About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Managing Kubernetes upgrades at scale for stateful applications
Explore strategies and best practices for efficiently managing Kubernetes upgrades at scale while minimizing disruptions to stateful workloads
On this page
Keeping Kubernetes systems updated with the latest versions is a significant challenge for organizations running workloads at scale. As Kubernetes evolves rapidly, it releases three minor version upgrades annually and patch updates as often as weekly. For more information about Kubernetes release cycles, see the Kubernetes website. This fast-paced development cycle can leave organizations struggling to stay current, increasing their exposure to security vulnerabilities from unpatched systems.
At IBM Cloud Databases, we manage hundreds of clusters across 12 data centers, operating tens of thousands of worker nodes in production. The sheer scale of our operations makes maintaining up-to-date systems complex. Adding to this challenge, our workloads are stateful databases, requiring careful orchestration to ensure data integrity and minimal downtime during updates.
This article outlines the lessons we’ve learned and the best practices we’ve developed for managing Kubernetes upgrades at scale while supporting stateful database workloads.
IBM Cloud Databases architecture
IBM Cloud provides a range of databases as a service (DBaaS), including PostgreSQL, MongoDB, Elasticsearch, MySQL, Redis, and more, all built on the IBM Cloud Kubernetes Service.
High availability design
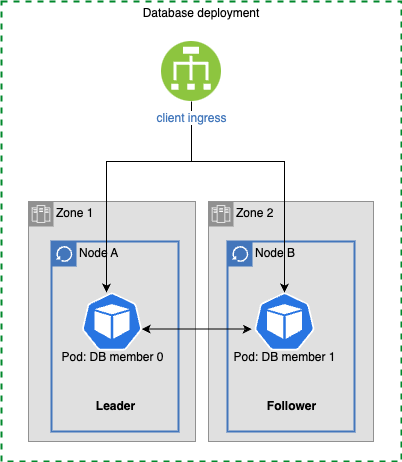
Each database operates in high availability (HA) mode across multiple availability zones. The specific HA implementation varies based on the database architecture.
PostgreSQL example: A leader pod and its persistent volume are hosted in one availability zone, while a replica pod and its persistent volume are located in another zone.
Compute hosting models
IBM Cloud Databases offers two compute hosting models to suit different use cases:
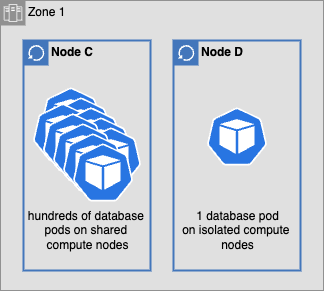
-
- Multiple database pods are colocated on a single worker node.
- Larger worker nodes can host up to hundreds of database pods simultaneously.
-
- Provides virtual machine-level isolation, where only one database pod runs per virtual machine.
- This model ensures enhanced security and performance isolation for workloads requiring dedicated resources.
Special considerations for stateful workloads
Managing Kubernetes upgrades for stateful database workloads introduces unique challenges that require careful handling to ensure database availability and data integrity.
Safely updating stateful nodes
When updating a worker node running a database pod, it is not advisable to simply cordon the node, delete the running pods, reload or delete the worker node.
Such actions can disrupt database connectivity, leading to potential data loss or corruption. Instead, the process requires:
Safe database shutdown: Ensure the database process is properly stopped to maintain data integrity.
Leader switchover: For leader pods, safely transition leadership to a replica. The former leader (now a replica) can then be safely shut down, allowing the worker node to be reloaded or deleted.
Managing connection drops during leader switchovers
Leader switchovers temporarily drop existing connections, requiring them to be re-established. To minimize customer impact:
Automatically re-establish connections for applications.
Schedule leader switchovers during maintenance windows (midnight to 6:00 AM local time) to further reduce visible impact to customers.
Orchestration challenges
These constraints, designed to protect customers from disruptions, require:
Careful orchestration: Pod deletions must be done safely to avoid service interruptions.
Efficiency at scale: The process must minimize the time required to update thousands of worker nodes across the infrastructure.
Upgrade process
IBM Cloud Databases has continuously refined its approach to managing worker upgrades, to minimize customer disruption and improve the speed of updates across the fleet. An outline of the key aspects of our most recent enhancements follows.
Development and testing workflow
When a new Kubernetes minor version is released:
Automation creates tracking issues and generates the necessary configuration changes in the codebase.
After thorough testing, configuration changes are reviewed and merged.
Once merged, automation detects the changes and updates all cluster masters to the latest minor version.
