In this blog post we are going to take a look at how to use Elasticsearch with some popular Ruby tools. We'll implement the common use APIs found in the "Getting Started" guide for the Ruby client. If you follow that link, you can see how you can run these same actions with the official Elasticsearch client: elasticsearch-ruby.
We run extensive tests on the client to make sure all the APIs in Elasticsearch are supported for every version, including the current version in development. This covers almost 500 APIs.
However, there might be cases where you don't want to use the client and want to implement some of the functionality yourself in your Ruby code. Your code could depend heavily on a particular library, and you'd like to reuse it for Elasticsearch. You could be working in a setup where you only need a couple of the APIs and don't want to bring in a new dependency. Or you have limited resources and you don't want to use a full-fledged Client that can do everything in Elasticsearch.
Whatever the reason, Elasticsearch makes it easy by exposing REST APIs that can be called directly, so you can access its functionality by making HTTP requests without the client. When working with the API, it's recommended to take a look at the API Conventions and Common options.
Introduction
The libraries used in these examples are Net::HTTP, HTTParty, exon, HTTP (a.k.a. http.rb), Faraday and elastic-transport. On top of looking at how to interact with Elasticsearch from Ruby, this post will take a short look at each of these libraries, allowing us to get to know them and how to use them. It's not going to go in depth for any of the libraries, but it'll give an idea of what it's like to use each of them.
The code was written and tested in Ruby 3.3.5. The versions of each tool will be mentioned in their respective sections. The examples use require 'bundler/inline' for the convenience of installing the necessary gems in the same file where the code is being written, but you can use a Gemfile instead too.
Setup
While working on these examples, I'm using start-local, a simple shell script that sets up Elasticsearch and Kibana in seconds for local development. In the directory where I'm writing this code, I run:
curl -fsSL https://elastic.co/start-local | shThis creates a sub directory called elastic-start-local, which includes a .env file with the information we need to connect and authenticate with Elasticsearch. We can either run source elastic-start-local/.env before running our Ruby code, or use the dotenv gem:
require 'dotenv'
Dotenv.load('./elastic-start-local/.env')The following code examples assume the ENV variables in this file have been loaded.
We can authenticate with Elasticsearch by using Basic Auth or API Key Authentication. To use Basic Auth, we have to use the user name 'elastic' and the value stored in ES_LOCAL_PASSWORD as password. To use API Key Authentication, we need the value stored in ES_LOCAL_API_KEY in this .env file. Elasticsearch can be managed using Kibana, which will be running at http://localhost:5601 with start-local, and you can create an API Key manually in Kibana too.
Elasticsearch will be running on http://localhost:9200 by default, but the examples load the host from the ES_LOCAL_url environment variable.
You could also use any other Elasticsearch cluster to run these, adjusting the host and credentials accordingly. If you're using start-local, you can stop the running instance of Elasticsearch with the command docker compose stop and restart it with docker compose up from the elastic-start-local directory.
Net::HTTP
Net::HTTP provides a rich library that implements the client in a client-server model that uses the HTTP request-response protocol. We can require this library in our code with require 'net-http' and start using it without installing any extra dependencies. It's not the most user-friendly one, but it's natively available in Ruby. The version used in these examples is 0.4.1.
require 'json'
require 'net/http'
host = URI(ENV['ES_LOCAL_url'])
headers = {
'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}",
'Content-Type' => 'application/json'
}This gives us the setup for performing requests to Elasticsearch. We can test this with an initial request to the root path of the server:
response = JSON.parse(Net::HTTP.get(host, headers))
puts response
# {"name"=>"b3349dfab89f", "cluster_name"=>"docker-cluster", ..., "tagline"=>"You Know, for Search"}And we can inspect the response for more information:
response = Net::HTTP.get_response(host, headers)
puts "Content-Type: #{response['Content-type']}"
puts "Response status: #{response.code}"
puts "Body: #{JSON.parse(response.body)}"
# Content-Type: application/json
# Response status: 200
# Body: {"name"=>"b3349dfab89f", ...We can now try to create an index:
index = 'nethttp_docs'
http = Net::HTTP.new(host.hostname, host.port)
# Create an index
response = http.put("/#{index}", '', headers)
puts response
# {"acknowledged":true,"shards_acknowledged":true,"index":"nethttp_index"}With our index, we can now start to work with Documents.
