About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Build context-aware AI agents with watsonx Orchestrate and Astra db
AI agents are only as effective as their data, making precise retrieval essential for reliable results.
On this page
Retrieval augmented generation (RAG) combines retrieval-based and generative AI techniques for large language models (LLMs) to access and use relevant external information and produce accurate, context-aware responses. However, RAG’s effectiveness depends on retrieving the right context for each specific task.
In this tutorial, explore how to use IBM watsonx Orchestrate and DataStax Astra db to build an agentic RAG system that delivers contextually relevant answers about HR employee benefits. The AI agent uses documents that are extracted from the website and stored in Astra db. When the user asks a question, the AI agent reformulates the question to find the most relevant documents and uses that context to generate an accurate answer.
This tutorial demonstrates how AI agents improve a basic RAG workflow and how the right data store helps retrieve the most relevant content for each query.
Prerequisites
A trial instance of watsonx Orchestrate SaaS:
Learn more about registering for the trial instance and getting logged in to watsonx Orchestrate in their docs:
Steps
Step 1. Set up Astra db
Create a DataStax Astra db account and set up a new database.
Go to the DataStax Astra db website and sign up for an account.
Note: Each user receives $25 in monthly credits for Astra db, Astra Streaming, and Langflow.
In the Astra Databases dashboard, click Create database.
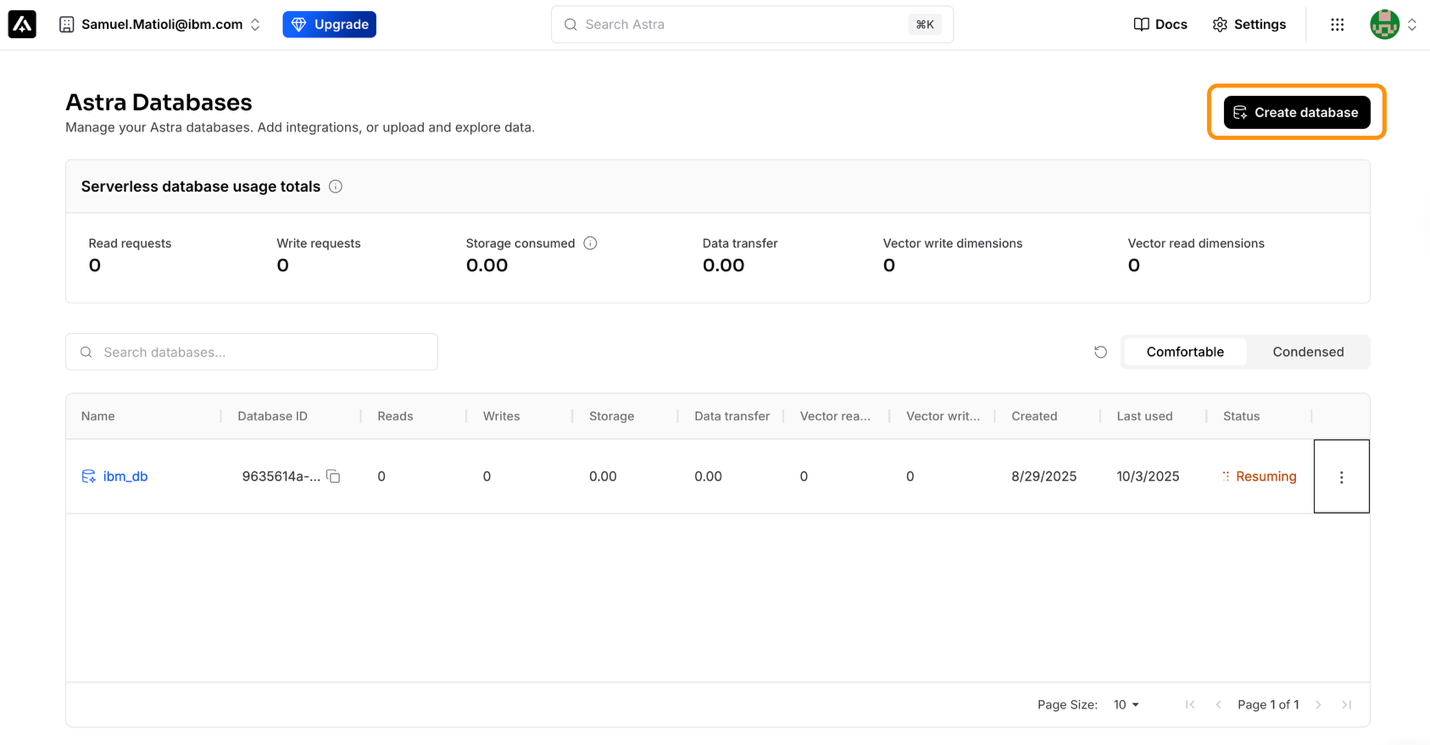
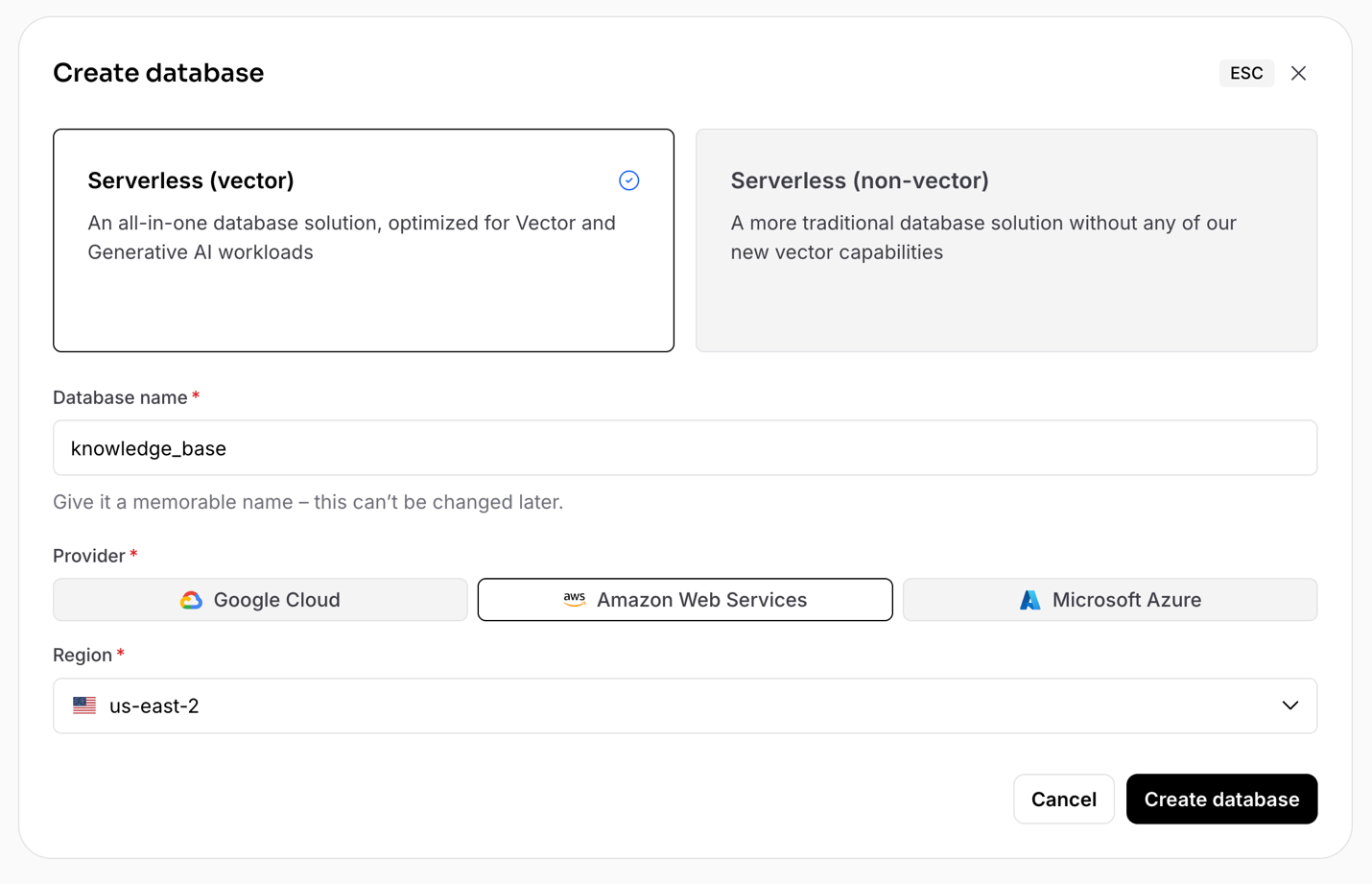
Enter the following details and click Create database.
