About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Data governance for AI models with watsonx
Governance across the data lifecycle with Cloud Pak for Data, watsonx.data, watsonx.governance, and OpenPages
On this page
Risk and uncertainty about data and AI model outputs are the two biggest barriers to teams adopting AI today. Everybody wants AI but cannot risk having their own data or their client’s data exposed. Safe, widespread AI adoption will require teams to embrace both data and AI Governance across the data lifecycle to provide confidence to consumers, enterprises, and regulators.
Teams need to be able to identify patterns and relationships that can scale with large volumes of data that is siloed across a hybrid multi-cloud environment. Data can help understand the past or predict the future, and sometimes organizations collect data even without knowing its advantages in the future. When the data volumes get overwhelming, its then the relationship between data and AI becomes interesting. Finally, there is no AI without data and data is the only source of competitive advantage in business.
Today, generative AI models make much more effective use of unstructured data, which is most of all new data getting generated. Gen AI can dive into large volumes of text data in documents or software code and spot patterns and make connections without much preparation or supervision and generate insights that would not have been otherwise possible. Gen AI can also be applied to the data management problem to organize, refine, and enrich the data to enhance data quality and make it more consumable. Managing data more effectively and efficiently has cost and business performance implications and a point of competitive advantage. Organizations can look at monetizing data through data products and for this data governance and AI model management become imperative.
The key elements of data governance for AI include:
- Good data quality practices. Organize the data into catalogs that can have hierarchies and a business glossary for the given business domain.
- Data access policies. This is to provide what data is to be accessed by whom and includes compliance to regulatory requirements. It includes redacting or obfuscating sensitive data. These policies also include role-based and attribute-based access.
- Monitoring and enforcement of data policies. Set policies centrally and enforce them locally while actively monitoring model inputs and outputs to ensure that the policies are effective. Rules can be created that roll up to policies. Monitor model drift and bias as its exposed to real world interactions.
Clients need to move from a handful of single prototypes to the next phase of customizing the models with their own enterprise data and deploying them to production. These models also need to be integrated with their enterprise applications and workflows.
The ways to customize generative AI with the enterprise datainclude:
- Tuning the models with enterprise data. Refining the model with quality data to improve responses. This is a differentiator as everyone has access to the same foundational models
- Using Retrieval Augmented Generation (RAG). Uses a knowledge base of quality data to improve accuracy and limit responses to known facts. The new risk of hallucinations needs to be addressed.
Data governance architecture with IBM Cloud Pak for Data
IBM Cloud Pak for Data is an enterprise-grade, open, and modular data and analytics platform that provides end-to-end data, analytics, and AI governance capabilities. With its AI-driven automation features, it simplifies the processes and tasks of data sourcing, data discovery, access, sharing, protection, and overall governance across the enterprise.
As shown in the following diagram, data in all forms – structured, semi-structured, or unstructured data – can be sourced using the services available on Cloud Pak for Data. Cloud Pak for Data provides several ways to extract the data from the source systems.
Data governance is possible with Data Virtualization with no requirement of replicating the data, saving on costs along with enhanced security. Services like DataStage, Data Replication, and Data Gate help replicate or transform the data for further use. Over 100 data sources are supported including SAP, Salesforce, or mainframe sources making it very suitable for enterprise level Data Governance. Now in addition to IBM Db2 for z/OS, IMS and VSAM sources are also supported for near real time data sync with watsonx.data. Companies can unlock the value of the data that resides on mainframes as most of the AI and analytics happens on the cloud.
