About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Blog Post
How to run AI inferencing on IBM Power10 leveraging MMA
Six real-world scenarios that demonstrate the ease of use and benefits of using Power10 MMA for AI inferencing
As the world is set to deploy AI everywhere, attention is turning from how to quickly and accurately build and train AI models to how to rapidly implement those models, make inferences, and gain insights. IBM systems can help accelerate these implementations by running AI "in place" with four new Matrix Math Accelerator (MMA) units in each Power10 core. MMAs provide an alternative to external accelerators, such as GPUs, and related device management, for executing statistical machine learning and inferencing (scoring) workloads. It reduces costs with data center footprint, infrastructure management and support, and leads to a greatly simplified solution stack for AI to enable the creation of a data fabric architecture. Leveraging data gravity on Power10 allows AI to execute during a database operation or concurrently with an application as you can see in the demos described in this blog, which is key for time-sensitive use cases such as fraud detection. This delivers fresh input data to AI faster and enhances the quality and speed of insight.
In this blog, we'll explain how to use the new MMA technology, show the container-based approach we used to define the demo framework, and demonstrate the value of the MMA technology in six real-world scenarios.
Intro to Power10 MMA
The Power10 Matrix Math Accelerator (MMA) is built for AI inferencing in the core to allow direct and inline acceleration. Libraries are optimized so that AI applications running Python using PyTorch and TensorFlow can take advantage of MMA. Models trained elsewhere, including ONNX formatted runtimes, can be loaded for inferencing as well.
Developer Setup – How to use MMA
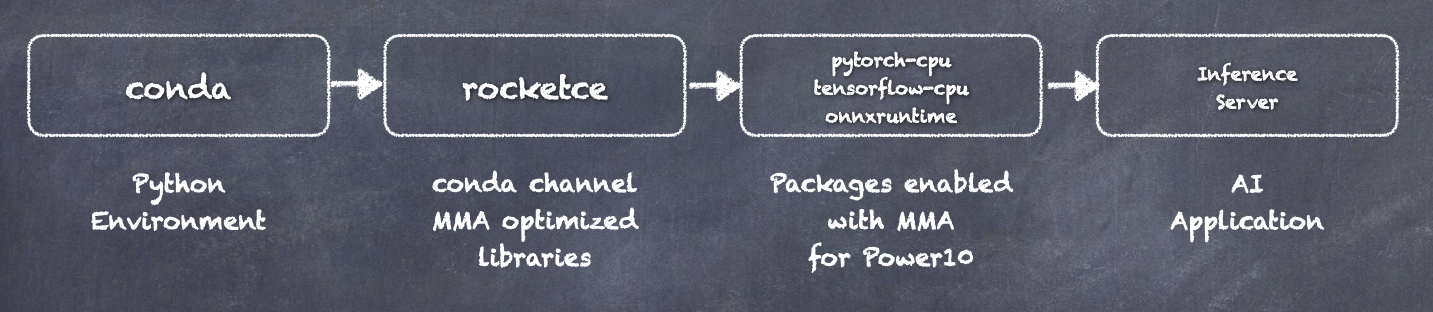
As a data scientist or developer, you may wonder how to run AI inferencing on MMA. It's straightforward and easy with Anaconda or other package management services. Applications runin Python environments, and using Anaconda work the same on Power by installing Conda packages from the RocketCE channel. Currently the MMA enhanced libraries are hosted in this Conda channel and work is underway to move them to the main channel. Figure 1 shows the workflow.
Figure 1. Python development environment
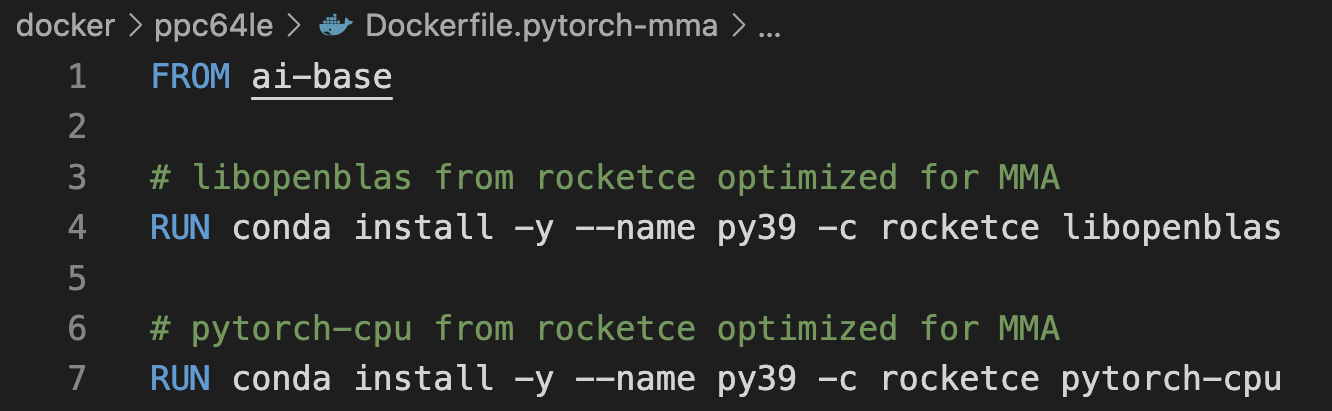
Most popular packages are already optimized and available on the Conda channel rocketce. Figure 3 shows an example Dockerfile that uses Conda to install pytorch-cpu by simply specifying the rocketce channel as the source.