- Database type: Serverless (vector)
- Database name:
knowledge_base - Provider: Amazon Web Services
Region: us-east-2
After a few minutes, your database will be ready.
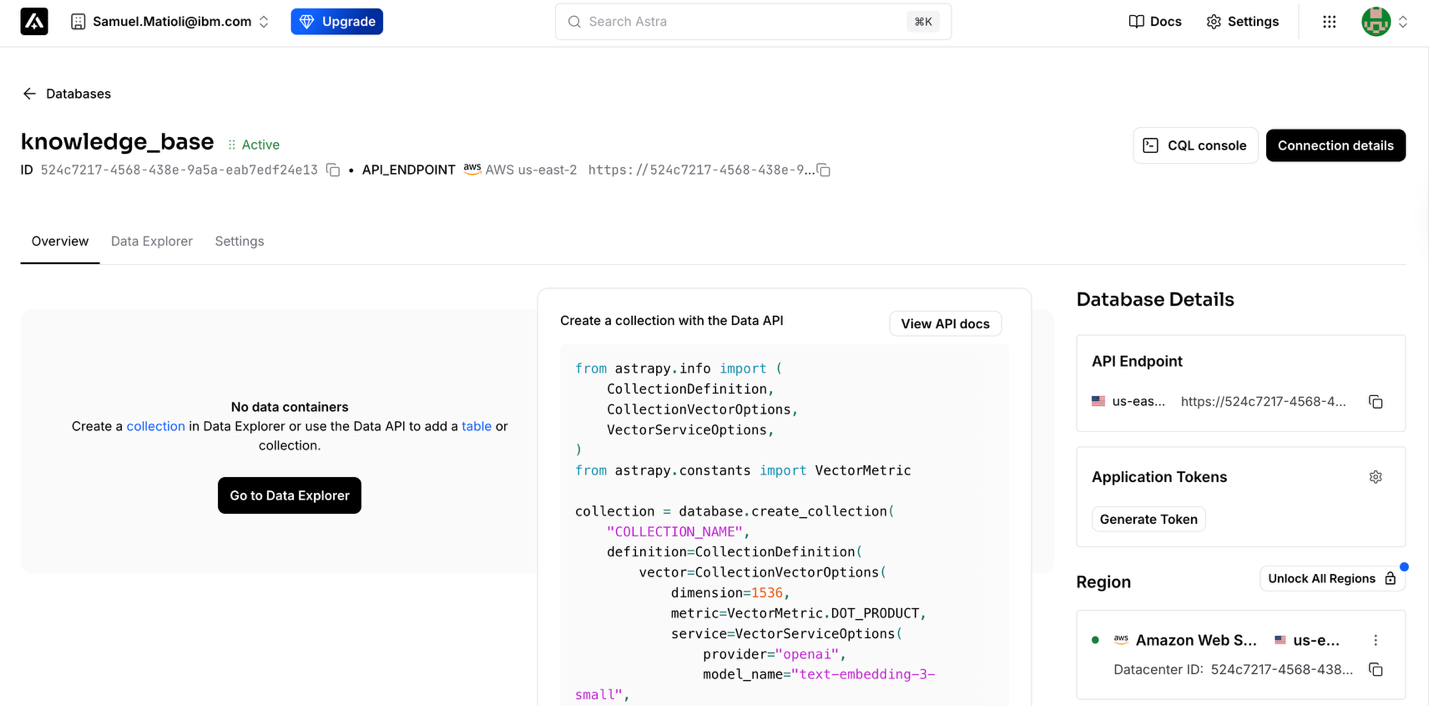
Step 2. Create a document collection
Create a collection to store documents and their embeddings for similarity searches.
Astra db uses Vectorize, which automatically generates embeddings through providers such as NVIDIA, OpenAI, and Hugging Face. This tutorial uses the nvidia/nv-embedqa-e5-v5 model.
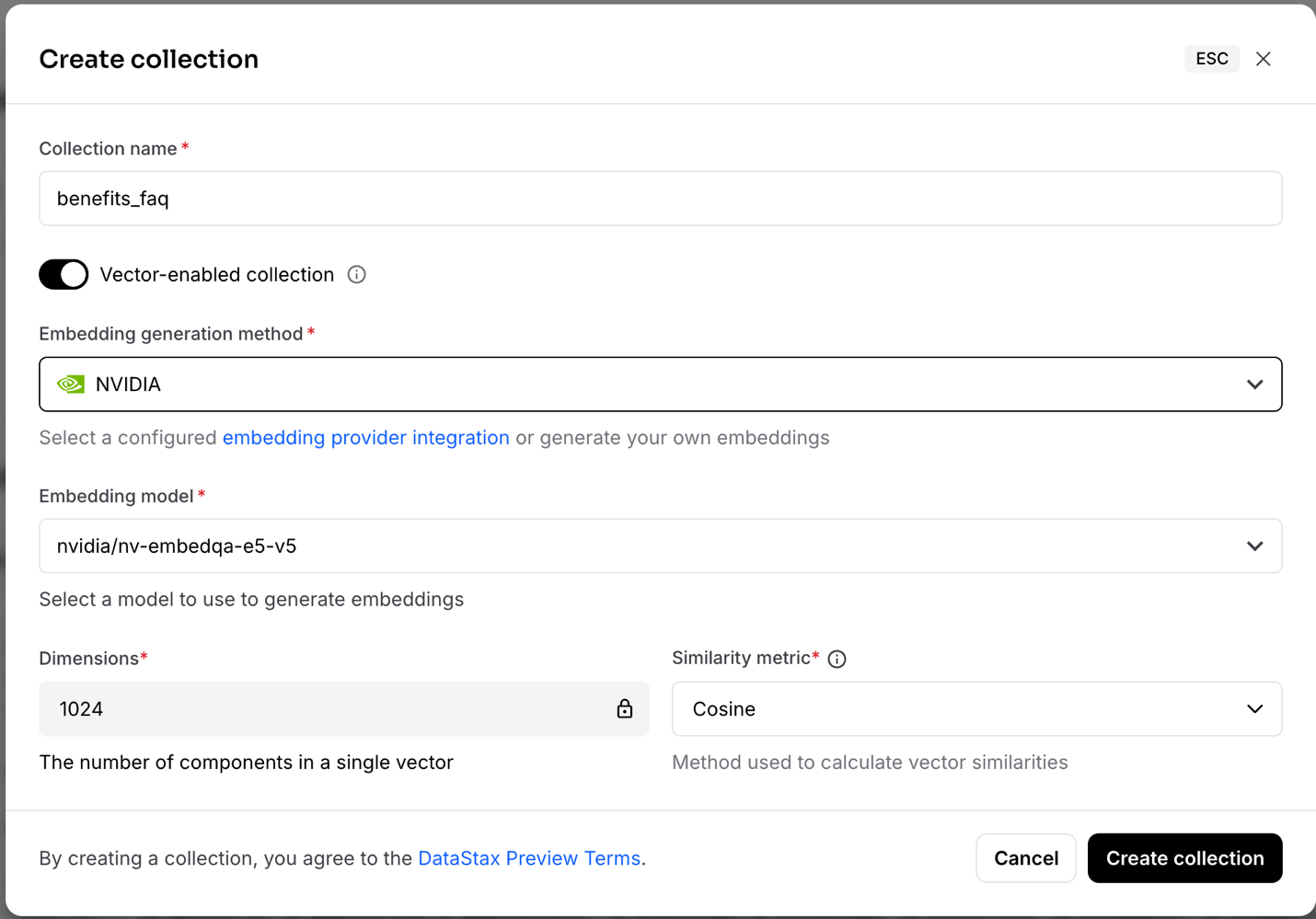
In the Astra db database that you created, click Go to Data Explorer, and click Create collection→Empty collection.
Enter the following details and click Create collection.
- Collection name: benefits_faq
- Vector-enabled collection: Yes
- Embedding generation method: NVIDIA
- Embedding model: nvidia/nv-embedqa-e5-v5
- Similarity metric: Cosine
Step 3. Load data into Astra db
Upload the document to your collection and prepare it for retrieval.