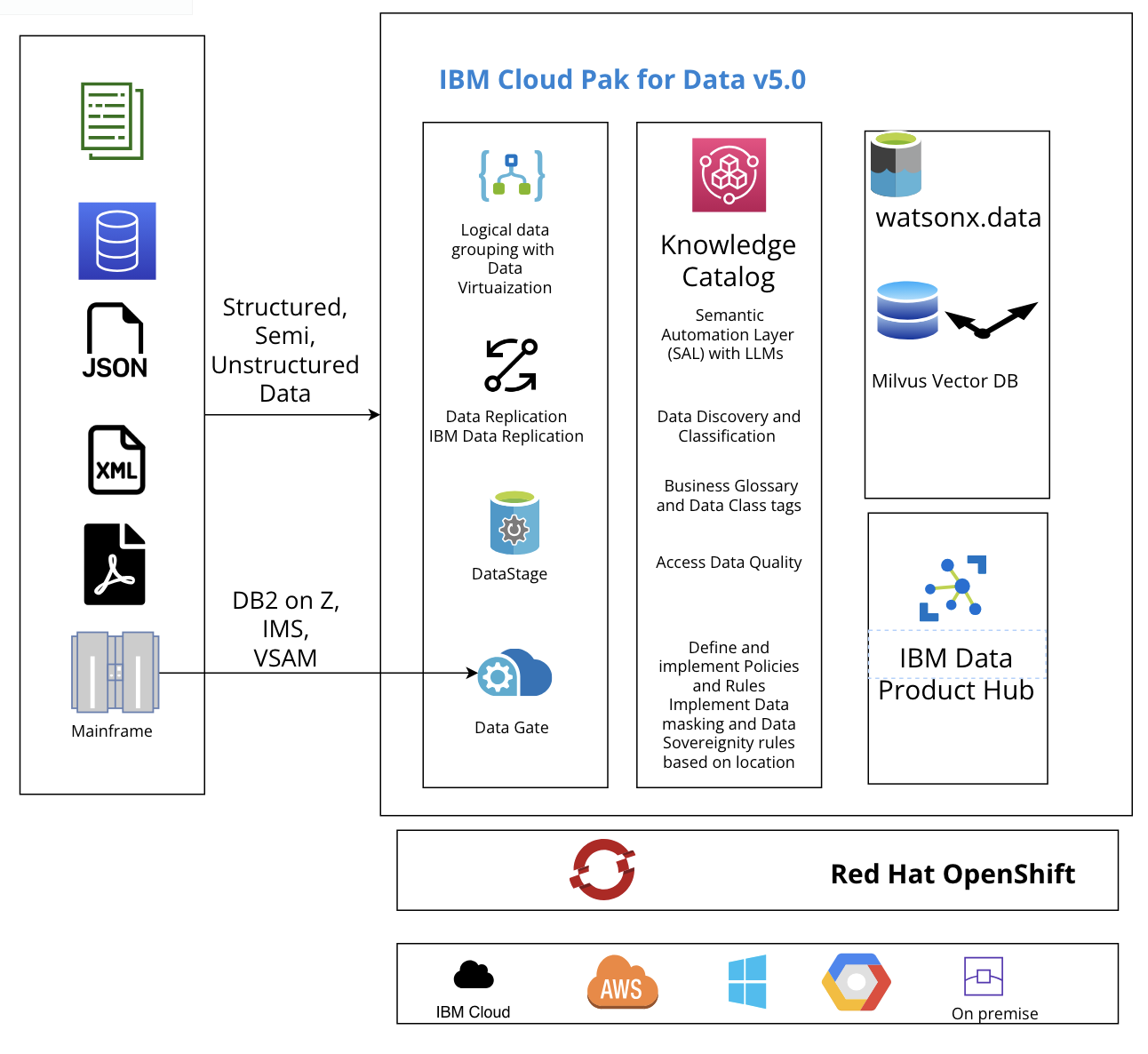
The Knowledge Catalog in Cloud Pak for Data provides the following data governance capabilities:
- Enables self-service analytics. Different personas can access the data without dependency on the IT organization to provide the data.
- Policy and rules management. Setup workflows among the different personas for approvals before publishing the catalog. Address regulatory compliance and support audit readiness.
- Automate data privacy and security. Leverages AI to identify sensitive data and enforce data access controls dynamically across endpoints. Helps with regulatory compliance.
- Data quality and lineage. Access data quality in an automated manner. Provides data profiling, cleansing, monitoring and enrichment of metadata. Manta provides for business and technical data lineage. Starting with version 5.0, the semantic automation layer leverages generative AI capabilities to enrich the metadata for better cataloguing and search.