Figure 2. Install from the RocketCE channel using Conda
For showcasing performance gains using MMA, we also ran the same inference app without MMA-optimized libraries as a comparison. Note that MMA is part of the system however applications may choose not to use the optimization. For a full list of up-to-date packages check https://anaconda.org/rocketce/ and see Figure 3 below for example.
Figure 3. Anaconda RocketCE packages
Demo framework overview
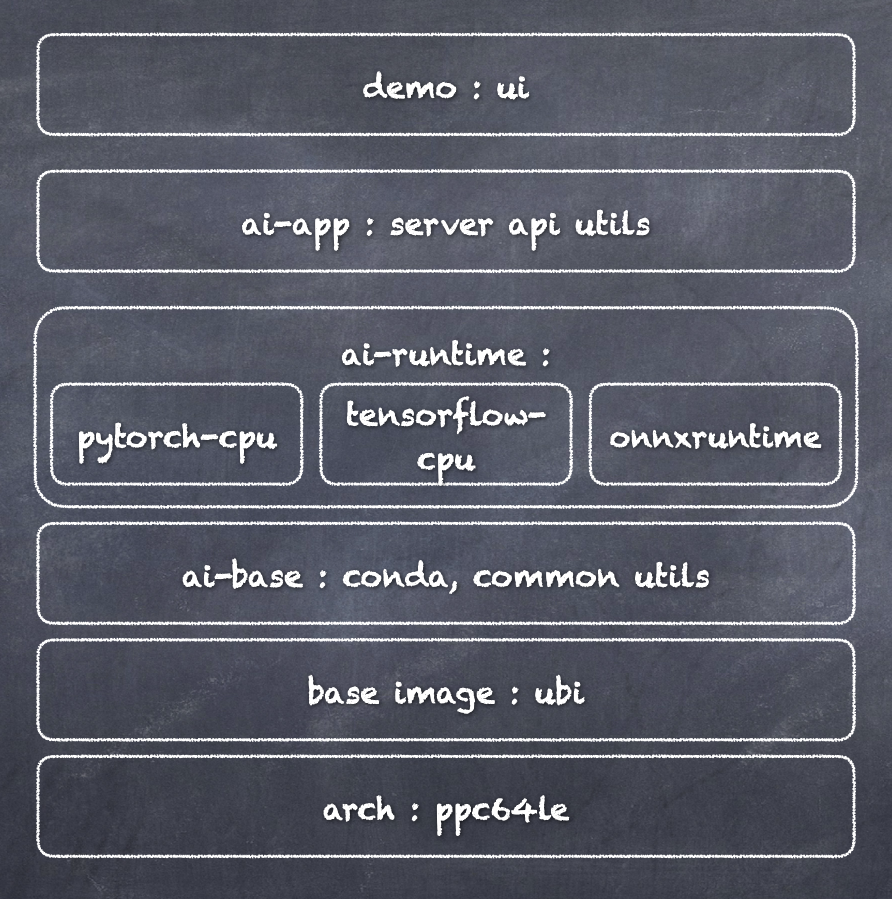
We built six demos using a demo framework that consists of a set of containers. The stacked containers offer flexibility in choosing AI frameworks and allows the inferencing applications to run on multiple architectures (Power, Z, x86 and ARM) and hosting environments. With a container-based approach, it is easy to set up a virtual Python environment which is typically required for data science work. In this case, we start with Red Hat Enterprise Linux (RHEL) universal base image (UBI), followed by adding the AI-base which consists of setting up Anaconda and creating a project space. The AI-framework layer installs specific AI libraries and dependencies, setting up the required environment for inferencing. To illustrate the performance advantage of MMA, we included a set of generic AI frameworks that are not optimized for MMA to compare to the ones that are optimized.