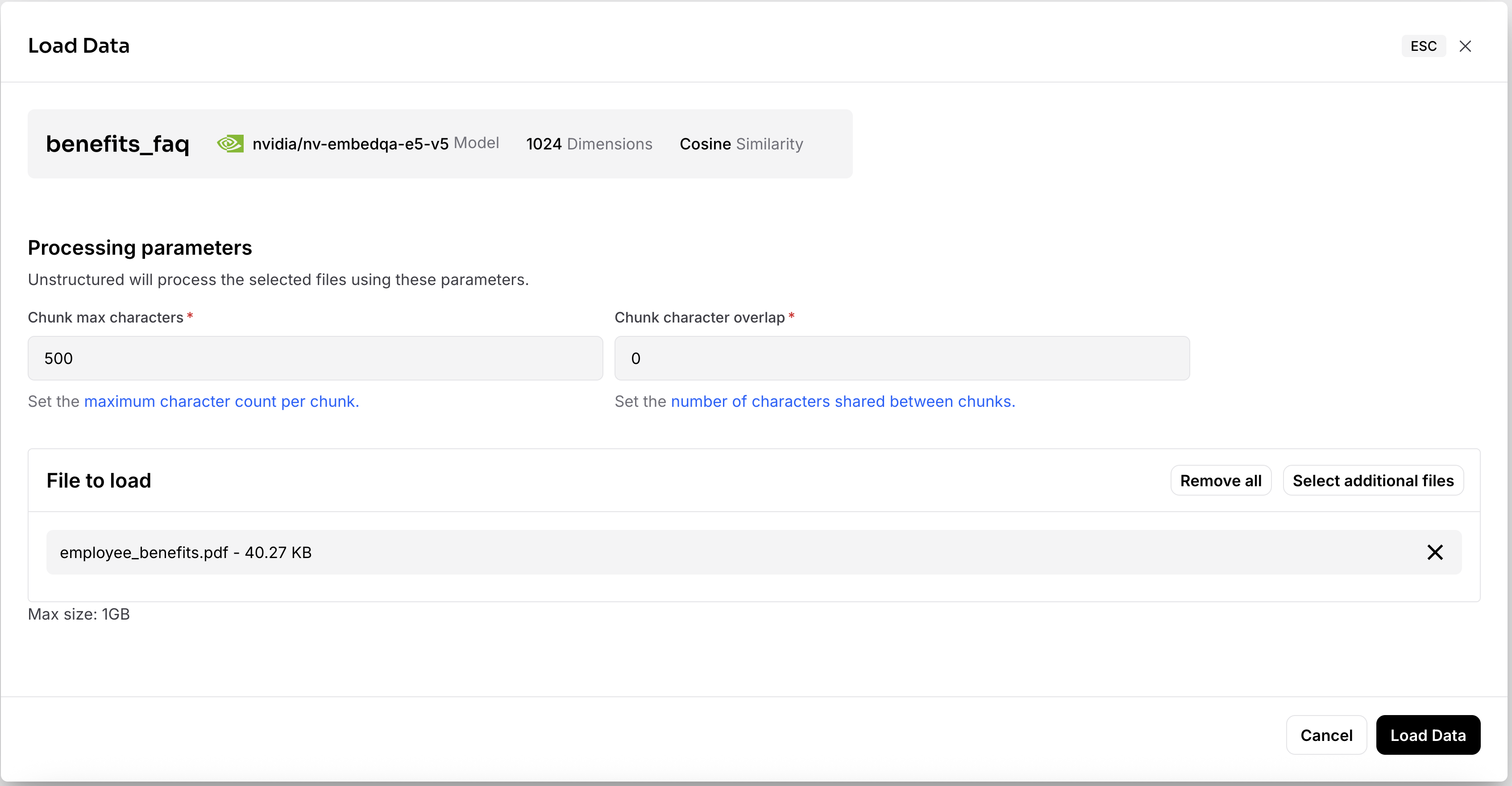
From the Collection list, select the benefits_faq collection, and then click Load data.
Download the employee benefits PDF.
In the Astra db Load Data screen, click Select files and upload the downloaded file.
Set Chunk max characters to 500 and Chunk character overlap to 100, and then click Load Data.
After the processing completes, each chunk has an ID (_id), the content is stored in the
$vectorizeattribute, and the embeddings is stored in the$vectorattribute.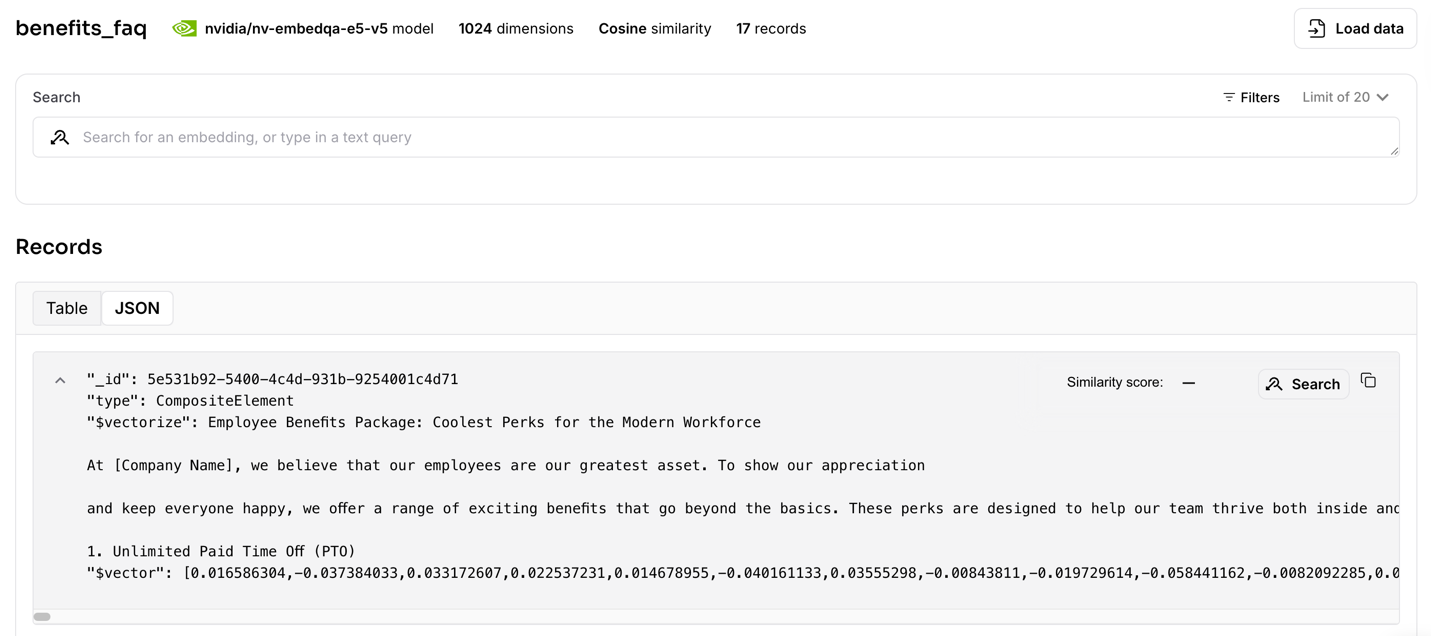
Step 4. Create an agent in watsonx Orchestrate
From the main menu in watsonx Orchestrate, click Build→Agent Builder.
In the Build agents and tools page, click Create agent.