# Index a document
document = { name: 'elasticsearch-ruby', description: 'Official Elasticsearch Ruby client' }.to_json
response = http.post("/#{index}/_doc", document, headers)
puts response
# {"_index":"nethttp_docs","_id":"...
# Save the id for following requests:
id = JSON.parse(response.body)["_id"]Notice how we need to transform the document to JSON to use it in the request. With an indexed document, we can test a very simple Search request:
# Search
search_body = { query: { match_all: {} } }.to_json
response = http.post("#{index}/_search", search_body, headers)
JSON.parse(response.body)['hits']['hits']
# => [{"_index"=>"nethttp_docs", "_id"=>...And do some more work with the indexed data:
# Get a document
response = http.get("#{index}/_doc/#{id}", headers)
JSON.parse(response.body)
# => {"_index"=>"nethttp_docs", ..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Ruby client"}}
# Update a document
document = { doc: { name: 'net-http-ruby', description: 'NetHTTP Ruby client' } }.to_json
response = http.post("#{index}/_update/#{id}", document, headers)
# => <Net::HTTPOK 200 OK readbody=true>
# Deleting documents
response = http.delete("#{index}/_doc/#{id}", headers)
# => <Net::HTTPOK 200 OK readbody=true>Finally, we'll delete the index to clean up our cluster:
# Deleting an index
response = http.delete(index, headers)
# => <Net::HTTPOK 200 OK readbody=true>HTTParty
HTTParty is a gem "with the goal to make HTTP fun". It provides some helpful abstractions to make requests and work with the response. These examples use version 0.22.0 of the library.
require 'bundler/inline'
require 'json'
gemfile do
source 'https://rubygems.org'
gem 'httparty'
end
host = URI(ENV['ES_LOCAL_url'])
headers = {
'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}",
'Content-Type' => 'application/json'
}The initial request to the server:
response = HTTParty.get(host, headers: headers)
# => {"name"=>"b3349dfab89f",
...
# And we can see more info:
response.headers['content-type']
# => "application/json"
response.code
# => 200
JSON.parse(response.body)
# => {"name"=>"b3349dfab89f", ...If the response Content Type is application/json, HTTParty will parse the response and return Ruby objects such as a hash or array. The default behavior for parsing JSON will return keys as strings. We can use the response as follows:
response
# =>
# {"name"=>"b3349dfab89f",
# "cluster_name"=>"docker-cluster",
# ...
# "tagline"=>"You Know, for Search"}
JSON.parse(response.body, symbolize_names: true)
# =>
# {:name=>"b3349dfab89f",
# :cluster_name=>"docker-cluster",
# ...
# :tagline=>"You Know, for Search"}
# We can also access the response keys directly, like the Elasticsearch::API:Response object returned by the Elasticsearch Ruby client:
response['name']
# => "b3349dfab89f"The README shows how to use the class methods to make requests quickly and the option to create a custom class. It would be more convenient to implement an Elasticsearch Client class and add the different API methods we'd like to use. Something like this for example:
class ESClient
include HTTParty
base_uri ENV['ES_LOCAL_url']
def initialize
@headers = {
'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}",
'Content-Type' => 'application/json'
}
end
def info
self.class.get('/', headers: @headers)
end
end
client = ESClient.new
puts client.infoWe don't want to re-implement Elasticsearch Ruby with HTTParty in this blog post, but this could be an alternative when using just a few of the APIs. We'll take a look at how to build the rest of the requests:
index = 'httparty-test'
# Create an index
response = HTTParty.put("#{host}/#{index}", headers: headers)
puts response
# {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"httparty-test"}
# Index a Document
document = { name: 'elasticsearch-ruby', description: 'Official Elasticsearch Ruby client' }.to_json
response = HTTParty.post("#{host}/#{index}/_doc", body: document, headers: headers)
# => {"_index"=>"httparty-test", "_id": ... }
# Save the id for following requests:
id = response["_id"]
# Get a document:
response = HTTParty.get("#{host}/#{index}/_doc/#{id}", headers: headers)
# => {"_index"=>"httparty-test", ..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}
# Search
search_body = { query: { match_all: {} } }.to_json
response = HTTParty.post("#{host}/#{index}/_search", body: search_body, headers: headers)
response['hits']['hits']
# => [{"_index"=>"httparty-test", ... ,"_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}]
# Update a document
document = { doc: { name: 'httparty-ruby', description: 'HTTParty Elasticsearch client' } }.to_json
response = HTTParty.post("#{host}/#{index}/_update/#{id}", body: document, headers: headers)
# => {"_index"=>"httparty-test", "_id" ... }
response.code
# => 200
# Deleting documents
response = HTTParty.delete("#{host}/#{index}/_doc/#{id}", headers: headers)
# => {"_index"=>"httparty-test", "_id" ... }
response.code
# => 200
# Deleting an index
response = HTTParty.delete("#{host}/#{index}", headers: headers)
# => {"acknowledged":true}excon
Excon was designed with the intention of being simple, fast and performant. It is particularly aimed at usage in API clients, so it is well suited for interacting with Elasticsearch. This code uses Excon version 0.111.0.