Figure 4 shows the demo framework architecture. The container-based approach makes it easy to plug in new demo applications and add AI frameworks. We have created a set of images for easy maintenance. For each platform, we have pre-installed AI frameworks and packages. We have also built a graphical user interface so users can select an AI framework for a demo on any platform/architecture.
Figure 4. Demo architecture framework
Images are stacked to build out the AI application. Each application consists of an inference server, APIs for communicating with the demo UI, utilities to query the system resources and runtime resource utilization, including number of vCPUs, available memory, and peak runtime memory. Figure 5 shows the demo UI architecture. It is also built using a modular approach. Common sections include application description, system resources, and performance results. The AI runtime settings area is customized based on the supported or implemented AI frameworks, for comparison of performance on using different frameworks with and without the libraries optimized for MMA. This allows us to add more frameworks as they are implemented. We will describe these in detail in the following demo specific sections.
Figure 5. Demo UI framework
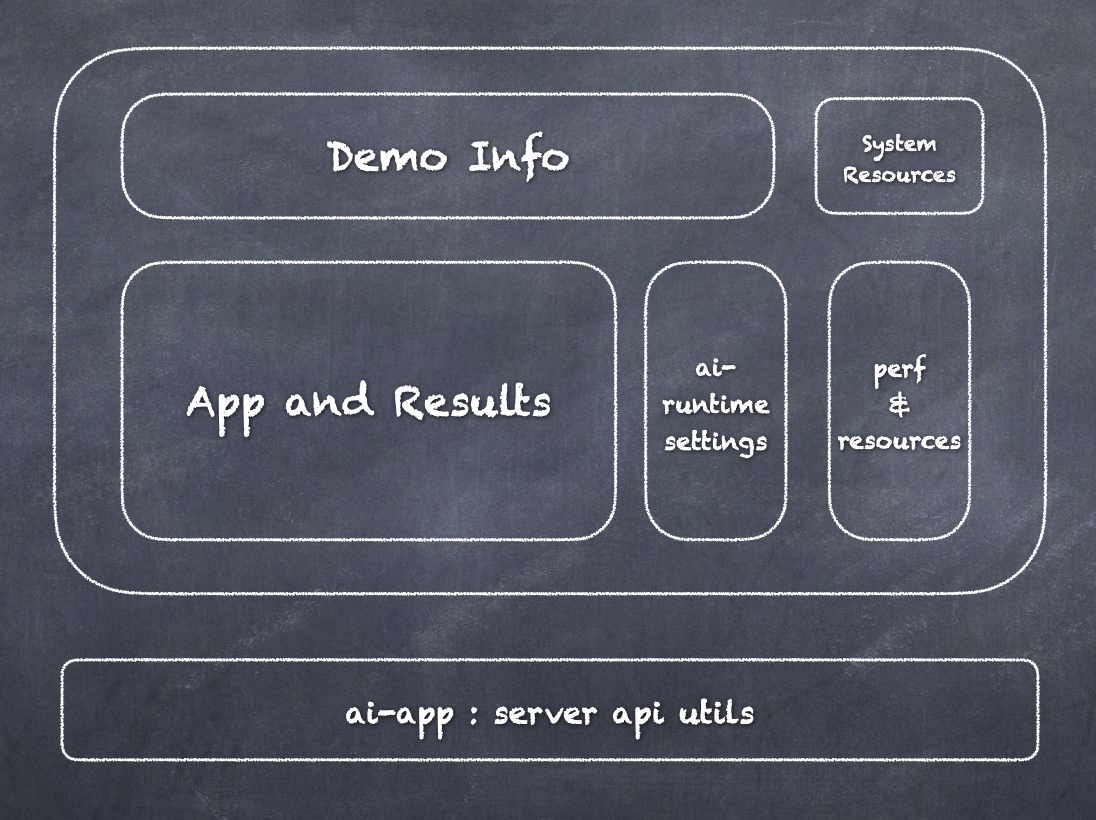
The demo framework is designed for the ease of adding new applications. The UI can automatically detect which applications are available and enable only those that are runnable, for example, as a new runtime is added, such as onnxruntime, it becomes available in the ai-runtime settings selection. The architecture is modular and easily adaptable. All the images used are also saved and served from our internal Artifactory registry so the entire demo suite can be active using a simple all-in-one install script.