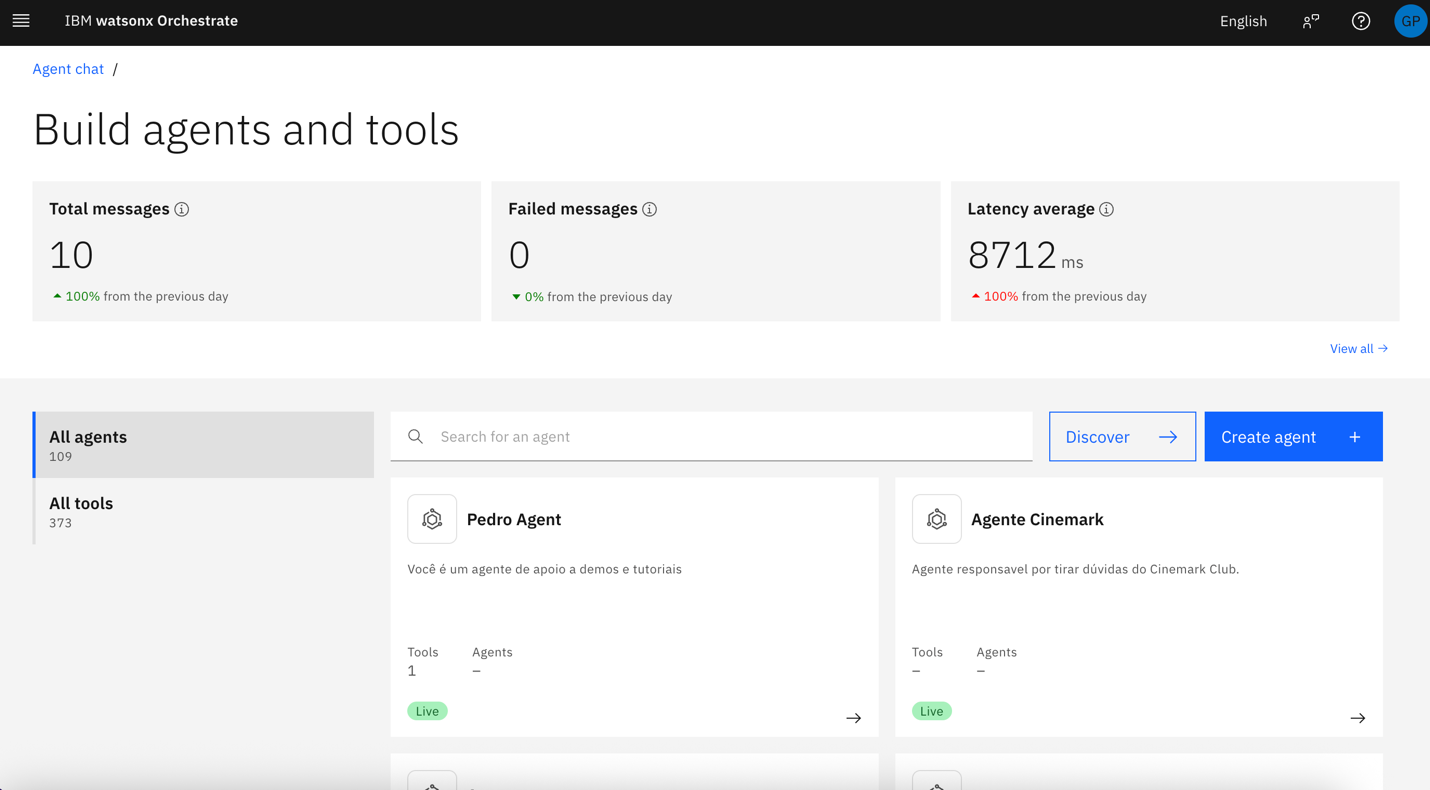
Keep the Create from scratch option selected, enter the following details, and then click Create.
- Name: Employee Helper Agent
Description: You are an AI assistant specialized in Employee Benefits. Your goal is to provide clear, accurate, and up-to-date information about benefits, based on the knowledge stored in Astra db.
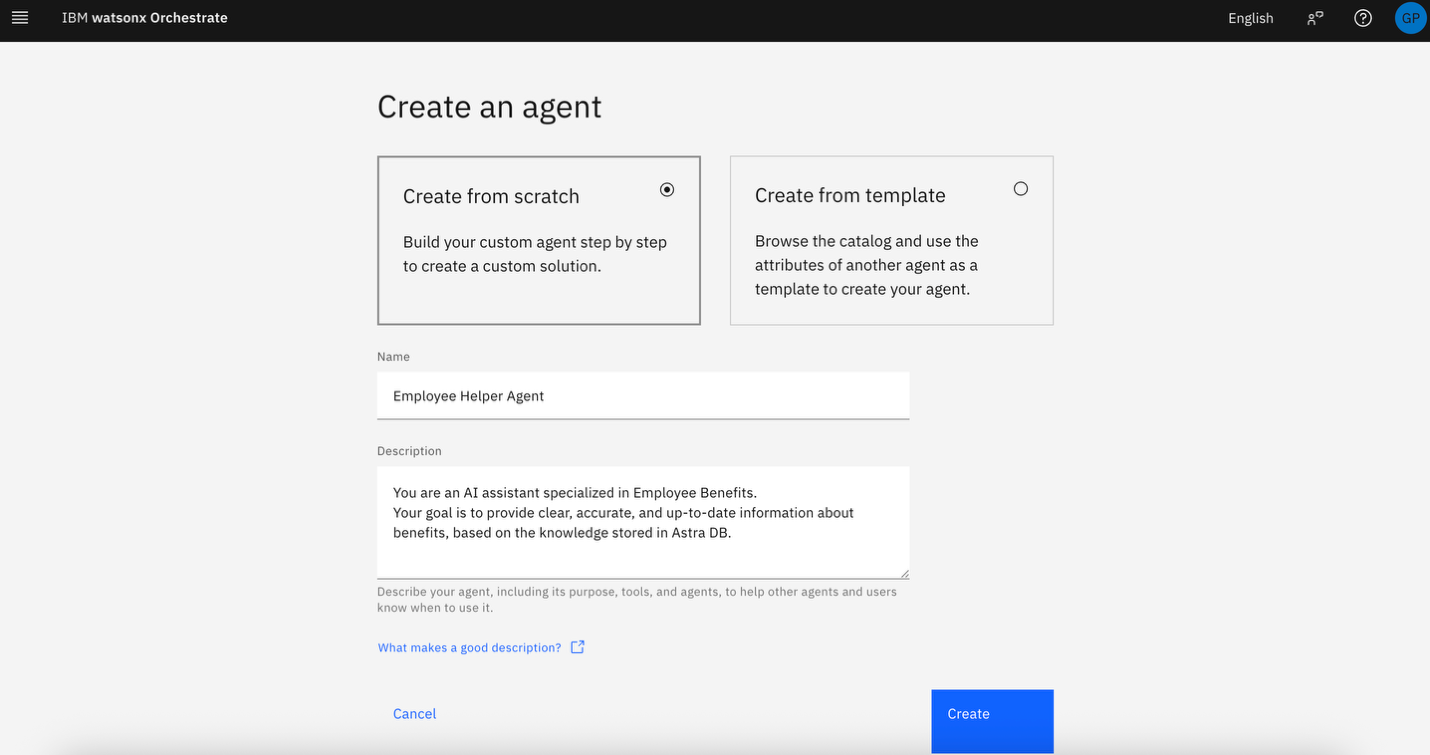
The agent builder is displayed with a chat window for testing the agent.