Upgrading worker nodes
Following a master update, an automated upgrade process begins for worker nodes:
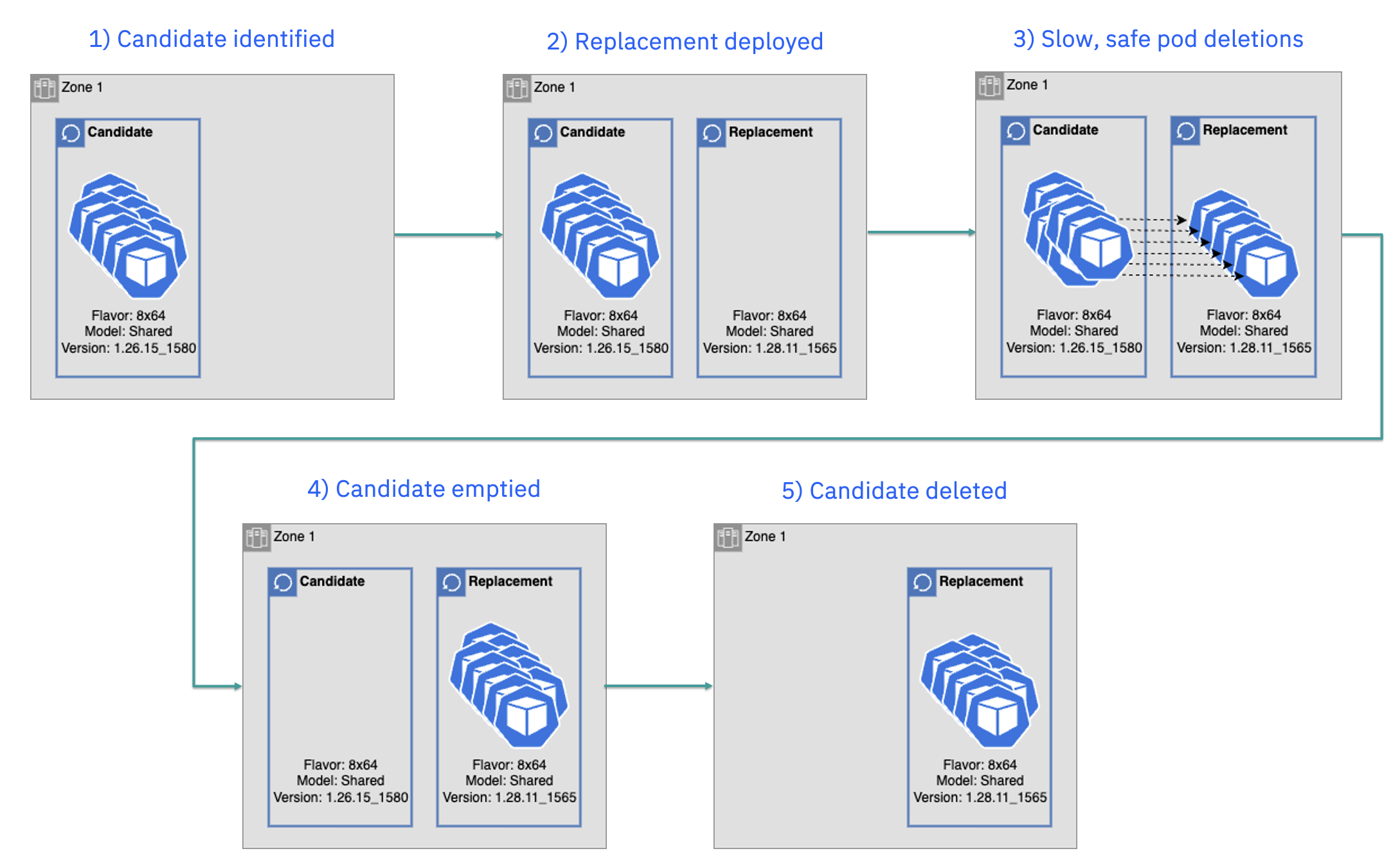
The process is managed by a Kubernetes operator that runs a continuous loop to monitor the cluster. It identifies nodes older than a specified age cutoff as upgrade candidates. Then, candidate nodes are upgraded one at a time.
Handling stateful workloads during upgrades
For stateful database workloads, special measures are taken:
Safe workload migration: Before upgrading a node, a replacement worker node is deployed to ensure workloads have a place to reschedule. Database workloads on the candidate node are safely deleted, following protocols to maintain data integrity.
Rate-limited pod deletions: The deletion of pods is rate-limited to prevent spikes in resource utilization, such as network or CPU, during database initialization. This approach minimizes visible customer impact, such as disk latency spikes on nodes hosting multiple databases.
Benefits of the enhanced process
By deploying replacement nodes in advance and limiting the rate of pod deletions, several issues that previously caused temporary high-availability loss during updates have been resolved.
Once all workloads are safely removed from a candidate node, the node itself is deleted. This systematic approach ensures efficient upgrades with minimal impact on customers.
Observability and alerting
A robust solution is incomplete without observability and alerting to ensure it operates as expected. IBM Cloud Databases offers a comprehensive monitoring and alerting system to oversee its global operations.