Demos on Power10
We currently have six real-world scenarios which are described below. Note that five use cases are compute-bound and one is memory-intensive as well. For these demos, we used a Power10 LPAR with RHEL 8.6, 4 vCPUs and 15 GB memory, with the exception for the last demo focusing on a more memory intensive application.
Figure 6. Main demo UI

The main demo site consists of application tiles, each built to run standalone as shown in Figure 6. All the demos follow the same format with an overview of the application and the available system resources. Each demo consists of a main area that is customized to visualize the application and results. There are also runtime configurations which let the user select from available frameworks to gain an understanding of how the same model performs in different runtimes with and without leveraging MMA. Resource utilization is shown for each run of the inference. We will illustrate each of the demo use cases below.
Demo 1: Image detection
This image object detection use-case is currently being used by IBM Supply Chain for quality inspection of connector cage pins before installing the connector onto a server. This is an example of using AI for Inspection on the Edge. Each connector cage has 150 pins, and each pin is 0.12 square millimeter in size. For a human it is difficult, tedious, and time-consuming to inspect each cage, to detect whether pins are missing, broken, or bent. It typically takes 10 minutes per inspection for a trained technician. In this demo, we use AI to automate the inspection in Manufacturing and Industry 4.0. The Yolo3 model was trained on IBM Maximo Visual Inspection running on the IBM Cloud. As shown in Figure 7, the inferencing can be done with either PyTorch or ONNX runtime, with and without leveraging MMA. Our results show that there is about 3x performance with MMA using PyTorch or ONNX. Other image detection applications include security, surveillance, automated vehicle systems and medical imagining.
