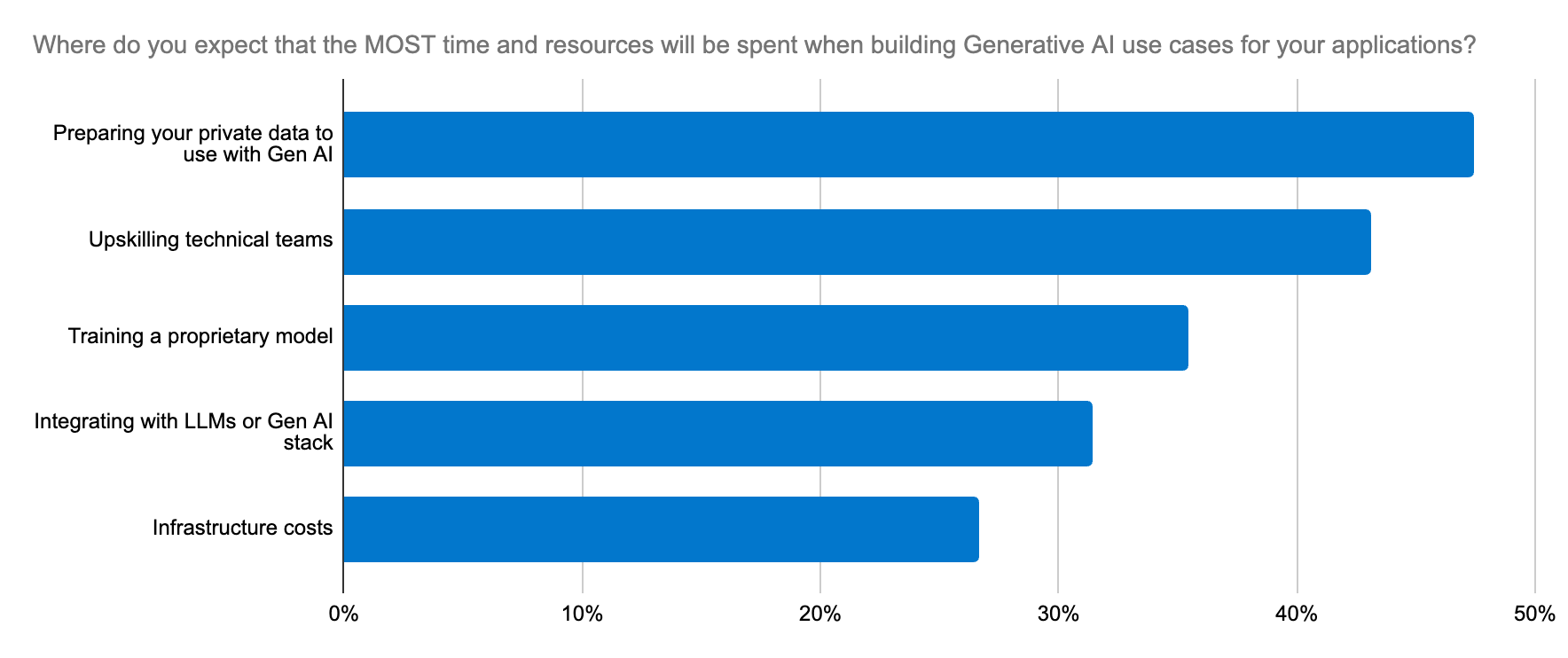
Developers seek a reliable, scalable, and cost-effective way to build generative AI applications and a platform that simplifies implementation and the LLM selection process.