require 'bundler/inline'
require 'json'
gemfile do
source 'https://rubygems.org'
gem 'excon'
end
host = URI(ENV['ES_LOCAL_url'])
headers = {
'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}",
'Content-Type' => 'application/json'
}
response = Excon.get(host, headers: headers)
puts "Content-Type: #{response.headers['content-type']}"
puts "Response status: #{response.status}"
puts "Body: #{JSON.parse(response.body)}"
# Content-Type: application/json
# Response status: 200
# Body: {"name"=>"b3349dfab89f", "cluster_name"=>"docker-cluster", ..., "tagline"=>"You Know, for Search"}Excon requests return an Excon::Response object which has body, headers, remote_ip and status attributes. We can also access the data directly with the keys as symbols, similar to how Elasticsearch::API::Response works:
response[:headers]
# => {"X-elastic-product"=>"Elasticsearch", "content-type"=>"application/json", "content-length"=>"541"}We can reuse a connection across multiple requests to share options and improve performance. We can also use persistent connections to establish the socket connection with the initial request, and leave the socket open while we're running these examples:
connection = Excon.new(host, persistent: true, headers: headers)
index = 'excon-test'
# Create an index
response = connection.put(path: index)
puts response.body
# {"acknowledged":true,"shards_acknowledged":true,"index":"excon-test"}
# Index a Document
document = { name: 'elasticsearch-ruby', description: 'Official Elasticsearch Ruby client' }.to_json
response = connection.post(path: "#{index}/_doc", body: document)
puts response.body
# {"_index":"excon-test","_id" ... }
# Save the id for following requests:
id = JSON.parse(response.body)["_id"]
# Get a document:
response = connection.get(path: "#{index}/_doc/#{id}")
JSON.parse(response.body)
# => {"_index"=>"excon-test", ...,"_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}
# Search
search_body = { query: { match_all: {} } }.to_json
response = connection.post(path: "#{index}/_search", body: search_body)
JSON.parse(response.body)['hits']['hits']
# => [{"_index"=>"excon-test",..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}]
# Update a document
document = { doc: { name: 'excon-ruby', description: 'Excon Elasticsearch client' } }.to_json
response = connection.post(path: "#{index}/_update/#{id}", body: document)
# => <Excon::Response:0x0000...
response.status
# => 200
# Deleting documents
response = connection.delete(path: "#{index}/_doc/#{id}")
# => <Excon::Response:0x0000...
response.status
# => 200
# Deleting an index
response = connection.delete(path: index)
puts response.body
# {"acknowledged":true}
# Close connection
connection.resetHTTP (http.rb)
HTTP is an HTTP client which uses a chainable API similar to Python's Requests. It implements the HTTP protocol in Ruby and outsources the parsing to native extensions. The version used in this code is 5.2.0.