- Centralized metadata management. Simplifies data discovery, enhances collaboration, and ensures consistency achieving a holistic understanding of the data landscape.
- Fine-grained access controls. Enhances data security and compliance.
watsonx.data also comes with Cloud Pak for Data and it is described in the next section. watsonx.data provides for data governance with the Knowledge Catalog and also provides for the milvus vector database that is used for storing embeddings for generative AI use cases.
Overall, IBM Cloud Pak for Data provides a comprehensive and scalable set of governance, risk, and compliance capabilities that helps enterprises to enable responsible and ethical use of data and AI technologies through their organizations.
Data governance architecture with watsonx.data
IBM watsonx.data is IBM’s lake house solution that breaks down the walls between data, governance, and AI. Watsonx.data sources data with data federation. It leverages Knowledge Catalog to govern the data and transforms the data with the Spark engine that is used to build the models. (The end-to-end model lifecycle is managed with watsonx.governance, which is described in the next section.)
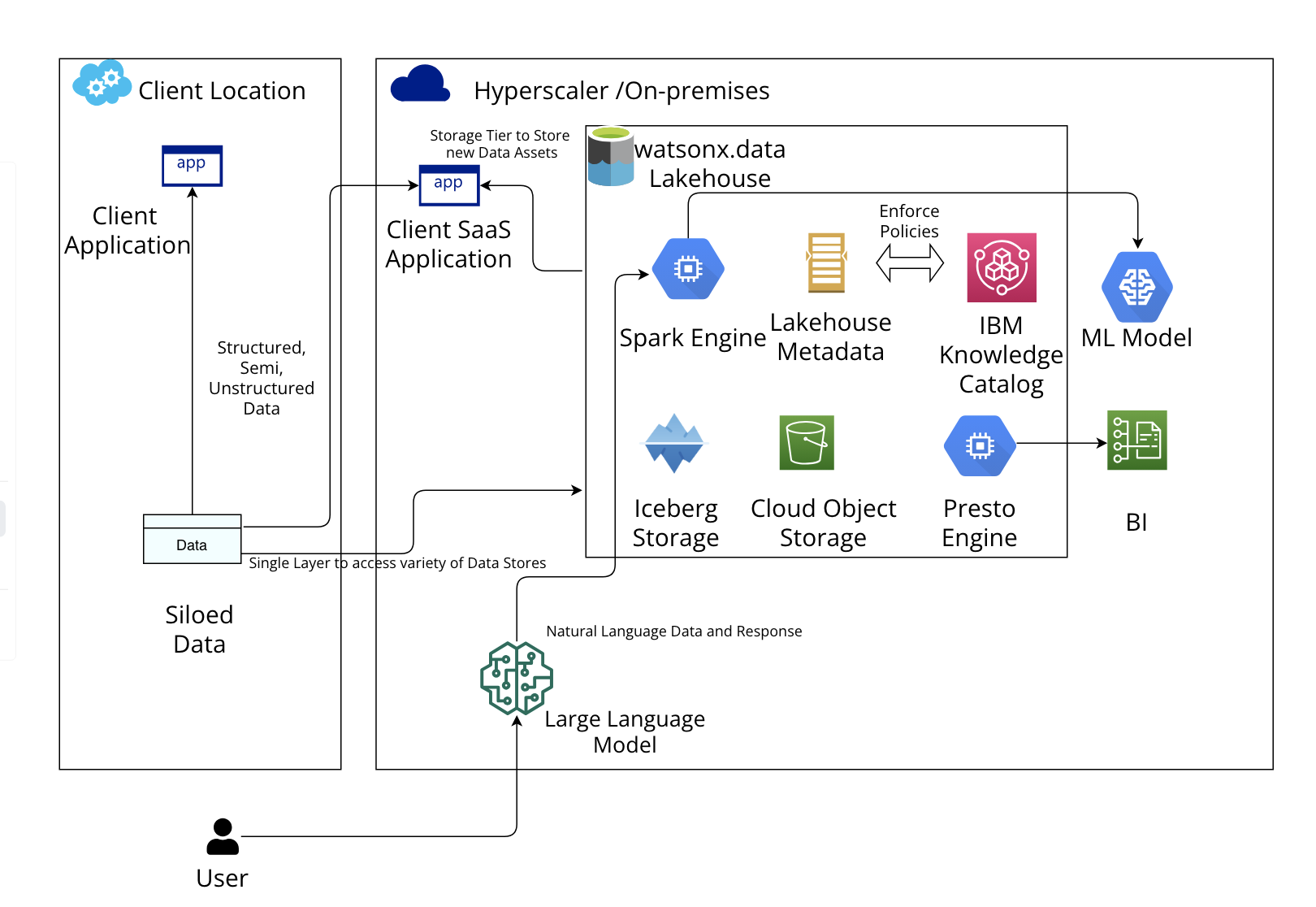
With Knowledge Catalog, which is also part of watsonx.data, you get the complete data lineage of the used data sets, data pipelines, and AI pipelines. Watsonx.data combines the flexibility, scalability, and cost advantages of data lakes with the performance and functionality of data warehouses.
