About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Enhancing RAG performance with smart chunking strategies
Explore various chunking strategies and their impact on data retrieval efficiency in retrieval-augmented generation (RAG) systems
Retrieval-augmented generation (RAG) enhances large language model (LLM) responses by incorporating external knowledge sources, improving accuracy and relevance.
In enterprise applications, RAG systems typically rely on external sources like product search engines or vector databases. When using vector databases, the process includes:
- Content segmentation (Chunking): Breaking down large text documents into smaller, manageable pieces.
- Vectorization: Converting these chunks into numerical representations (vectors) for machine learning algorithms.
- Vector database indexing: Storing vectors in a specialized database optimized for similarity search.
- Retrieval and prompting: Fetching the most relevant chunks to generate LLM responses.
The effectiveness of a RAG system depends on the quality of retrieved data. The principle of garbage in, garbage out applies—poorly segmented data leads to suboptimal results. This is where chunking becomes critical, optimizing storage, retrieval, and processing efficiency.
Various chunking strategies exist, each with different implications for data retrieval. While basic methods work in simple scenarios, complex applications such as conversational AI, demand more sophisticated, data-driven approaches. This article explores common chunking techniques, their limitations, and how tailored strategies can improve retrieval performance.
Importance of chunking
Chunking plays a key role in improving the efficiency and accuracy of data retrieval, especially when working with large datasets. Its benefits include:
- Maintaining context within token limits: Since LLMs have token constraints, chunking ensures relevant and complete information is provided while staying within these limits.
- Preserving contextual relationships: Well-structured chunks retain the logical flow of information, improving representation and understanding.
- Enhancing scalability: Chunking enables efficient processing of large datasets, making indexing and retrieval more manageable.
- Speeding up retrieval: Optimized chunks allow for faster, more accurate search results, improving overall system performance.
Common chunking strategies
Here are some widely used chunking methods implemented using the LangChain library.
1. Fixed-length chunking
This method splits text into chunks of a predefined length, regardless of sentence structure or meaning. It is useful for processing text in smaller, manageable parts.
Example:
from langchain.text_splitter import CharacterTextSplitter
# Sample text to be chunked
text = """some large text"""
# Initialize CharacterTextSplitter with a fixed chunk size (100 characters) and overlap (10 characters)
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10)
# Split the text into fixed-length chunks
chunks = splitter.split_text(text)
Fixed-length chunking using CharacterTextSplitter from LangChain, with a chunk size of 100 and an overlap of 10.
Limitations:
- May break sentences or phrases in the middle, leading to loss of context.
2. Section-based chunking
This method splits a document into meaningful sections based on natural boundaries like paragraphs, subheadings, or sentence breaks. By preserving the document's structure, section-based chunking helps maintain context within each chunk.
Example:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Sample long text extracted from a document
text = "<long text extracted from docs>"
# Initialize RecursiveCharacterTextSplitter with a chunk size of 100 and overlap of 10
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=10)
# Split the text into structured chunks
text_splitter.create_documents([text])
LangChain's RecursiveCharacterTextSplitter allows defining specific separators (such as paragraphs or punctuation) for splitting.
Limitations:
- Sections are often based on document structure (e.g., headings, paragraphs), which may not always align with true semantic boundaries.
- Smaller, more precise chunks might not be achievable, making retrieval less effective for fine-grained queries.
3. Sentence chunking
Sentence chunking involves splitting text into individual sentences to maintain context and structure for tasks like embedding or natural language processing (NLP). This approach ensures that each chunk represents a complete thought, improving retrieval and comprehension. Libraries like NLTK, spaCy, and LangChain offer tools for effective sentence-based chunking.
Example: Using LangChain’s SpaCyTextSplitter
from langchain.text_splitter import SpacyTextSplitter
# Sample text
text = "..."
# Initialize sentence splitter
text_splitter = SpacyTextSplitter()
# Split text into sentence-level chunks
docs = text_splitter.split_text(text)
Limitations:
- Sentence lengths can vary, leading to inconsistencies in chunk sizes.
- Very short sentences may create overly small chunks, reducing efficiency.
4. Semantic chunking
Semantic chunking divides text into meaningful segments based on its actual content and relationships between words or phrases. Unlike fixed-length or sentence-based chunking, this method ensures that each chunk retains context and relevance, improving retrieval and processing accuracy.
Example:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_experimental.text_splitter import SemanticChunker
# This is a long text document we can split up.
text_file_path = “file path”
with open(text_file_path) as f:
text_data = f.read()
# Initialize the HuggingFace embeddings model
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# Initialize the SemanticChunker with the embedding model
text_splitter = SemanticChunker(embedding_model=embedding_model)
docs = text_splitter.create_documents([text_data])
print(docs[0].page_content)
Limitations:
- Relies on embeddings or language models (LLMs) to determine meaningful splits, making it computationally expensive.
- Processing large documents can be time-consuming.
The pitfalls of traditional chunking
While standard chunking methods work in many cases, they come with limitations that affect retrieval quality and efficiency.
Loss of context and logical flow: Fixed-length and sentence-based chunking can split content arbitrarily, cutting across sentences and disrupting logical flow.
Dependency on structured content: Section-based chunking relies on clear delimiters like headers and subheadings, which may not be present in unstructured data (e.g., conversational logs, voice transcripts).
Inconsistent chunk sizes: Fixed-length chunking struggles with varying text lengths. Section-based chunking may produce chunks that are too large or too small, leading to incomplete or imbalanced context.
Computational overhead in semantic chunking: Requires NLP models or embeddings, making it resource-intensive. May struggle with ambiguous or overlapping topics if thresholds are not properly configured.
Ineffective for unstructured or conversational data: Traditional chunking assumes structured content and fails for data sources with no clear formatting (e.g., chat transcripts). Conversations often span multiple exchanges, making retrieval challenging.