Figure 7. Example output and performance for the image detection demo

Demo 2: Action Recognition
This is a video action-recognition scenario, which has applications in security and safety, smart homes, sports, elderly behavior monitoring, and human-computer interaction. This model was developed and refined by the MIT-IBM Watson AI lab. With this demo, we show how to quickly turn a research asset, such as a new AI model into a demo of AI inferencing on Power10. The model was trained on an internal GPU cluster on IBM Cloud. Again, for each example, MMA speeds up the inferencing by 3x. The output and performance for running PyTorch with MMA is shown in Figure 8. The model recognizes that the action in the video is canoeing, and the inferencing takes 10 seconds utilizing all four vCPUs.
Figure 8. Example inference results for action recognition

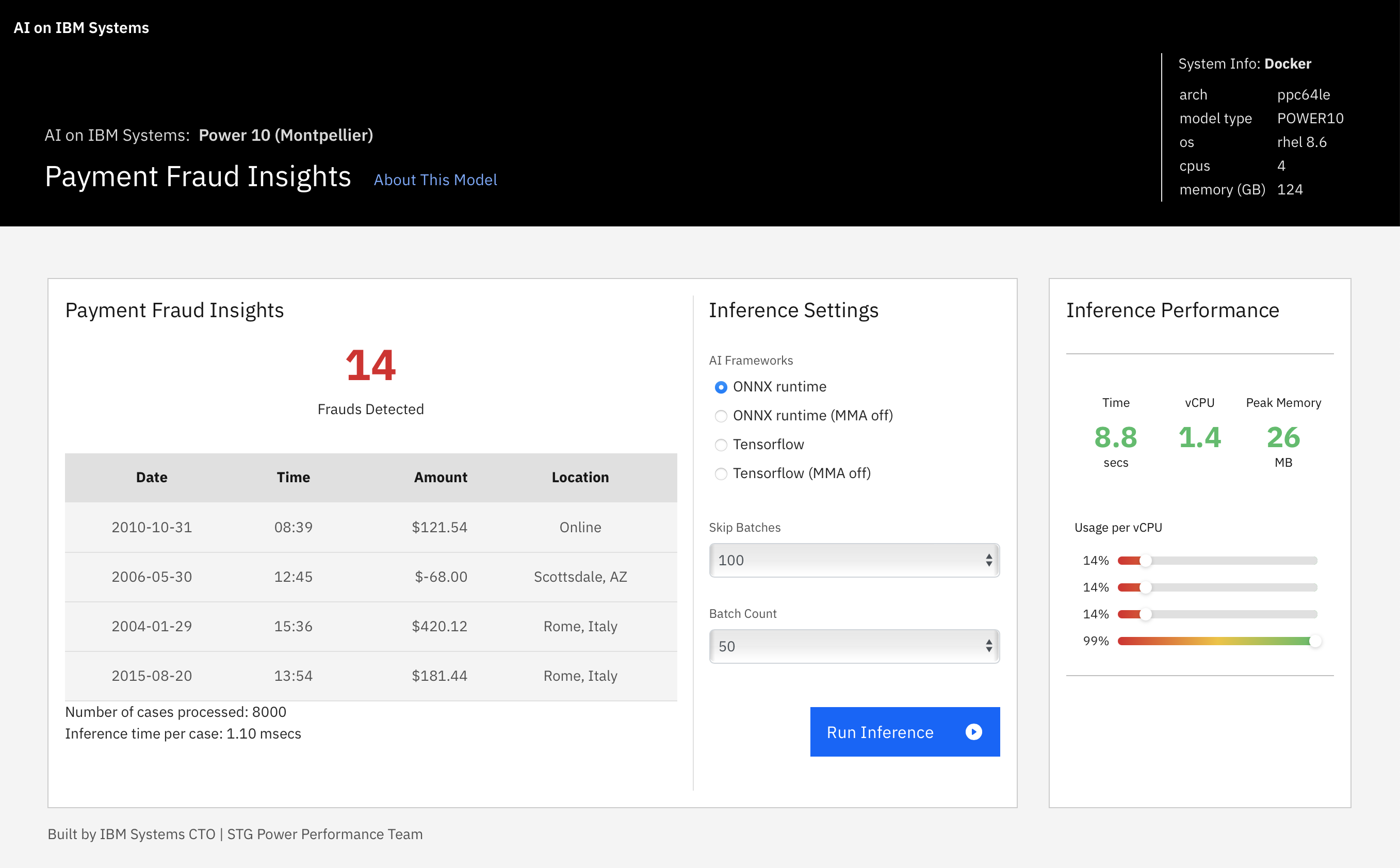
Demo 3: Credit Card Fraud Detection
As the cost of a data breach in financial services increases year over year, it is highly desirable to use AI to identify fraud in a secure, low latency, and high throughput fashion. The intent here is to use AI in line with the transaction or directly within a database where the data resides. For example, credit card transaction data are kept in database tables in IBM Db2, and the inferencing is done as part of the SQL query via User Defined Functions (UDFs). For this demo, however, we are running the data, model, and inferencing standalone outside of Db2 to showcase the inferencing power of MMA. The runtime comparisons are done with and without leveraging MMA for different AI frameworks, namely, TensorFlow and ONNX runtime, as shown in Figure 9. We will report the results for running Db2 UDF in memory in a future blog.