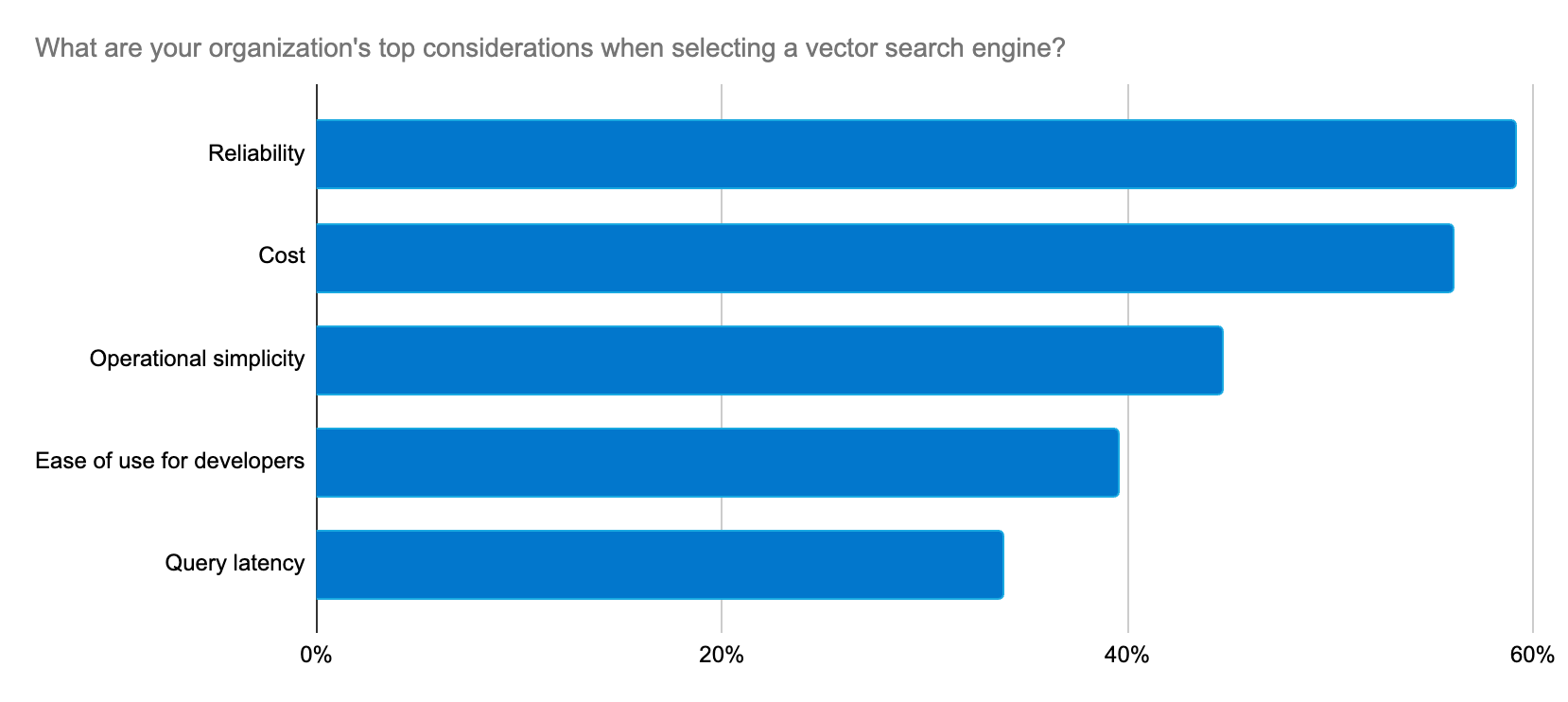
Elastic is consistently delivering solutions to these developer concerns with a rapid pace of innovation to support generative AI use cases.
Roll out generative AI experiences fast and at scale
Elasticsearch is the most downloaded vector database in the market, and Elastic’s deep association with the lucene community has enabled us to design and deliver search innovations to our customers faster. Elasticsearch is now powered by lucene 9.10, helping customers achieve speed and scale with generative AI. With 9.10, among other speed boosts, users are seeing significant query latency improvements on multi-segment indices. And that’s just the start, there’s more speed to come.
We’re using Elastic as a vector database because of its inherent flexibility, scalability, and reliability. Elastic continually elevates the game by rapidly delivering new features that support Machine Learning and generative AI.
Peter O'Connor, Engineering Manager of Platform Engineering, Stack Overflow
To quickly implement and scale RAG workloads, the Elastic Learned Sparse EncodeR (ELSER) — generally available — is an easy to deploy, optimized, late interaction machine learning (ML) model for semantic search. ELSER delivers contextually relevant search results without requiring fine tuning and offers developers a built-in trusted solution, saving you the time and complexity of model selection, deployment, and management.
ELSER elevates search relevance without a cost to speed — when Consensus upgraded its academic research platform powered by Elastic, using ELSER, it cut search latency by 75% with improved accuracy.
When you pair ELSER with the E5 embedding model, you can easily apply multilingual vector search. Our optimized artifact of E5 is tailored specifically for Elasticsearch deployments. Multilingual search is also available by uploading multilingual models or integrating with Elastic’s Inference API (for example, Cohere's multilingual model embeddings). These advancements accelerate retrieval augmented generation (RAG) further, making Elastic critical infrastructure for scaling the innovative generative AI experiences you build.