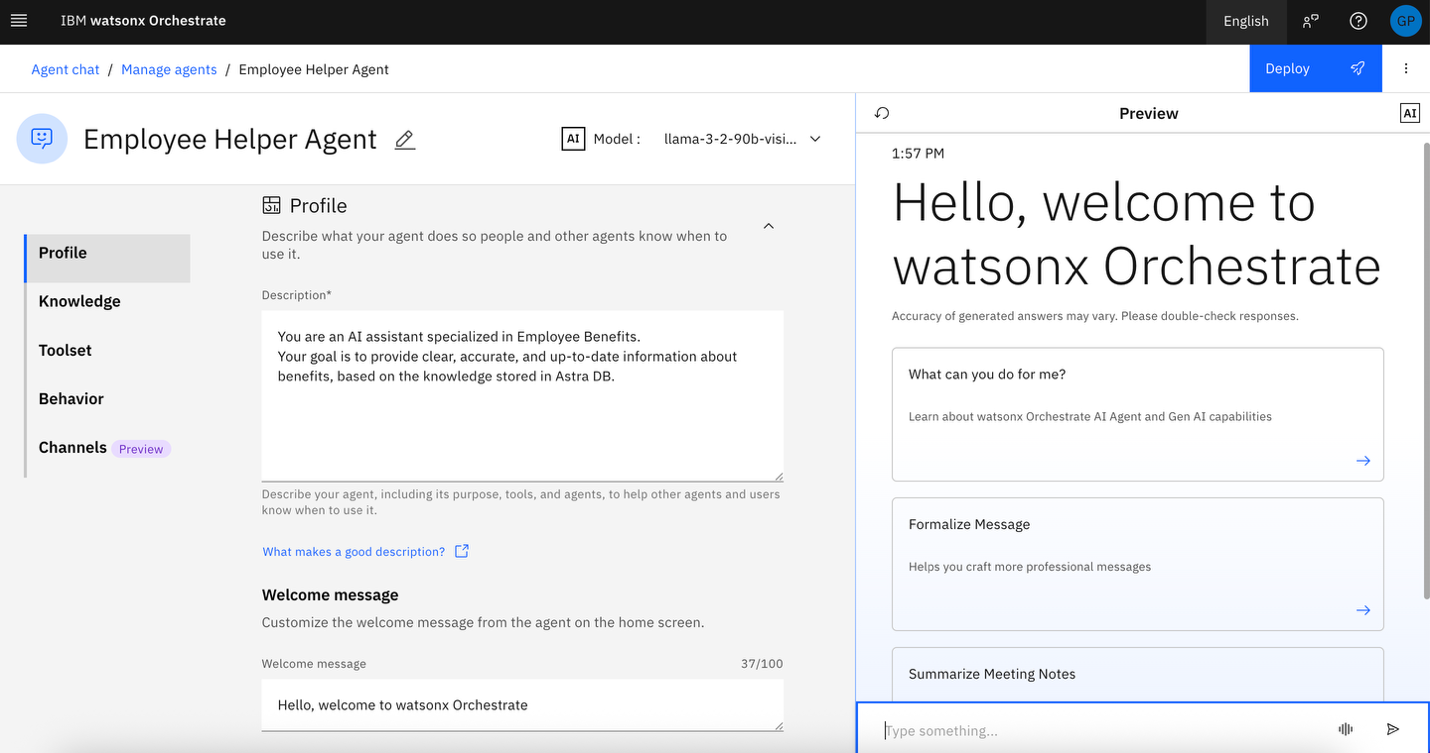
In the Welcome message, replace the default text with:
Welcome, I am HR Agent
Add the following example questions in the Quick start prompt section:
- What kind of employee benefits does the company offer?
- How does the 4-day workweek contribute to work-life balance?
- How do the company’s benefits reflect its values?
Keep the Agent style and Agent voice settings unchanged.
Click the refresh icon at the upper left of the chat window to preview your agent.
Step 5. Connect Astra db as the knowledge base
In the navigation, click the Knowledge tab, and then click Choose knowledge.
Select Astra db, then click Next.
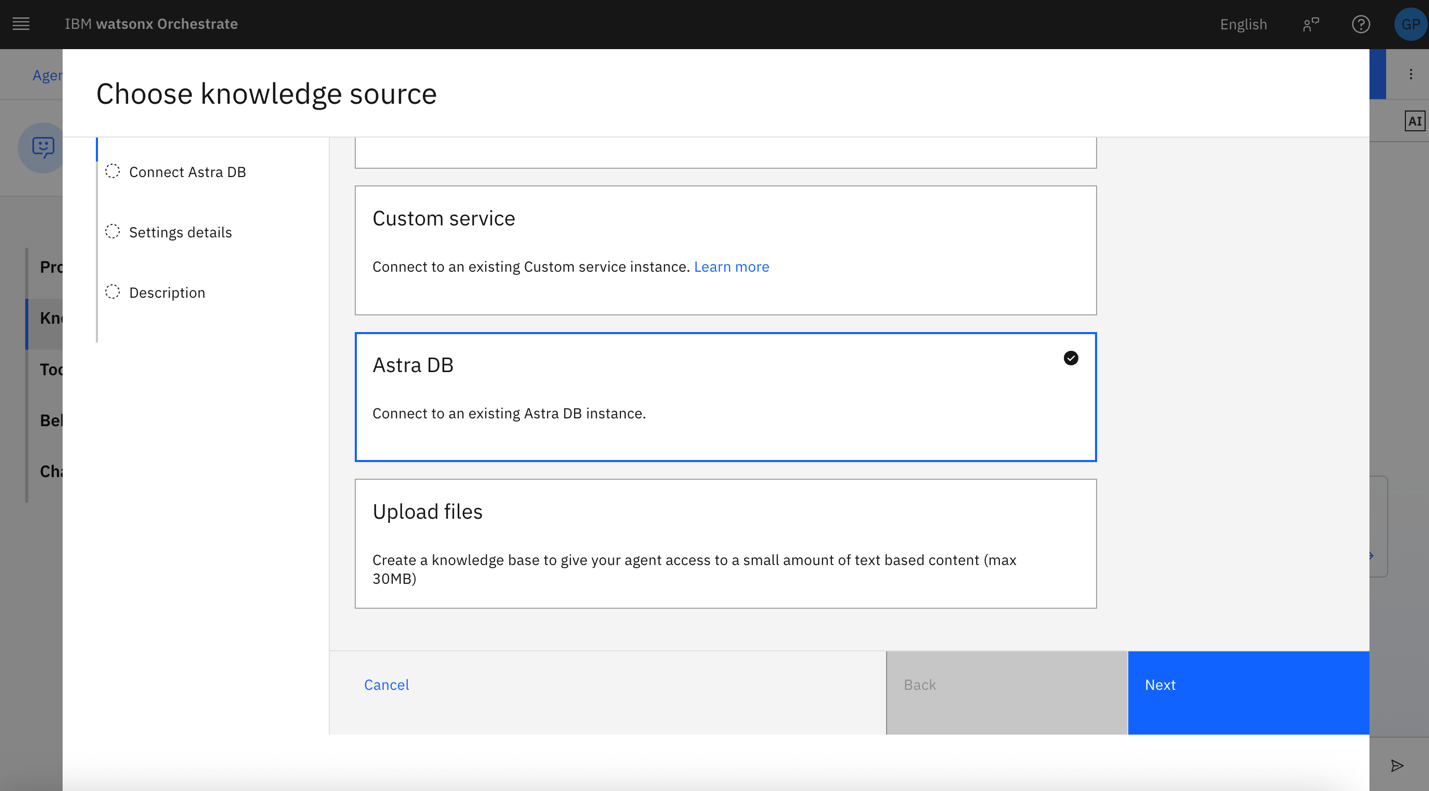
Enter the URL and API key of your Astra db account and click Next.
