Comparing ELSER for retrieval relevance on the Hugging Face MTEB Leaderboard
ELSER (Elastic Learned Sparse EncodeR) is Elastic’s transformer language model for semantic search and is a popular model for anyone interested in utilizing machine learning to elevate the relevance of a traditional search experience or to power a newly designed Retrieval Augmented Generation (RAG) application.
ELSER v2 remains in the top-10 models on MTEB for Retrieval when grouping together the multiple flavors of the same competitor family. It is also one of the very few models in the top-10 that was released in 2023, with the majority of the competition having been released in 2024.
Timeline of ELSER
First introduced in June of 2023, and with a second version made generally available in November 2023, ELSER from day one has been designed to minimize the barrier to semantic search, while significantly improving search relevance, by capturing the context, semantic relationships and user intent in natural language. Among other use cases, this is an incredibly intuitive and valuable addition to RAG applications, as surfacing the most relevant results is critical for generative applications to produce accurate responses based on your own private data and to minimize the probability of hallucinations.
ELSER can be used in tandem with the highly scalable, distributed Elasticsearch vector database, the open Inference API, native model management and the full power of the Search AI platform.
ELSER is the component that provides the added value of state-of-the-art semantic search for a wide range of use cases and organizations. Because it is a sparse vector model (this will be explained further later in the blog), it is optimized for the Elasticsearch platform and it achieves superior relevance out of domain.
When ELSER was first released, it outperformed the competition in out-of-domain retrieval, i.e. without you having to retrain/fine-tune a model on own data, as measured by the industry standard BEIR benchmark. This was a testament to Elastic’s commitment to democratize AI search.
ELSER v2 was released in October 2023 and introduced significant performance gains on your preferred price point of operation by adding optimizations for Intel CPUs and by introducing token pruning. Because we know that the other equally important part of democratizing AI search is reducing its cost. As a result we provide two model artifacts: one optimized for Intel CPUs (leveraged by Elastic Cloud) and a cross-platform one.

NDCG@10 for BEIR data sets for BM25 and ELSER V2
Customer Reception
Customers worldwide leverage ELSER today in production search environments, as a testament to the ease of use and the immediate relevance boost that is achievable in a few clicks.
Examples of ELSER customer success stories include Consensus, Georgia State University and more.
When these customers test ELSER in pilots or initial prototypes, a common question is how does ELSER compare with relevance that can be achieved with traditional keyword (i.e.BM25) retrieval or with the use of a number of other models, including for example OpenAI’s text-embedding-ada-002. To provide the relevant comparison insights, we published a holistic evaluation of ELSER (the generally available version) on MTEB (v1.5.3). MTEB is a collection of tasks and datasets that have been carefully chosen to give a solid comparison framework between NLP models. It was introduced with the following motivation: “Text embeddings are commonly evaluated on a small set of datasets from a single task not covering their possible applications to other tasks. It is unclear whether state-of-the-art embeddings on semantic textual similarity (STS) can be equally well applied to other tasks like clustering or reranking. This makes progress in the field difficult to track, as various models are constantly being proposed without proper evaluation. To solve this problem, we introduce the Massive Text Embedding Benchmark (MTEB).” (source paper).
MTEB Comparison - What you need to know
For a meaningful comparison on MTEB, a number of considerations come into play.
- First, the number of parameters. The more parameters a model has, the greater its potential, but it also becomes far more resource intensive and costly. Models of similar size (number of parameters) are best for comparison, as models with vastly different numbers of parameters typically serve different purposes in a search architecture.
- Second, one of the aims of MTEB is to compare models and their variations on a number of different tasks. ELSER was designed specifically to lower the barrier for AI search by offering you state-of-the-art out-of-domain retrieval, so we will focus on the outcomes for the Retrieval task. Retrieval is measured with the ndcg@10 metric.
- Finally some models appear in multiple flavors, incorporating different numbers of parameters and other differentiations, forming a family. It makes more sense to group them together and compare against the top performer of the family for the task.
ELSER on MTEB
According to the above, filtering for the classes of up to 250 million parameters (ELSER has 110 million parameters), at the time of writing of this blog and as we are working on ELSER v3, ELSER v2 remains in the top-10 models for Retrieval when grouping together the multiple flavors of the same competitor family. It is also one of the very few models in the top-10 that was released in 2023, with the majority of the competition having been released in 2024.