Elastic is also focused on scaling these experiences efficiently. Scalar quantization, which came with our 8.12 release, is a game-changer for vector storage. Large vector expansions can lead to slower searches. But this compression technique dramatically slashes memory requirements by fourfold and helps pack in more vectors, and at higher scales, has a negligible impact on recall. It doubles vector search speeds used in RAG without sacrificing accuracy. The result? A leaner, faster system that trims infrastructure costs at scale.
Search is critical for elevating Udemy’s user experience — matching users to relevant educational content, which is why Elastic has been a long-term partner of ours. We’ve used Elastic as our vector database since upgrading to Elastic Cloud last year, and it has opened up new opportunities for our business. We’ve seen increased query speed and resource efficiency as we’ve scaled vector search across our innovative education solutions.
Software Engineering Team, Udemy
The most relevant search engine for RAG
Relevance is the key to the best generative AI experiences. Using ELSER for semantic search and BM25 for textual search are excellent first steps for retrieving relevant documents as context for LLMs. Large context windows can be further refined using reranking tools that are now part of the Elastic Stack. Rerankers apply powerful ML models to fine-tune your search results and bring the most relevant results to the top based on user preferences and signals. Learning to Rank (LTR) is also now native to the Elasticsearch Platform. This is powerful for RAG use cases, which rely on feeding the most relevant results to an LLM as context.
Implementation is further simplified through the Inference API and third-party providers like Cohere. Upgrade to our latest release to test the impact that rerankers can have on relevance.
These approaches not only enhance search accuracy (by 30%, in the case of Consensus), but also help you achieve quick results, refining relevance for RAG and efficiently managing ML workstreams.
Making model selection and swapping simple
Model selection can feel like searching for a needle in a haystack. In fact, our developer survey highlighted that one of the top five generative AI efforts across organizations is integrating with LLMs. This dilemma goes beyond choosing open versus closed source LLMs for a use case — it extends to accuracy, data security, domain-specificity, and quickly adapting to the changing LLM ecosystem. Developers need a straightforward workflow for trying new models and swapping them in and out.