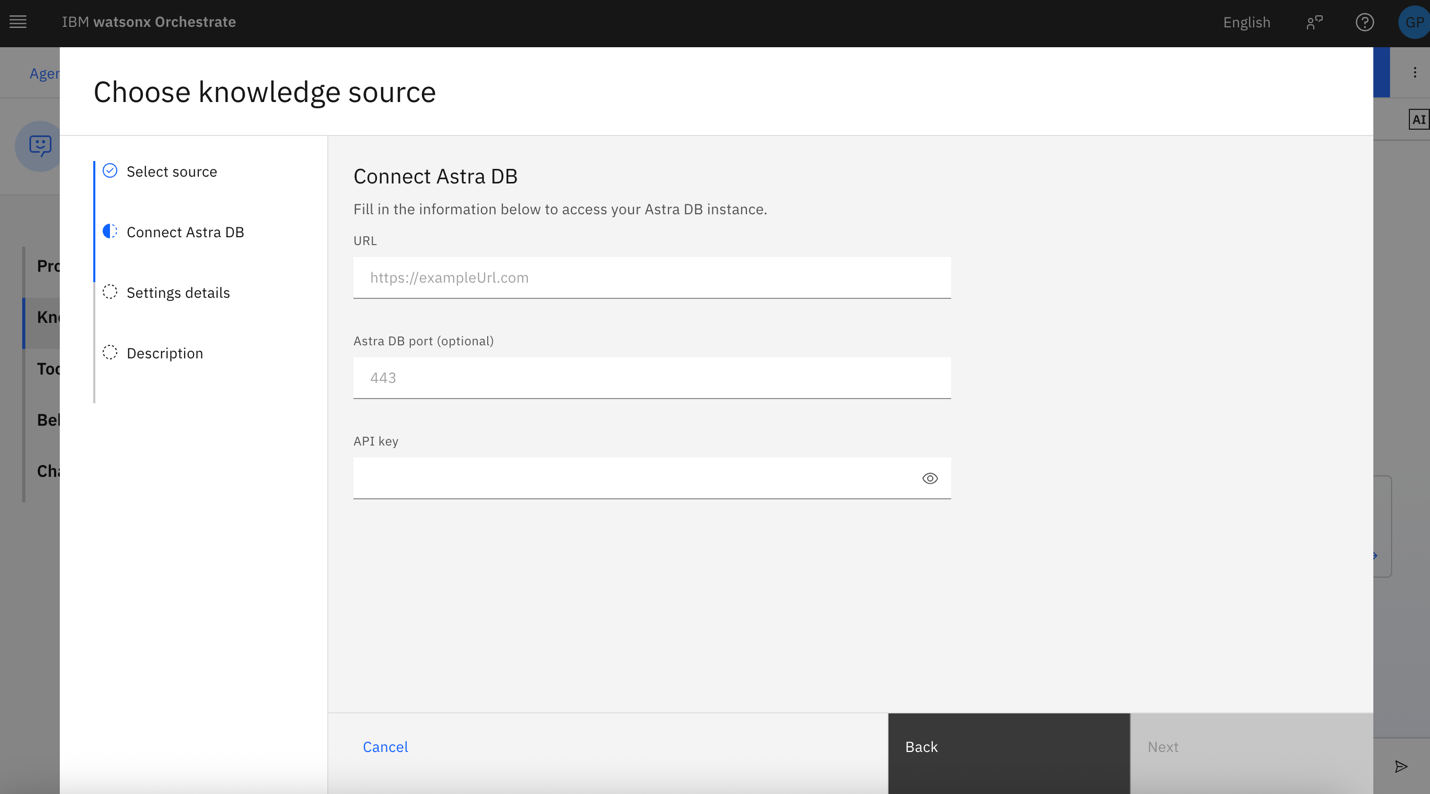
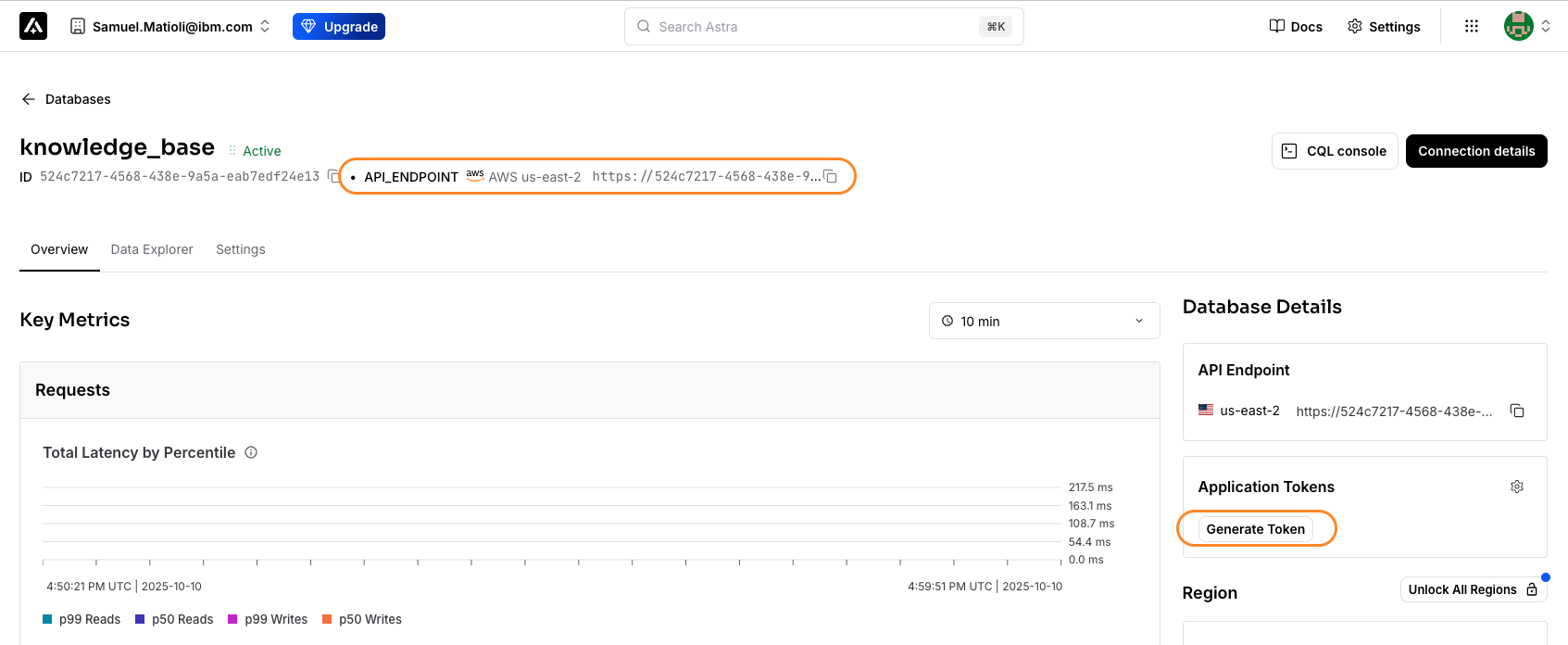
Note: To find the URL and the API Key, open the Astra db Dashboard, access the database that you created in Step 1, then copy the API_ENDPOINT URL that is under the database name. Next, click Generate Token to create an API key.
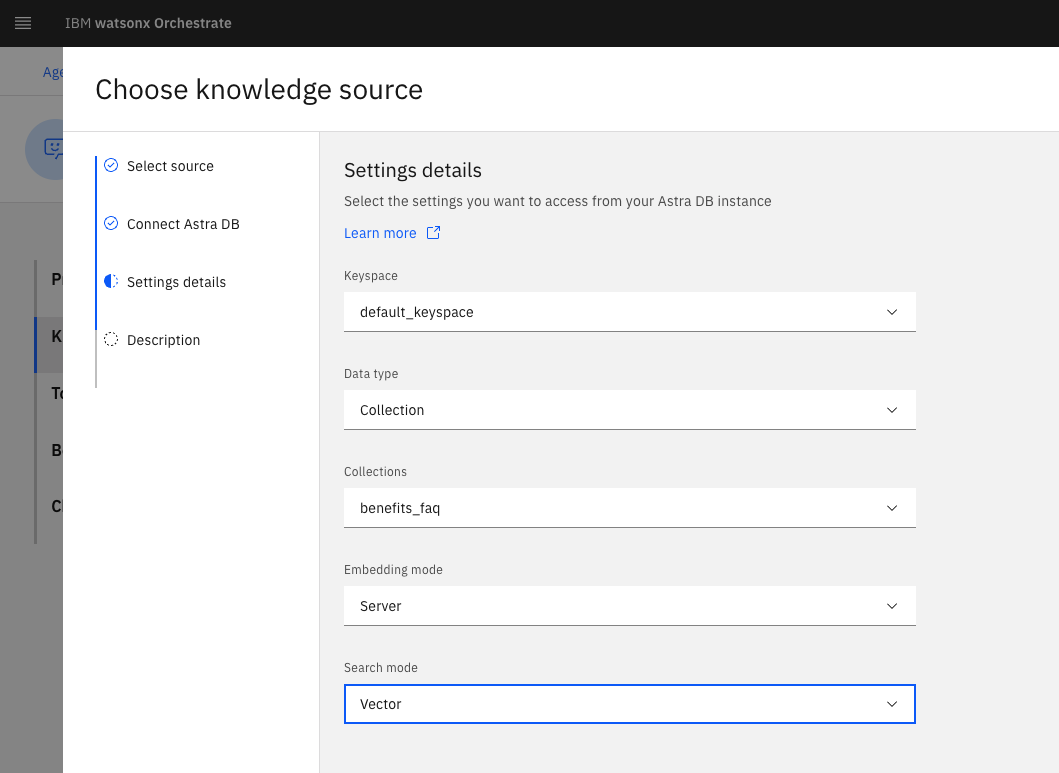
In the Settings details page, set the following details:
- Keyspace: default_keyspace
- Data type: Collection
- Collection: benefits_faq
- Embedding mode: Server
Search mode: Vector
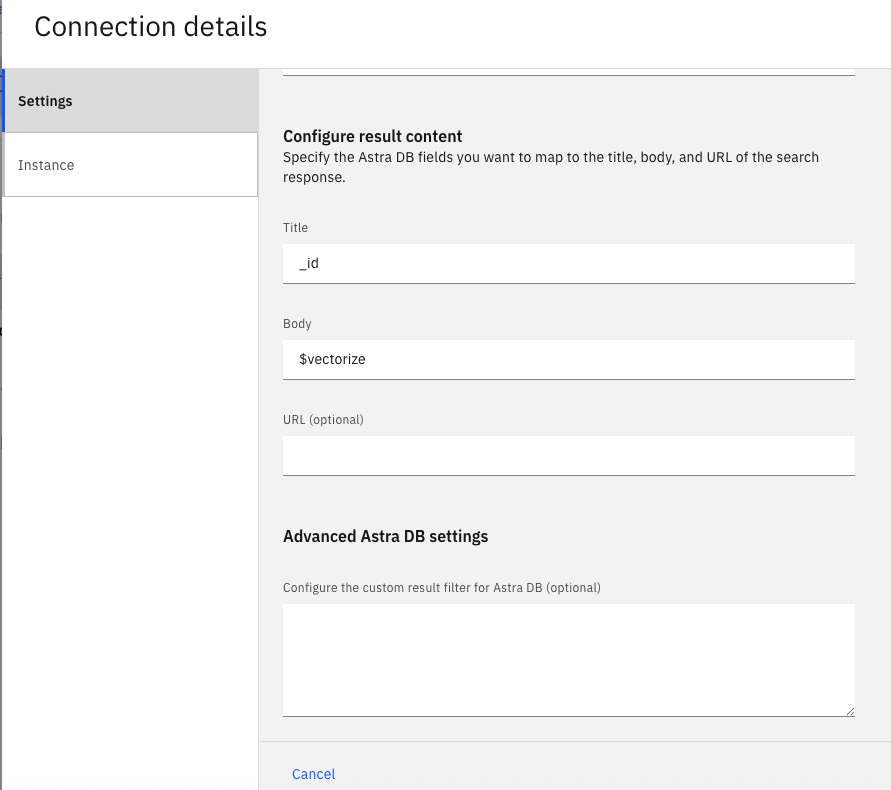
In the Configure result content section, enter the following details:
- Title: _id
- Body: $vectorize
(Optional) Use the Advanced Astra db settings to define filters for document type, tags, or metadata to improve search relevance.