You can connect watsonx.data to a generative AI platform for augmenting queries with large language models (LLMs) as shown in the previous diagram. Users can input a prompt, which is sent to a fine-tuned LLM to generate retrieval queries, which can then be executed by the engines supported in the data lakehouse.
AI governance architecture with watsonx.governance
The AI governance use-case consists of the following steps:
- Track models. Business analysts can track the model through all stages of the AI lifecycle as data scientists build and train the model. ModelOps engineers deploy and evaluate it. Factsheets document model history and generate performance metrics.
- Monitor deployed models. Data scientists monitor the deployed model for fairness and accuracy. Metrics from the Watson OpenScale quality monitor and fairness monitor indicate how well the model predicts outcomes and if it produces any biased outcomes. Also shows insights into how the model comes to its decisions.
- Automate the ML lifecycle. Orchestration Pipelines help create repeatable and scheduled flows that automate machine learning pipelines, from data ingestion to model training, testing, and deployment.
Premature deployment and adoption of AI systems can place organizations at huge risks that could include loss of reputation, financial loss, or failing on regulatory compliance. Hence, AI governance becomes very important.
AI governance refers to a set of rules, standards, and processes for the responsible development and deployment of AI systems. These are guardrails meant to minimize the risk and maximizing the potential benefits. The data used to train the AI models can be biased and violate privacy and copyright laws. Black box models can result in loss in trust and transparency. Over time, the models need to be continuously monitored else the quality of the output will deteriorate.
The following diagram shows the typical governance architecture using watsonx.governance.
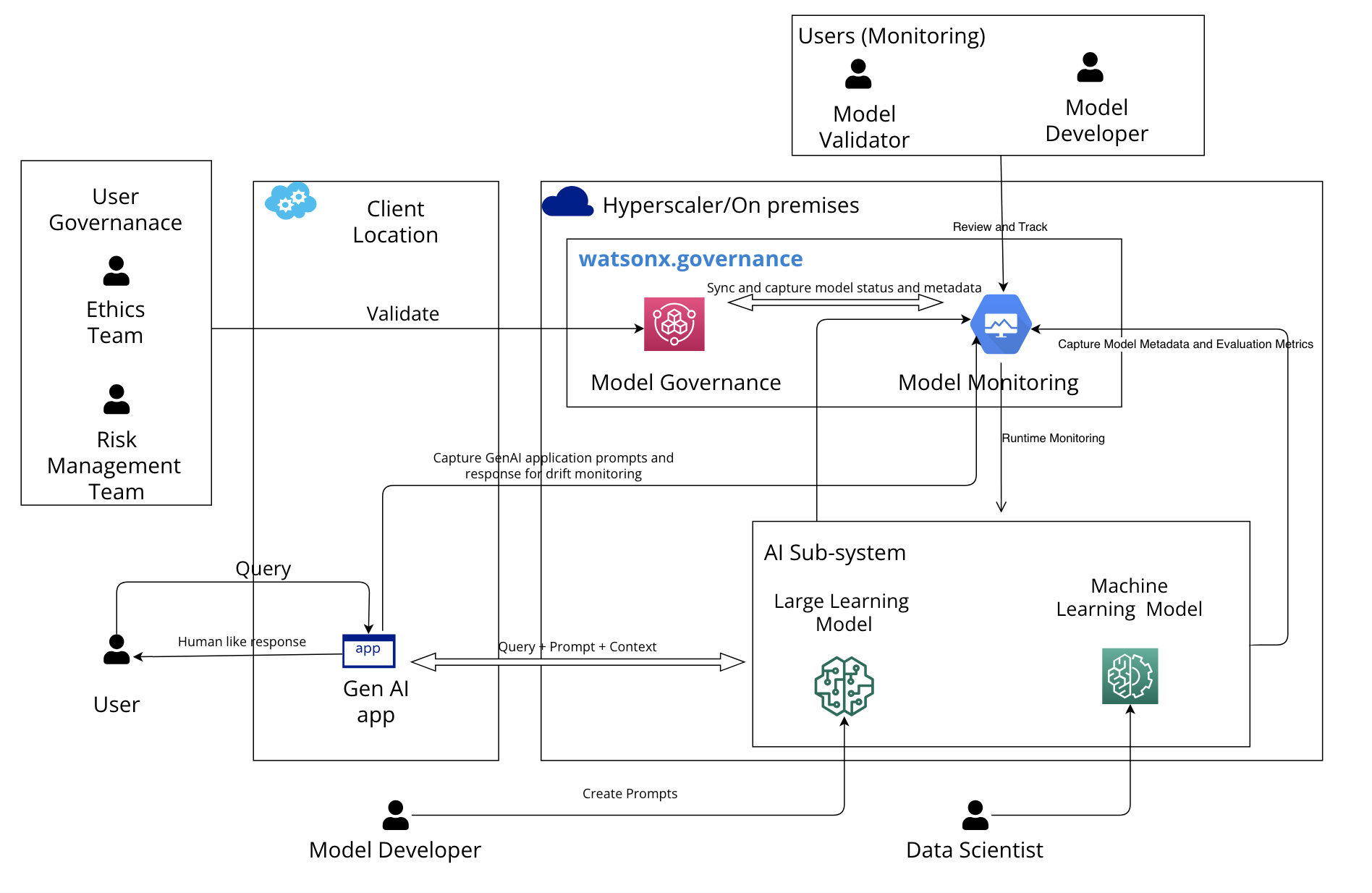