host = URI(ENV['ES_LOCAL_url'])
headers = {
'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}",
'Content-Type' => 'application/json'
}
HTTP.get(host, headers: headers)
response = HTTP.get(host, headers: headers)
# => <HTTP::Response/1.1 200 OK {"X-elastic-product"=>"Elasticsearch", "content-type"=>"application/json", "content-length"=>"541"}>
puts "Content-Type: #{response.headers['content-type']}"
puts "Response status: #{response.code}"
puts "Body: #{JSON.parse(response.body)}"
# Content-Type: application/json
# Response status: 200
# Body: {"name"=>"b3349dfab89f", ..., "tagline"=>"You Know, for Search"}We can also use the auth method to take advantage of the chainable API:
HTTP.auth(headers["Authorization"]).get(host)Or since we also care about the content type header, chain headers:
HTTP.headers(headers).get(host)With HTTP we can create a client with persistent connection to the host, and persist the headers too:
http = HTTP.persistent(host).headers(headers)So once we've created our persistent clients, it makes it shorter to build our requests:
# Create an index
index = 'http-test'
response = http.put("#{host}/#{index}")
response.parse
# => {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"http-test"}
# Index a Document
document = { name: 'elasticsearch-ruby', description: 'Official Elasticsearch Ruby client' }.to_json
response = http.post("#{host}/#{index}/_doc", body: document)
# => <HTTP::Response/1.1 201 Created {"Location"=>"/http-test/_doc/GCA1KZIBr7n-DzjRAVLZ", "X-elastic-product"=>"Elasticsearch", "content-type"=>"application/json", "content-length"=>"161"}>
response.parse
# => {"_index"=>"http-test", "_id" ...}
# Save the id for following requests:
id = response.parse['_id']
# Get a document:
response = http.get("#{host}/#{index}/_doc/#{id}")
# => <HTTP::Response/1.1 200 OK {"X-elastic-product"=>"Elasticsearch", "content-type"=>"application/json", "content-length"=>"198"}>
response.parse
# => {"_index"=>"http-test", "_id", ..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}
# Search
search_body = { query: { match_all: {} } }.to_json
response = http.post("#{host}/#{index}/_search", body: search_body)
# => <HTTP::Response/1.1 200 OK ...
response.parse['hits']['hits']
# => [{"_index"=>"http-test", "_id",..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}]
# Update a document
document = { doc: { name: 'http-ruby', description: 'HTTP Elasticsearch client' } }.to_json
response = http.post("#{host}/#{index}/_update/#{id}", body: document)
# => <HTTP::Response/1.1 200 OK ...
response.code
# => 200
response.flush
# Deleting documents
response = http.delete("#{host}/#{index}/_doc/#{id}")
# => <HTTP::Response/1.1 200 OK ...
response.code
# => 200
response.flush
# Deleting an index
response = http.delete("#{host}/#{index}")
# => <HTTP::Response/1.1 200 OK ...
response.parse
# => {"acknowledged"=>true}The documentation warns us that the response must be consumed before sending the next request in the persistent connection. That means calling to_s, parse, or flush on the response object.
Faraday
Faraday is the HTTP client library used by default by the Elasticsearch Client. It provides a common interface over many adapters which you can select when instantiating a client (Net::HTTP, Typhoeus, Patron, Excon and more). The version of Faraday used in this code was 2.12.0.
