About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Blog Post
Unleash the potential of LLMs through the Data Prep Kit
Introducing Data Prep Kit (DPK) as a streamlined data preparation tool for LLMs
Popular AI applications fall into one of these categories: Retrieval Augmented Generation (RAG), fine tuning, instruct tuning, or building applications based on agents. Developers can extend the power of these AI applications by adding their own domain data. An AI developer goes through a development lifecycle as shown in the following figure, when adding their own domain data.
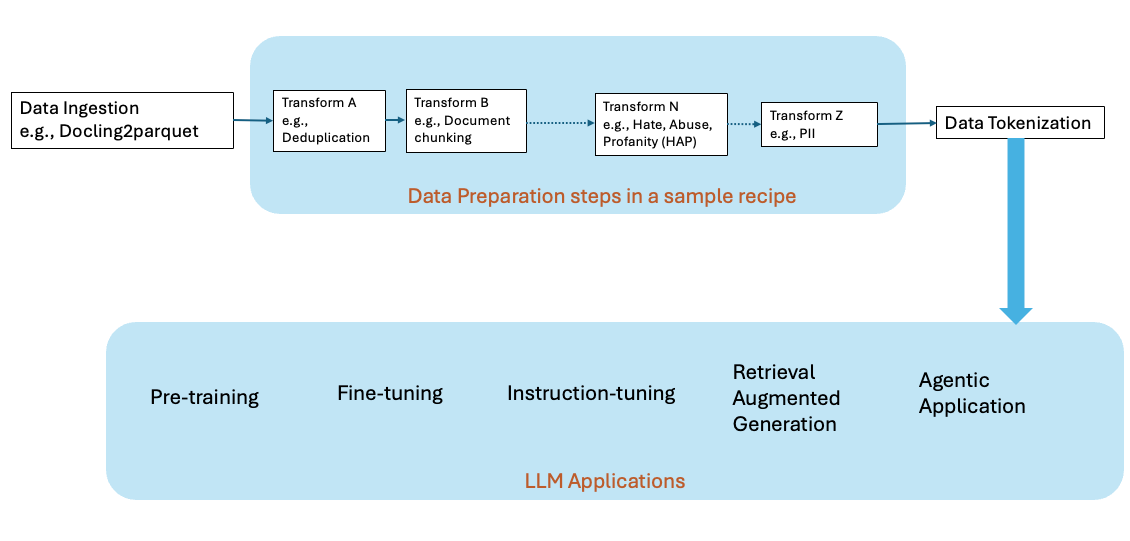
Data prepation is a time-consuming but critical part of building AI workloads. The volume of the data and the complexity of that data are some of the most challenging aspects of building AI workloads. Every use case has its own unique needs and manual verification of the data quality is not possible due to the huge data volumes.

To overcome these challenges, we introduced the open-source Data Prep Kit (DPK) with a friendly Apache 2.0 license. DPK currently consists of 20+ modules for pre-processing data for code and language. As such, they provide a comprehensive set of capabilities for ingestion, document annotation, filtering, and redaction of private information.
DPK modules, also referred to as transforms, help the developer get started and build end-to-end data pipelines, from ingestion to tokenization, that fit their use cases. These modules have been used to produce pre-training data sets for the Granite open models on HuggingFace.
DPK modules provide laptop-scale to datacenter-scale processing. Sample data processing pipelines are provided for real enterprise use cases like RAG, fine-tuning, and instruction-tuning. As an example, RAG, which has become an increasingly popular LLM enterprise application, starts with a new set of PDF or HTML files that were not used during the creation of LLM models. These new sets of PDF or HTML files will be processed by various DPK transforms for tasks such as deduplication and chunking before saving them into vector databases and embedding in a typical RAG application pipeline.
Common frameworks (for Ray and Spark) are used to scale up executions and are integrated into the data processing library to enable developers to build custom modules that can scale across a variety of runtimes. APIs and configurations are offered by DPK for the following runtimes: Python, Ray (local and distributed), Spark, and Kubeflow Pipelines (local and distributed). DPK leverages Kubeflow Pipelines-based workflow automation for broader applicability.
Ready to get started?
Start with the Get Started with DPK learning path.
Check out our Getting Started Guide. We suggest trying DPK for the first time by using this Google Colab notebook example that requires zero setup on your local machine.
Explore our data-prep-kit GitHub repo, and check out the examples/notebooks. We also have a few tutorials for developers who want to create their own transforms. And, stay tuned for more hands-on tutorials!
Learn more about the technical aspects of DPK in our article, "Data-Prep-Kit: getting your data ready for LLM application development."
Want to learn more?
IBM’s newest launch, watsonx.data integration, leverages the power of Data Prep Kit (DPK) to simplify unstructured data ingestion, transformation, and processing, but brings a scalable, repeatable, and easily maintainable data pipeline approach. Paired with our hybrid lakehouse, watsonx.data, users can work across both structured and unstructured sources to build powerful, more accurate retrieval applications!