Elastic supports transformer and foundational models through its open platform, vector database, and search engine. Elastic Learned Sparse EncodeR (ELSER) is a reliable starting point for accelerating RAG implementations.
Additionally, Elastic’s Inference API streamlines code and multi-cloud inference management for developers. Whether you use ELSER or embeddings from OpenAI (the most evaluated and used model among developers), Hugging Face, Cohere, or others for RAG workloads, one API call ensures clean code for managing hybrid inference deployment. With the Inference API, a wide range of models is easily accessible, so you can find the right fit. Easy integration with domain-specific natural language processing (NLP) and generative AI models streamlines model management, freeing up your time to focus on AI innovation.
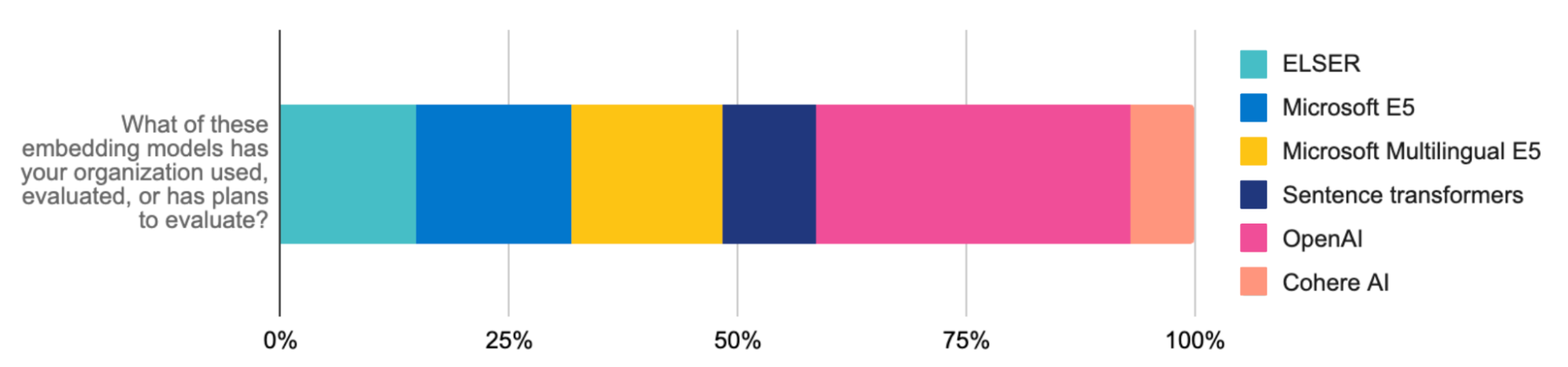
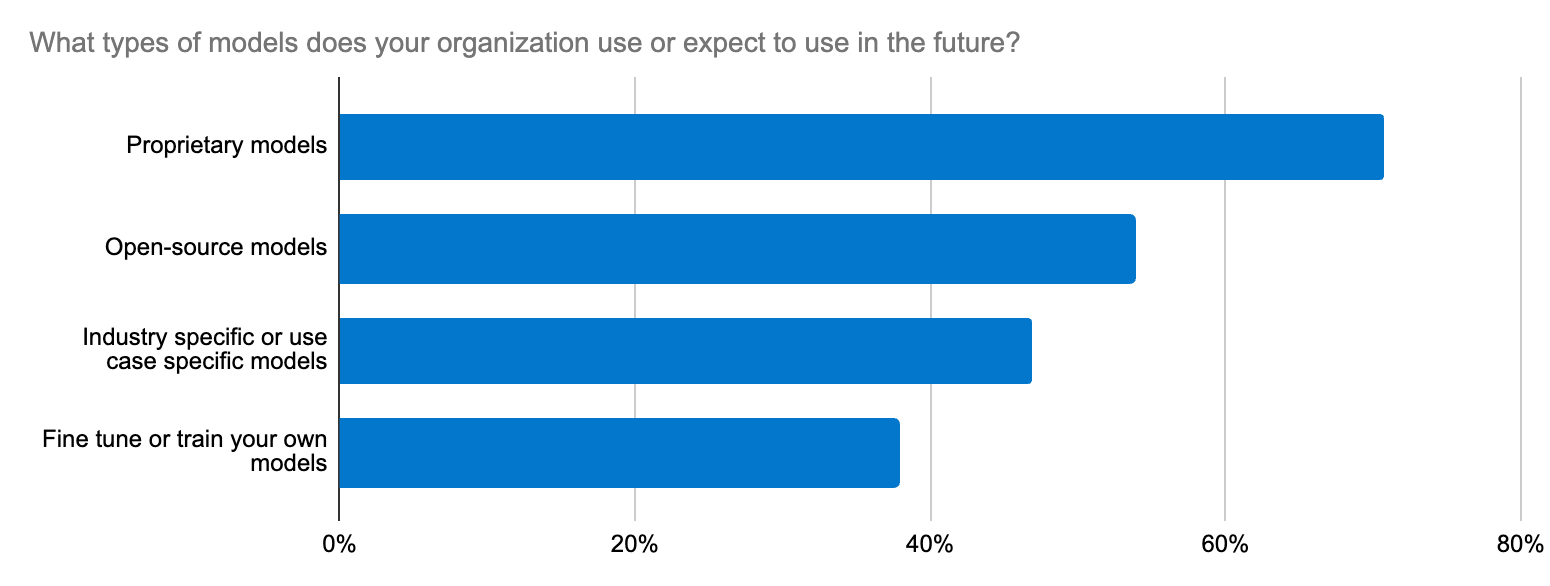
Stronger together: A great experience with integrations
Developers can also host diverse transformer models, including public and private Hugging Face models. While Elasticsearch serves as a versatile vector database for the entire ecosystem, developers who prefer tools like LangChain and LlamaIndex can use our integrations to quickly spin up production-ready generative AI apps using LangChain Templates. Elastic's open platform sets you up to quickly adapt, experiment, and accelerate generative AI projects. Elastic was also recently added as a third party vector database for On Your Data, a new service to build conversational copilots. Another good example is Elastic’s collaboration with the Cohere team behind the scenes to make Elastic a great vector database for Cohere embeddings.
Generative AI is reshaping every organization, and Elastic is here to support the transformation. For developers, the keys to successful generative AI implementations are continuous learning (have you seen Elastic Search Labs yet?) and rapidly adapting to the changing AI landscape.
When you combine the accuracy and speed of Elastic, and the power of Google Cloud, you can build a very stable and cost-efficient search platform that also delivers a delightful experience for the user.
Sujith Joseph, Principal Enterprise Search & Cloud Architect, Cisco Systems
Try it out!
- Read about these capabilities and more in the Elastic Search release notes.
- Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not using Elastic Cloud? Start a free trial.
- Try the Elasticsearch Relevance Engine, our suite of developer tools for building AI search apps.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