The signature for get is (url, params = nil, headers = nil) so we're passing nil for parameters in this initial test request:
require 'bundler/inline'
require 'json'
gemfile do
source 'https://rubygems.org'
gem 'faraday'
end
response = Faraday.get(host, nil, headers)
# => <Faraday::Response:0x0000...The response is a Faraday::Response object with the response status, headers, and body and we can also access lots of properties in a Faraday Env object. As we've seen with other libraries, the recommended way to use Faraday for our use case is to create a Faraday::Connection object:
conn = Faraday.new(
url: host,
headers: headers
)
response = conn.get('/')
puts "Content-Type: #{response.headers['content-type']}"
puts "Response status: #{response.code}"
puts "Body: #{JSON.parse(response.body)}"
# Content-Type: application/json
# Response status: 200
# Body: {"name"=>"b3349dfab89f", ..., "tagline"=>"You Know, for Search"}And now reusing that connection, we can see what the rest of the requests look like with Faraday:
index = 'faraday-test'
# Create an index
response = conn.put(index)
puts response.body
# {"acknowledged":true,"shards_acknowledged":true,"index":"faraday-test"}'
# Index a Document
document = { name: 'elasticsearch-ruby', description: 'Official Elasticsearch Ruby client' }.to_json
# The signature for post is (url, body = nil, headers = nil), unlike the get signature:
response = conn.post("#{index}/_doc", document)
puts response.body
# {"_index":"faraday-test","_id" ... }
# Save the id for following requests:
id = JSON.parse(response.body)["_id"]
# Get a document:
response = conn.get("#{index}/_doc/#{id}")
JSON.parse(response.body)
# => {"_index"=>"faraday-test", ...,"_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}
# Search
search_body = { query: { match_all: {} } }.to_json
response = conn.post("#{index}/_search", search_body)
JSON.parse(response.body)['hits']['hits']
# => [{"_index"=>"faraday-test", ..., "_source"=>{"name"=>"elasticsearch-ruby", "description"=>"Official Elasticsearch Ruby client"}}]
# Update a document
document = { doc: { name: 'faraday-ruby', description: 'Faraday client' } }.to_json
response = conn.post("#{index}/_update/#{id}", document)
# => <Faraday::Response:0x0000...
response.status
# => 200
# Deleting documents
response = conn.delete("#{index}/_doc/#{id}")
# => <Excon::Response:0x0000...
response.status
# => 200
# Deleting an index
response = conn.delete(index)
puts response.body
# {"acknowledged":true}Elastic Transport
The library elastic-transport is the Ruby gem that deals with performing HTTP requests, encoding, compression, etc. in the official Elastic Ruby clients. This library has been battle tested for years against every official version of Elasticsearch. It used to be known as elasticsearch-transport as it was the base for the official Elasticsearch client. However in version 8.0.0 of the client, we migrated the transport library to elastic-transport since it was also supporting the official Enterprise Search Client and more recently the Elasticsearch Serverless Client.
It uses a Faraday implementation by default, which supports several different adapters as we saw earlier. You can also use Manticore and Curb (the Ruby binding for libcurl) implementations included with the library. You can even write your own, or an implementation with some of the libraries we've gone through here. But that would be the subject for a different blog post!
Elastic Transport can also be used as an HTTP library to interact with Elasticsearch. It will deal with everything you need and has a lot of settings and different configurations related to the use at Elastic. The version used here is the latest 8.3.5. A simple example:
require 'bundler/inline'
gemfile do
source 'https://rubygems.org'
gem 'elastic-transport'
end
host = URI(ENV['ES_LOCAL_url'])
headers = { 'Authorization' => "ApiKey #{ENV['ES_LOCAL_API_KEY']}" }
# Instantiate a new Transport client
transport = Elastic::Transport::Client.new(hosts: host)
# Make a request to the root path ('info') to make sure we can connect:
response = transport.perform_request('GET', '/', {}, nil, headers)
# Create an index
index = 'elastic-transport_docs'
response = transport.perform_request('PUT', "/#{index}", {}, nil, headers)
response.body
# => {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"elastic-transport_docs"}
# Index a document
document = { name: 'elastic-transport', description: 'Official Elastic Ruby HTTP transport layer' }.to_json
response = transport.perform_request('POST', "/#{index}/_doc", {}, document, headers)
response.body
# => {"_index"=>"elastic-transport_docs", "_id"=> ... }
# Get the document we just indexed
id = response.body['_id']
response = transport.perform_request('GET', "/#{index}/_doc/#{id}", {}, nil, headers)
response.body['_source']
# => {"name"=>"elastic-transport", "description"=>"Official Elastic Ruby HTTP transport layer"}
# Search for a document
search_body = { query: { match_all: {} } }
response = transport.perform_request('POST', "/#{index}/_search", {}, search_body, headers)
response.body.dig('hits', 'hits').first
# => {"_index"=>"elastic-transport_docs", ..., "_source"=>{"name"=>"elastic-transport", "description"=>"Official Elastic Ruby HTTP transport layer"}}
# Update the document
body = { doc: { name: 'elastic-transport', description: 'Official Elastic Ruby HTTP transport layer.' } }.to_json
response = transport.perform_request('POST', "/#{index}/_update/#{id}", {}, body, headers)
response.body
# => {"_index"=>"elastic-transport_docs", ... }
# Delete a document
response = transport.perform_request('DELETE', "/#{index}/_doc/#{id}", {}, nil, headers)
response.body
# => {"_index"=>"elastic-transport_docs", ... }Conclusion
As you can see, the Elasticsearch Ruby client does a lot of work to make it easy to interact with Elasticsearch in your Ruby code. We didn't even go too deep in this blog post working with more complex requests or handling errors. But Elasticsearch's REST API makes it possible to use it with any library that supports HTTP requests, in Ruby and any other language. The Elasticsearch REST APIs guide is a great reference to learn more about the available APIs and how to use them.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 17, 2024
Unlock the Power of Your Data with RAG using Vertex AI and Elasticsearch
Unlock your data's potential with RAG using Vertex AI and Elasticsearch. This blog series covers data ingestion into Elasticsearch for a robust knowledge base for creating advanced RAG based search applications.