Figure 9. Example output and performance for payment fraud detection demo
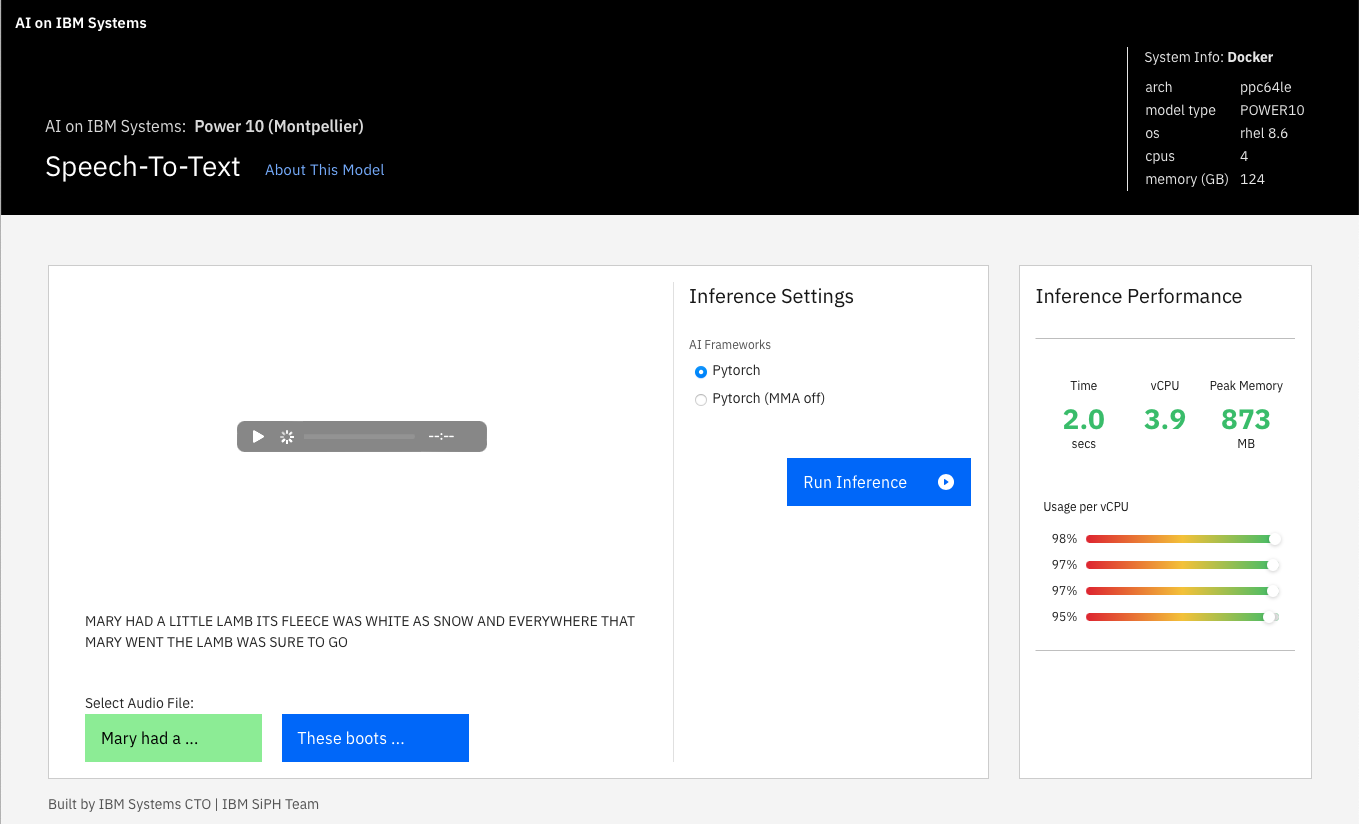
Demo 4: Speech to Text (STT)
The STT demo uses Automatic Speech Recognition or Speech To Text built upon the public "Hugging Face" model. There are many applications for transcribing audio to text. For example, a hospital in Southeast Asia currently uses a traditional pathology system that is inefficient, lacks data linkage and integration, and has long patient response times of 2-4 weeks. As part of the overall Digital Pathology solution, only STT is demonstrated here. Other parts involving image recognition are already covered in demo 1. Using STT they can instantly transcribe patient information and have the data/results available almost immediately. Inference is done using an audio file either real-time recorded or pre-loaded, using the pretrained model "wav2vec2-large-960h-lv60-self" standalone. Output is the transcribed text. Figure 10 shows how a pre-recorded audio file can be used to demonstrate the speech to text feature. In this example, PyTorch is used, and the inference takes 2 seconds.
Figure 10. Example output and performance for Speech to Text
Demo 5: Time series forecasting (stock price prediction)
Time series forecasting models can be used for weather forecast and stock price prediction. Although real use cases would be much more complicated, this demo shows the art of the possible. Here we use the Long Short Term Memory (LSTM) machine learning model and real stock price data for a given company over a period of time. Model was trained with Tensorflow and Keras but we focus on the inferencing in this demo.
Figure 11. Example output and performance for Time Series Forecasting
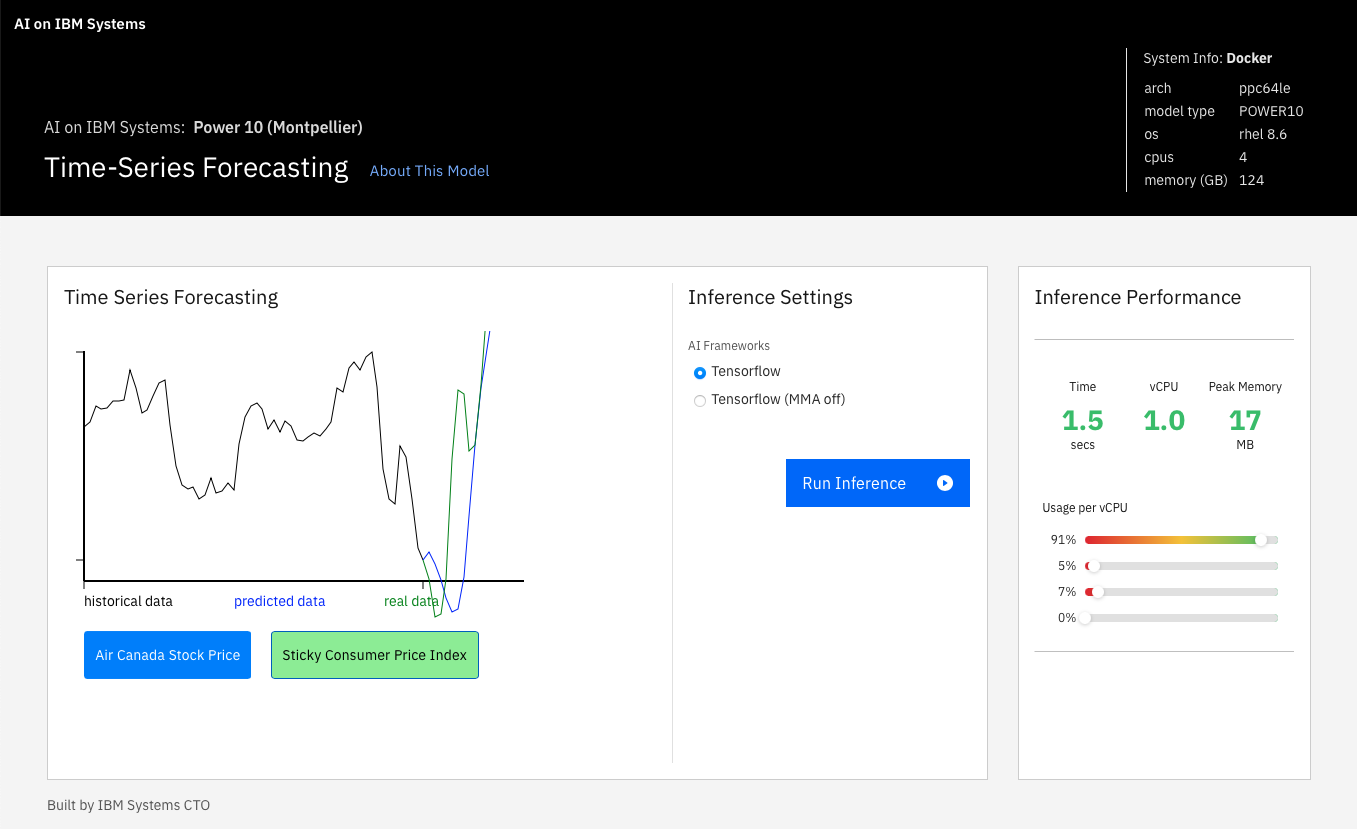