The model developer prompt tunes the LLM and the output is captured and continuously evaluated by the Model Monitoring component. Results are then compared to the criteria and controls set by the enterprise governance team and approved for use in production if it meets the laid criteria. The model developer monitors the model to meet enterprise criteria for fairness and bias, accuracy, and transparency with explainable responses by comparing it with the model governance metrics.
The Model Monitoring component also captures user prompts and the model's responses. Model drift as well as new areas requiring additional tuning are identified.
Additionally, you can integrate IBM OpenPages with watsonx.governance to help in governing models. Criteria such as the Rouge score, BLEU, are set within the IBM OpenPages Model Risk Management tool and then are subsequently propagated to watsonx.governance.

With watsonx.governance, these AI governance use cases are addressed:
- Ensuring model governance and compliance. It is essential for organizations to maintain a comprehensive record of model history to ensure compliance and transparency among all stakeholders involved.
- Managing risk and promoting responsible AI. Organizations must actively monitor models in production to ensure their validity, accuracy, and ethical use, guarding against biases and deviations from intended objectives.
- Streamlining the model lifecycle. Implementing standardized and efficient processes enables organizations to consistently retrain and deploy models, ensuring smooth transitions into production environments. This operationalizes the lifecycle of models effectively.
Conclusion
Organizations can leverage AI technologies by putting in place a strong data governance framework with IBM Cloud Pak for Data, watsonx.data, and watsonx.governance. This framework supports implementing AI at scale for an enterprise while maximizing benefits through informed decision-making. In addition to addressing regulatory compliance, good data and AI governance builds trust among stakeholders and makes the shift to be AI driven easier.