October 11, 2024
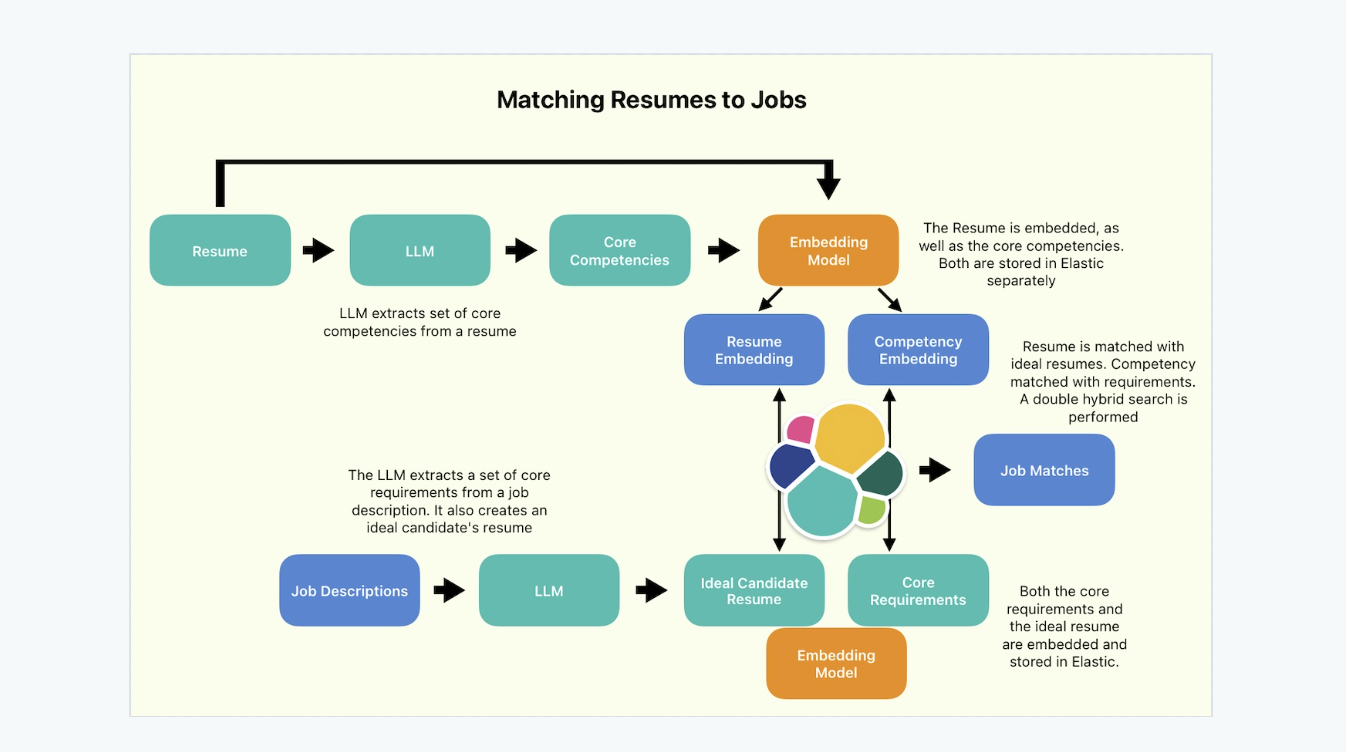
Which job is the best for you? Using LLMs and semantic_text to match resumes to jobs
Learn how to use Elastic's LLM Inference API to process job descriptions, and run a double hybrid search to find the most suitable job for your resume.