The top of the MTEB list for Retrieval (nDCG@10) for models with <250 million parameters. At the time of writing, ELSER ranks top-10 for the retrieval task. It is one of the very few models in the group that was released in 2023, with the vast majority released in 2024. The list, when filtered as mentioned inline, includes more then 80 models (not grouped) at the time of writing.
Elastic’s Continued Investment in ELSER
As mentioned previously, ELSER uses a contextualized sparse vector representation, a design choice that gives it the nice properties mentioned before and all the space for gains and feature extensions in future releases that are already in development. This sets it apart on MTEB, as the vast majority of models on the leaderboard are embeddings, i.e. dense vectors. This is why you will notice a much larger number of dimensions in the corresponding MTEB column for ELSER compared with the other models. ELSER extends BERT’s architecture and expands the output embeddings by retaining the masked language model (MLM) head and adapting it to create and aggregate per-token activation distributions for each input sequence. As a result, the number of dimensions is equal to BERT’s vocabulary, only a fraction of which get activated for a given input sequence.
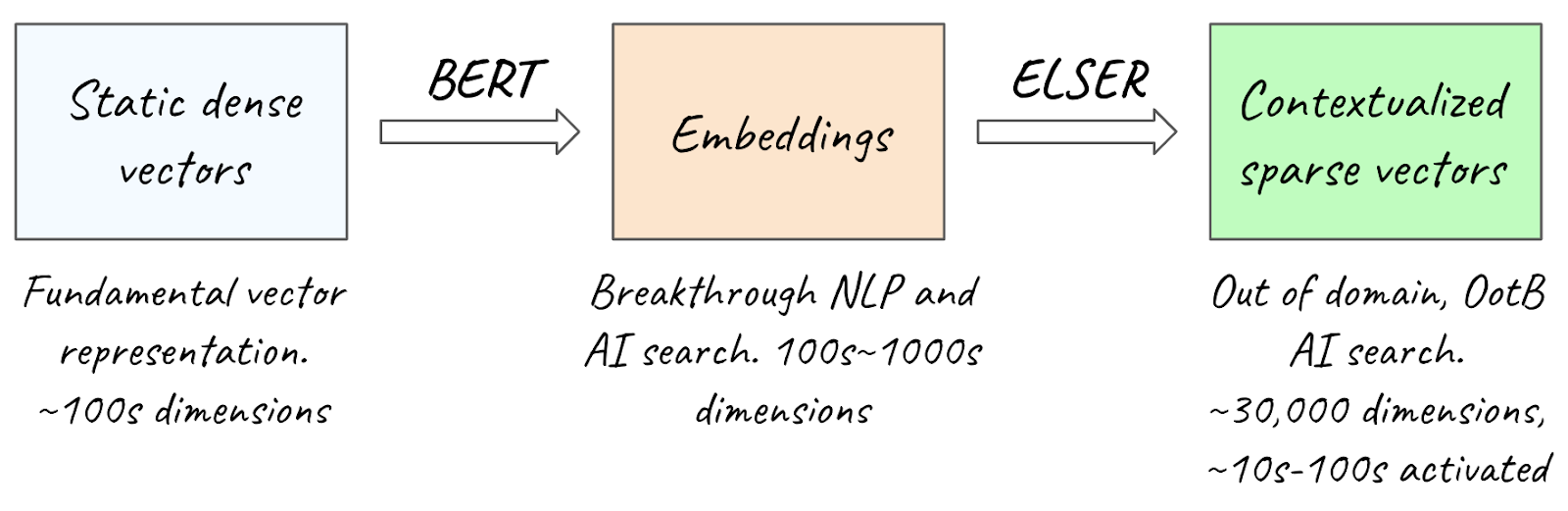
The upcoming ELSER v3 model is currently in development, being trained with the additional use of LLM-generated data, new advanced training recipes and other state-of-the-art and novel strategies as well as support for GPU inference.
Conclusion
The innovation in this space is outpacing many customers' ability to adopt, test and ensure enterprise quality incorporation of new models into their search applications. Many customers lack holistic insight into the metrics and methodology behind the training of the model artifacts, leading to additional delays in adoption.
From the very first introduction of our ELSER model, we have provided transparency into our relevance goals, our evaluation approach for improved relevance and the investments into efficient performance of this model on local, self-managed deployments (even those hosted on laptops!) with capabilities to enable scale for large production grade search experiences.
Our full results are now published on the MTEB Leaderboard to provide an additional baseline in comparison to new emerging models. In upcoming versions of ELSER we expect to apply new state of the art retrieval techniques, evaluate new use cases for the model itself, and provide additional infrastructure support for fast GPU powered ELSER inference workloads. Stay tuned!
Links
https://www.elastic.co/search-labs/blog/introducing-elser-v2-part-1
https://www.elastic.co/search-labs/blog/introducing-elser-v2-part-2
https://www.elastic.co/search-labs/blog/may-2023-launch-information-retrieval-elasticsearch-ai-model
Ready to try this out on your own? Start a free trial.
Looking to build RAG into your apps? Want to try different LLMs with a vector database?
Check out our sample notebooks for LangChain, Cohere and more on Github, and join Elasticsearch Relevance Engine training now.
Related content

July 26, 2024
Serverless semantic search with ELSER in Python: Exploring Summer Olympic games history
This blog shows how to fetch information from an Elasticsearch index, in a natural language expression, using semantic search. We will load previous olympic games data set and then use the ELSER model to perform semantic searches.

June 21, 2023
Introducing Elastic Learned Sparse Encoder: Elastic’s AI model for semantic search
Learn about the Elastic Learned Sparse Encoder (ELSER), an AI model for high relevance semantic search across domains.
October 17, 2023
Improving information retrieval in the Elastic Stack: Optimizing retrieval with ELSER v2
Learn how we are reducing the retrieval costs of the Learned Sparse EncodeR (ELSER) v2.