How chunk size affects retrieval performance
Chunk size plays a crucial role in determining retrieval accuracy and system efficiency. Well-balanced chunking ensures relevant results in retrieval-augmented generation (RAG) systems. However, uneven chunk sizes can lead to biases, where smaller chunks may dominate retrieval, even if they are less semantically relevant. This happens because retrieval systems often prioritize dense, keyword-matching chunks over larger, context-rich ones.
Key observations
Small Chunks
- Enable fine-grained retrieval and keyword matching.
- Often lack the broader context needed for meaningful responses.
Large chunks
- Preserve more context, improving coherence.
- Can dilute specific matches and increase token usage in LLM calls.
Uneven Chunks
- Create retrieval imbalances, where smaller chunks may be over-prioritized.
- Larger, more contextually relevant chunks may be overlooked.
Data-driven chunking strategies
Data-driven chunking adapts the text-splitting process based on the structure and type of content within a document. Different content types—such as code, tables, markdown, and plain text—require specialized chunking techniques to maintain their integrity and meaning.
1. Adaptive document chunking
Adaptive chunking ensures that structured content, like code snippets, tables, or markdown documents, is preserved in a meaningful way. This prevents breaking important relationships within the data and improves retrieval efficiency.
Example 1: Chunking markdown documents
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = "Some markdown format"
# Splitting based on markdown headers
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
Preserves markdown structure by splitting based on headers.
Example 2: Chunking python code
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.text_splitter import Language
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
Preserves syntax structure while chunking Python code.
Example 3: Extracting and chunking tables from PDFs
import pdfplumber
def extract_and_chunk_tables(pdf_path, chunk_size=5):
with pdfplumber.open(pdf_path) as pdf:
return [
[table[i:i + chunk_size] for i in range(0, len(table), chunk_size)]
for page in pdf.pages
for table in page.extract_tables() if table
]
# Example usage
chunked_tables = extract_and_chunk_tables("sample_document.pdf")
Ensures tables remain intact when extracting from PDFs.
2. Timestamp-based chunking
When dealing with conversational data from sources like Slack messages, system logs, or chat transcripts, traditional chunking methods often fail to capture the natural flow of interactions. Conversations are context-dependent, meaning the relevance of a message is often tied to previous messages and their timestamps.
Timestamp-based chunking groups messages based on specific time intervals (e.g., every 5 minutes, per session, or within an hour). This ensures that chunks retain contextual continuity, making them more effective for retrieval and analysis.
Example: Chunking slack conversations
Consider a Slack conversation where messages appear at varying intervals. To maintain context, we can segment messages into 5-minute chunks.
from datetime import datetime, timedelta
# Sample message data with timestamps
messages = [
{"timestamp": "2024-12-14 08:01:00", "message": "Hi there! How can I help?"},
{"timestamp": "2024-12-14 08:02:45", "message": "I need assistance with my account."},
{"timestamp": "2024-12-14 08:07:30", "message": "Sure, I can help. What's the issue?"}
]
# Convert string timestamps to datetime objects
for msg in messages:
msg["timestamp"] = datetime.strptime(msg["timestamp"], "%Y-%m-%d %H:%M:%S")
# Function to chunk messages based on a time interval
def chunk_by_timestamp(messages, interval_minutes=5):
chunks, current_chunk, chunk_start_time = [], [], None
for msg in messages:
if not current_chunk:
current_chunk.append(msg)
chunk_start_time = msg["timestamp"]
else:
# Check if the message falls within the specified time interval
if (msg["timestamp"] - chunk_start_time).seconds <= interval_minutes * 60:
current_chunk.append(msg)
else:
chunks.append(current_chunk)
current_chunk = [msg]
chunk_start_time = msg["timestamp"]
# Add the last chunk
if current_chunk:
chunks.append(current_chunk)
return chunks
# Apply timestamp-based chunking
chunked_messages = chunk_by_timestamp(messages, interval_minutes=5)
Groups messages that occur within the same 5-minute window, preserving conversation flow.
Optimizing chunks post-retrieval: Contextual compression
When dealing with large, dense datasets like support ticket conversations, system logs, or chat transcripts, retrieving relevant information efficiently can be challenging. These data sources often contain redundant or verbose content, making retrieval and processing less effective.
Regardless of the chunking strategy used (section-based, sentence-based, or semantic), excessive chunk generation can lead to cluttered and irrelevant results.
How contextual compression helps
Contextual compression optimizes retrieved chunks by filtering and summarizing content based on query relevance. Instead of passing all retrieved chunks to an LLM, this approach dynamically combines and condenses information, ensuring only the most relevant content is used.
Benefits:
- Reduces the number of chunks passed to the LLM, lowering cost and latency.
- Improves response quality by eliminating unnecessary or redundant data.
- Ensures concise and contextually rich inputs for better retrieval performance.
See the following diagram for a visual representation of this process:
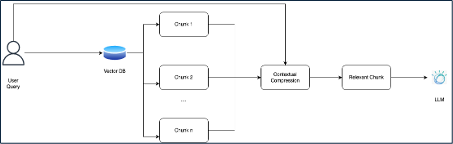
Note: For code and more details about contextual compression, see LangChain documentation.
Conclusion
Effective chunking is a blend of art and science. By understanding the specific nature of the data and selecting the right chunking strategy, developers can greatly improve the performance of vectorization systems. Whether using semantic chunking for documents or timestamp-based chunking for conversational data, the goal is to strike a balance between maintaining contextual relevance and ensuring computational efficiency.
Ready to get hands on implementing these chunking strategies? Check out this tutorial, "Implementing RAG chunking strategies with LangChain and watsonx.ai."