Sysdig dashboards
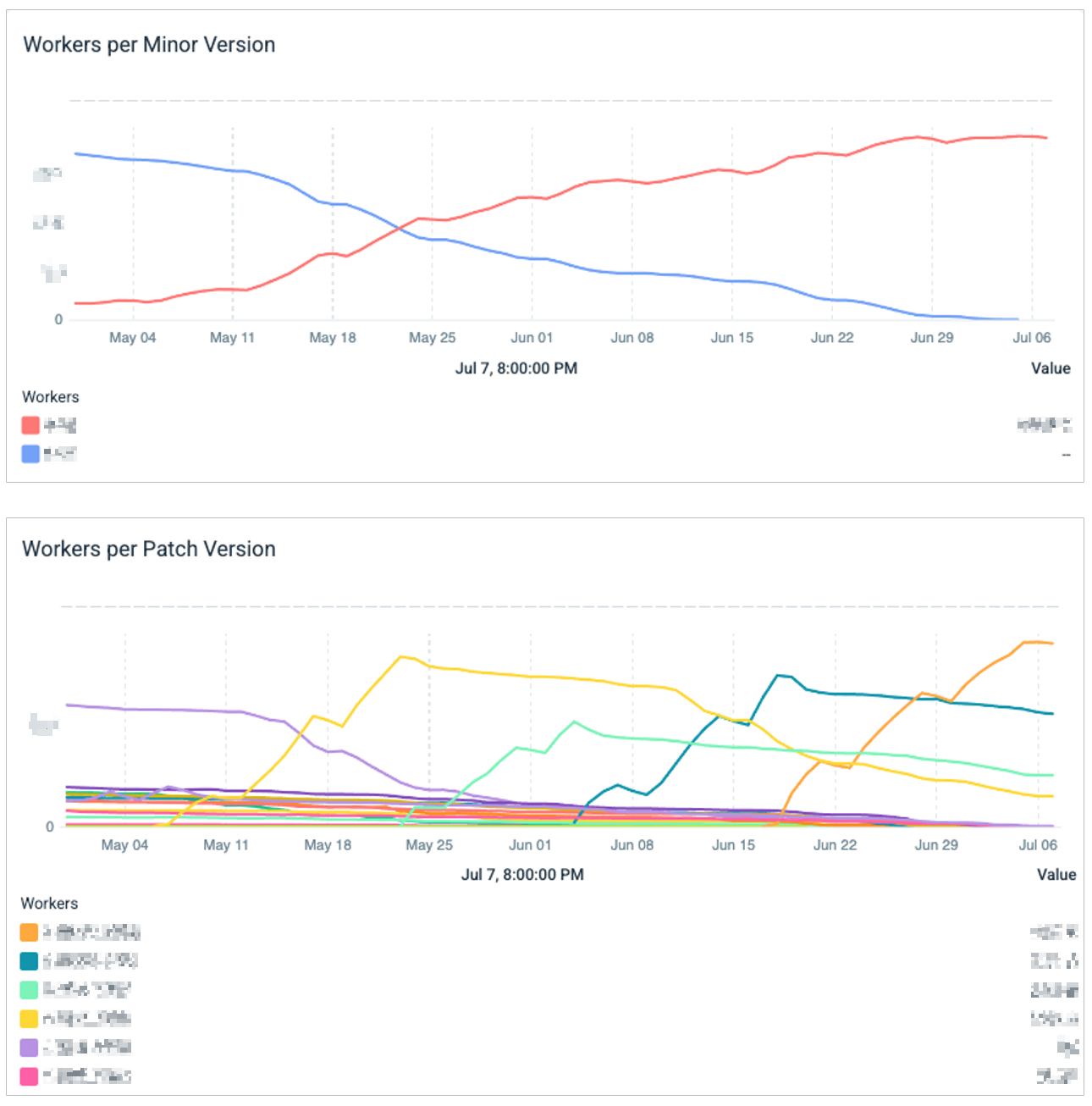
Custom Sysdig dashboards provide real-time visibility into our infrastructure. Team members can easily access key metrics such as:
- Total number of workers
- Workers categorized by minor version
- Workers categorized by patch level
- Degree of worker obsolescence (how out-of-date workers are)
- Status of updates (enabled or disabled)
These dashboards can be filtered by region, cluster, or minor Kubernetes version, offering targeted insights for specific areas of the infrastructure.
Alerting for worker expiration
Alerts notify the SRE team, enabling them to ensure timely action and promptly address any automation issues and maintain system reliability:
- Warning alerts: Triggered when a worker is nearing its expiration time
- Critical alerts: Triggered when a worker surpasses its expiration time
These alerts notify the SRE team, enabling them to promptly address any automation issues and maintain system reliability.
By combining detailed observability with proactive alerting, IBM Cloud Databases ensures smooth operations and quick resolution of potential disruptions.
Summary
Keeping Kubernetes systems up-to-date has been a complex and ongoing challenge. This complexity arises not only from the special handling required for stateful workloads like databases, where minimizing or eliminating customer-visible impact is critical, but also from the exponential growth in operational scale. Each month, the infrastructure expands to support the critical workloads of a growing customer base, making timely updates increasingly demanding.
The strategies and best practices shared in this article have enabled us to address these challenges more effectively. By accelerating update timelines while minimizing customer disruptions and reducing the need for SRE intervention, we have achieved significant improvements in both efficiency and reliability.
Successfully managing Kubernetes updates at scale requires:
- Extensive automation: Streamlining as many processes as possible.
- A balanced approach: Achieving the right balance between update velocity and high availability to ensure a seamless customer experience.
These advancements have positioned us to scale with confidence while maintaining the reliability and performance our customers expect.