LSTM's are able to store information over a period of time and are extremely useful when we deal with Time-Series or Sequential Data. The two sample datasets used in the demo are the Air Canada stock-price in Q4 2018, and the consumer price index from the Federal Reserve Economic Data (FRED), which is an indicator for inflation.
[Reference: https://ai.plainenglish.io/time-series-forecasting-predicting-stock-prices-using-an-lstm-model-30d6f1ca2640]
Demo 6: CERN neutrino interaction denoising
To further demonstrate Power10 compute capability, a large memory model is used to show that inferencing is faster with no need of splitting the input image into smaller sizes. A prototype Single Phase (SP) detector has been built for the CERN Neutrino Platform to perform experiments in the neutrino oscillation research field. The platform measures particle interactions in liquid Argon, which produce ionization electrons that are drifted towards 6 Anode Plane Assemblies (APAs), each with 960 wires in its collection plane. The raw measurements are cast into a 6000×960 resolution image plotting an Analog-to-Digital Converter values heat map over time versus wire number. This application tackles the denoising of these images, which are sparse and large, requiring careful memory management, while dealing with complex model architectures. This Graph-CNN model outperforms the original denoising algorithm that was developed for these kind of images.
[Reference: https://link.springer.com/article/10.1007/s41781-021-00077-9]
Figure 12. Example output and performance for CERN neutrino interaction denoising
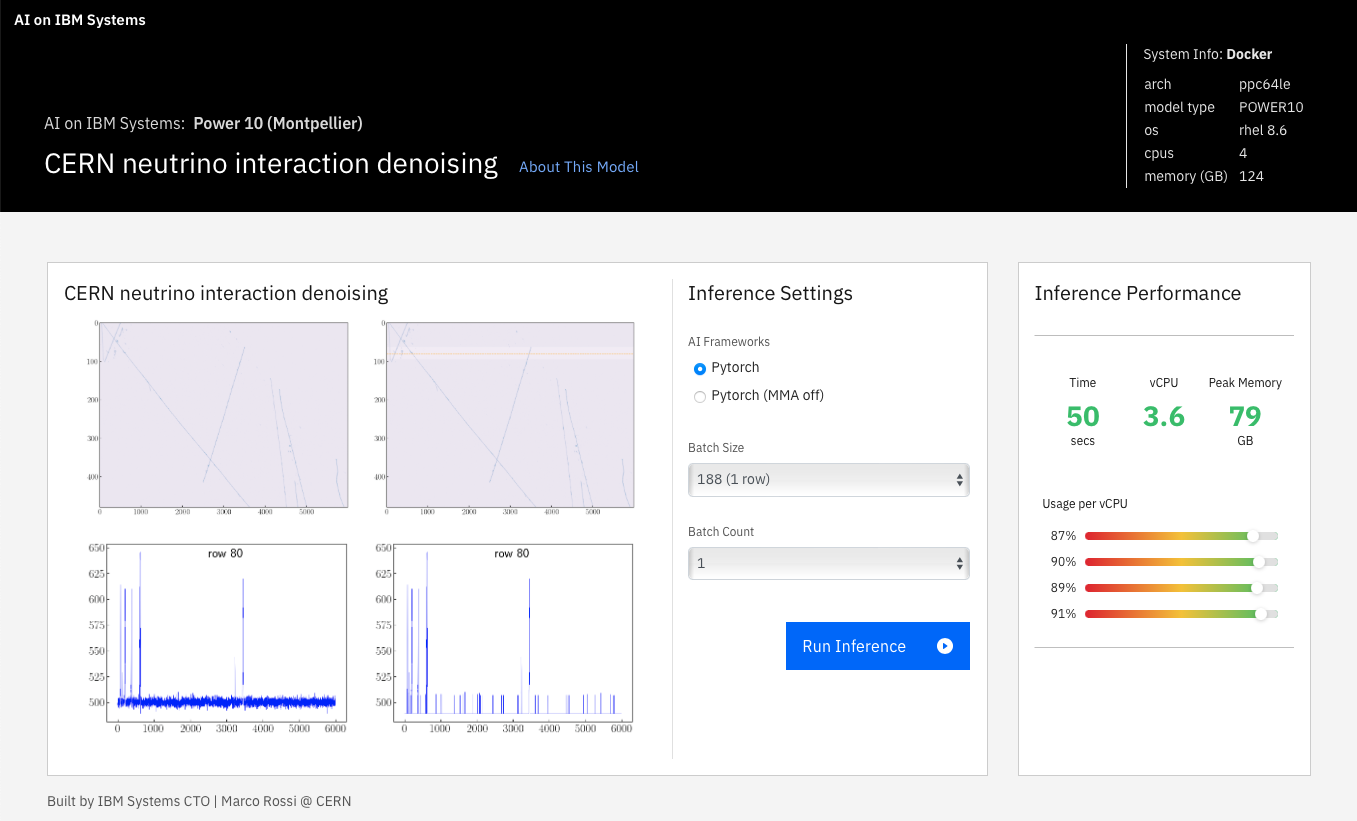
This example shows taking 1 row of the neutrino interaction image and finding where the interaction or lines occur. The denoising application shows only the interactions where the two charts on the bottom show where the interactions occur as a result.
These applications demonstrated the AI capabilities of the Power10 MMA system from a developer perspective, where we explored the usability of running AI inferencing on Power10. They showcase different industry applications including manufacturing, finance, and scientific research.