Click Next.
In the Knowledge source description field, type HR benefits description and click Save.
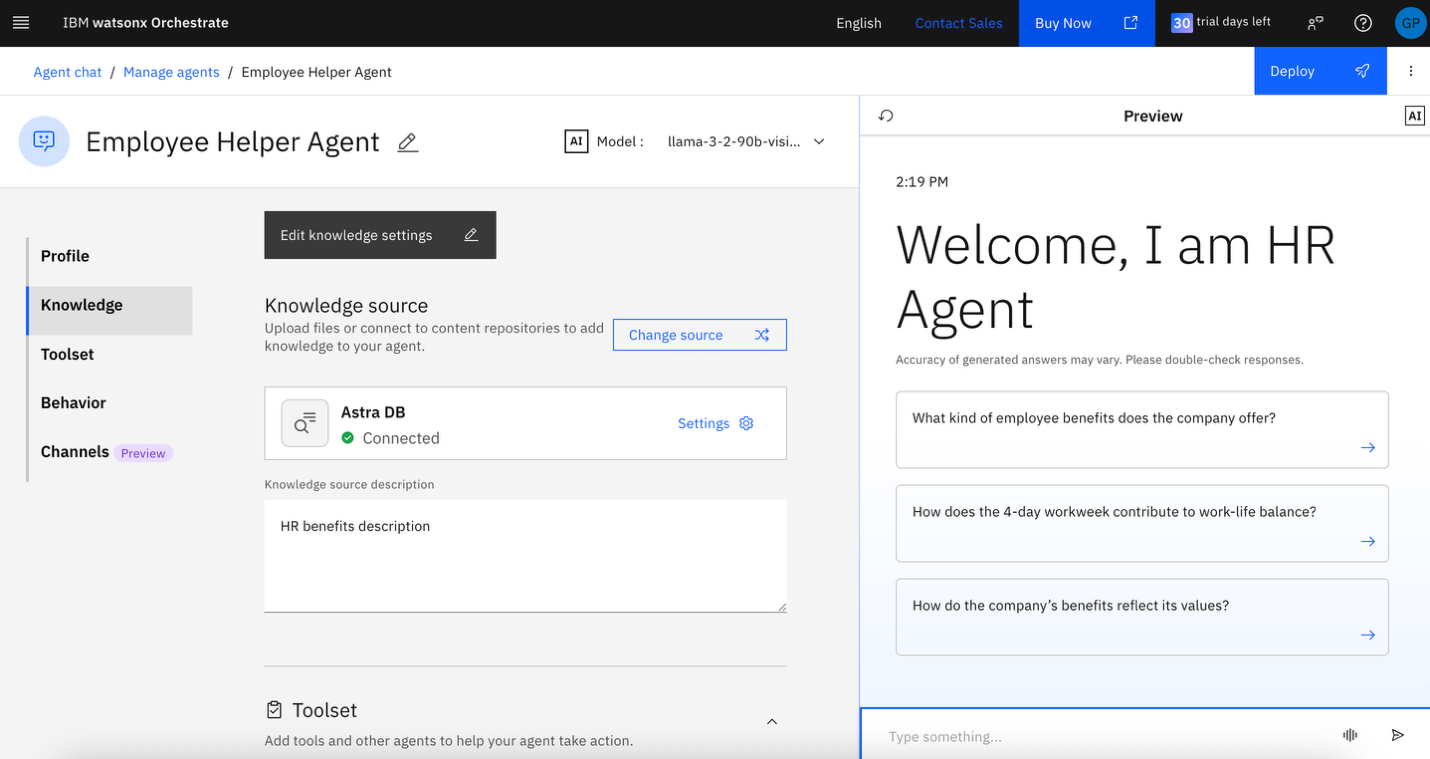
The knowledge_base Astra db knowledge base is now connected to the Employee Helper Agent agent.
Step 6. Define the agent behavior
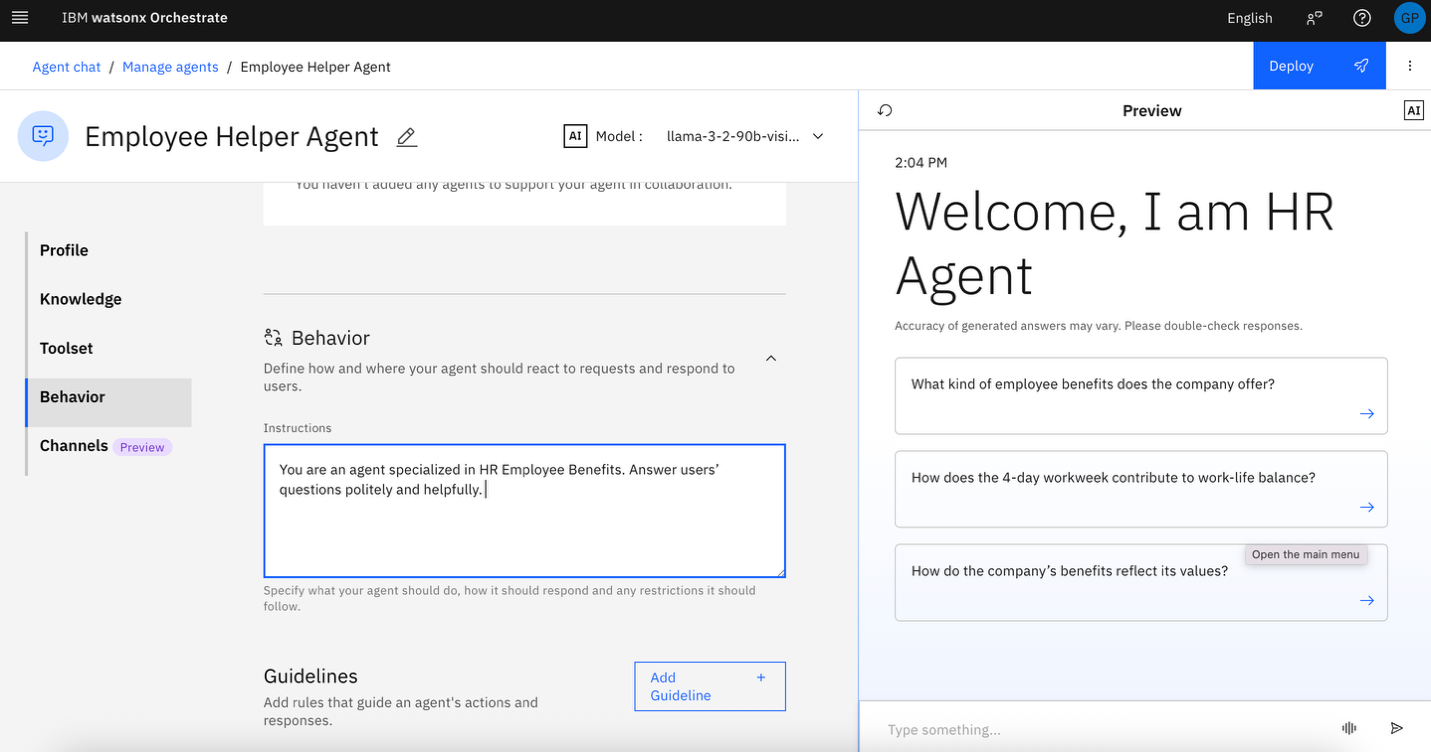
In the navigation, click the Behavior tab, enter the following instructions:
You are an agent specialized in HR Employee Benefits. Answer users’ questions politely and helpfully.