October 10, 2024
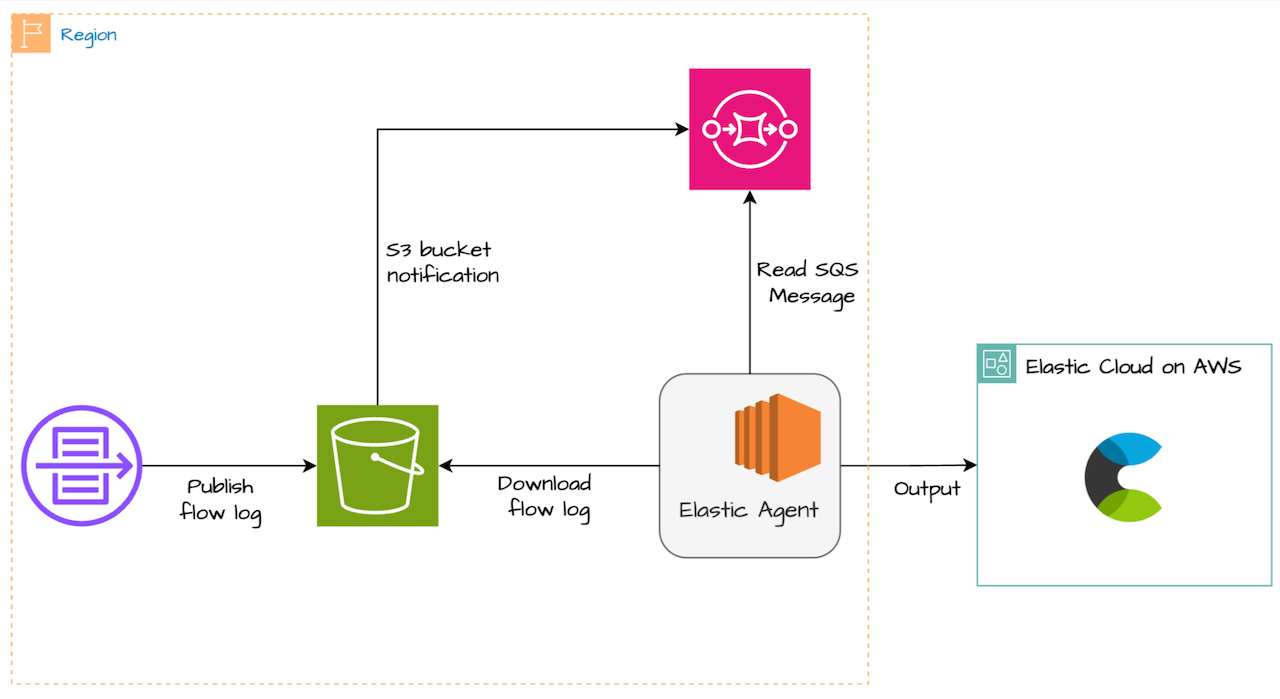
How to ingest data from AWS S3 into Elastic Cloud - Part 2 : Elastic Agent
Learn about different options to ingest data from AWS S3 into Elastic Cloud.
October 9, 2024
Building a search app with Blazor and Elasticsearch
Learn how to build a search application using Blazor and Elasticsearch, and how to use the Elasticsearch .NET client for hybrid search.

October 8, 2024
LangChain4j with Elasticsearch as the embedding store
LangChain4j (LangChain for Java) has Elasticsearch as an embedding store. Discover how to use it to build your RAG application in plain Java.