Train anywhere, run on Power10 MMA
With Power10 and MMA on-chip acceleration, AI inferencing becomes part of the workload and data processing right on the system embedded in the path of application execution. Although our results are not meant for benchmarking, we have demonstrated the speed-up with MMA and the benefit of using Power10 MMA for AI inferencing.
The data scientist and developer experience is also simplified to take advantage of the MMA without any re-tooling. The demo framework makes it easy to add new use cases or new AI frameworks.
Operationalizing AI inferencing directly on the Power10 system brings AI closer to data – what is sometimes referred to as "AI at the point of data." As we've shown here, this can add enormous value to a business as a critical loss-prevention factor, and be a key differential versus competitors in the industry. Doing so on IBM Power10 systems also allows AI to inherit and benefit from the Enterprise Qualities of Service (QoS): reliability, availability, and security of the Power10 platform and get a performance boost. Enterprise business workflows can now readily and consistently consume insights from AI.
You may also want to read this tutorial on IBM Developer, IBM Power10 Business Inferencing at Scale with Matrix Math Accelerator (MMA).
The authors would like to thank Alexander Lang, Anna Keist, Bruno Spruth, Chris Priest, Christian Zollin, Daniel Goldener, David Budd, Feng Xue, Fred Robinson, Ja Young Lee, Jim Van Oosten, Luc Colleville, Mark Nellen, Matt Drahzal, Maxime Deloche, Nicholas Lawrence, Peter Hofstee, Raj Krishnamurthy, Rajalakshmi Srinivasaraghavan, Rameswar Panda, Rodrigo Ceron, Shadman Kaif, Silvia Melitta Müller, and Theresa Xu for the collaboration.
Contact: Christine Ouyang.