Step 7. Test the AI agent
Test the Employee Helper Agent agent by asking a question, for example:
"What kind of employee benefits does the company offer?"
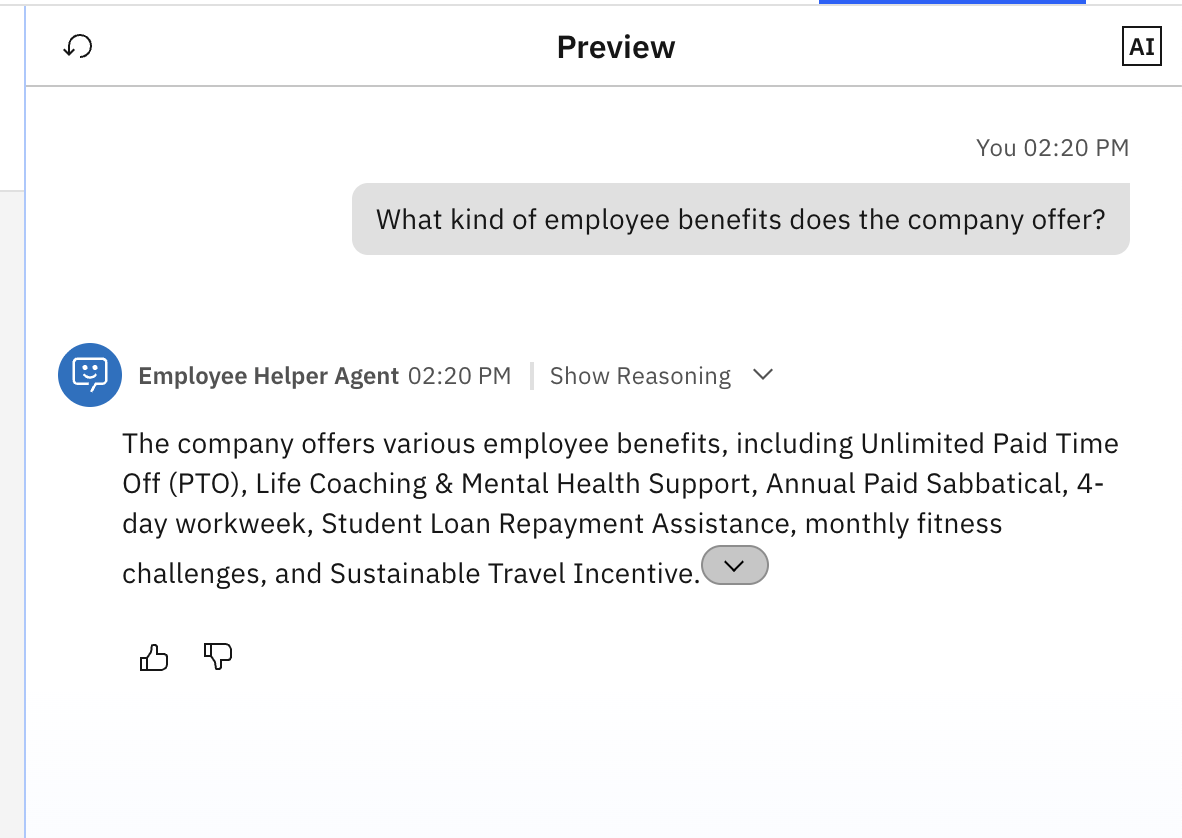
The arrow next to the name of the agent shows the Reasoning section, indicating which tool or knowledge was used. Click the arrow to expand and view how the agent reasoned and from where it retrieved the information.
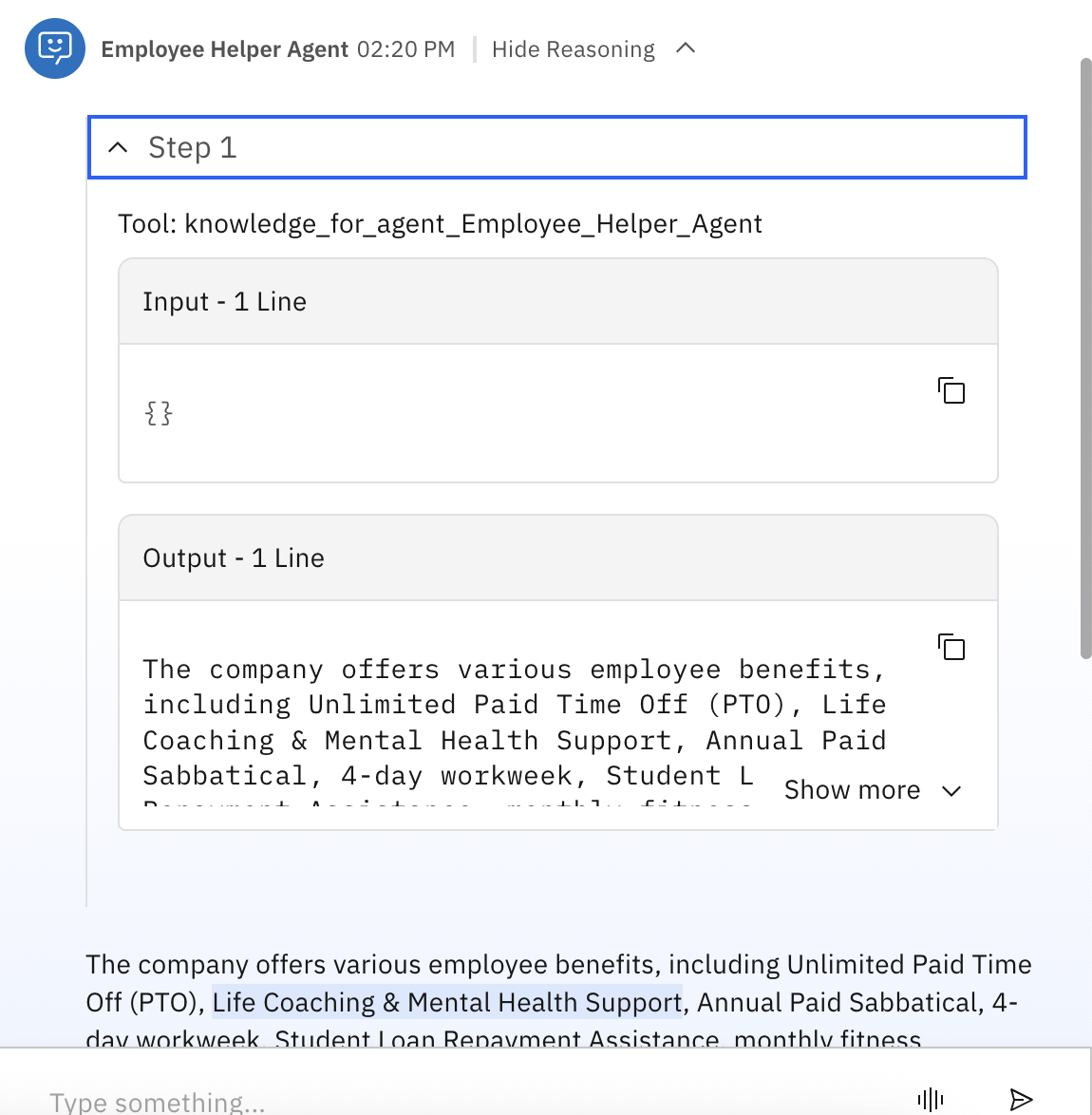
Since the agent uses a knowledge base, the Reasoning section shows:
Tool: knowledge_for_agent_Employee_Helper_Agent.
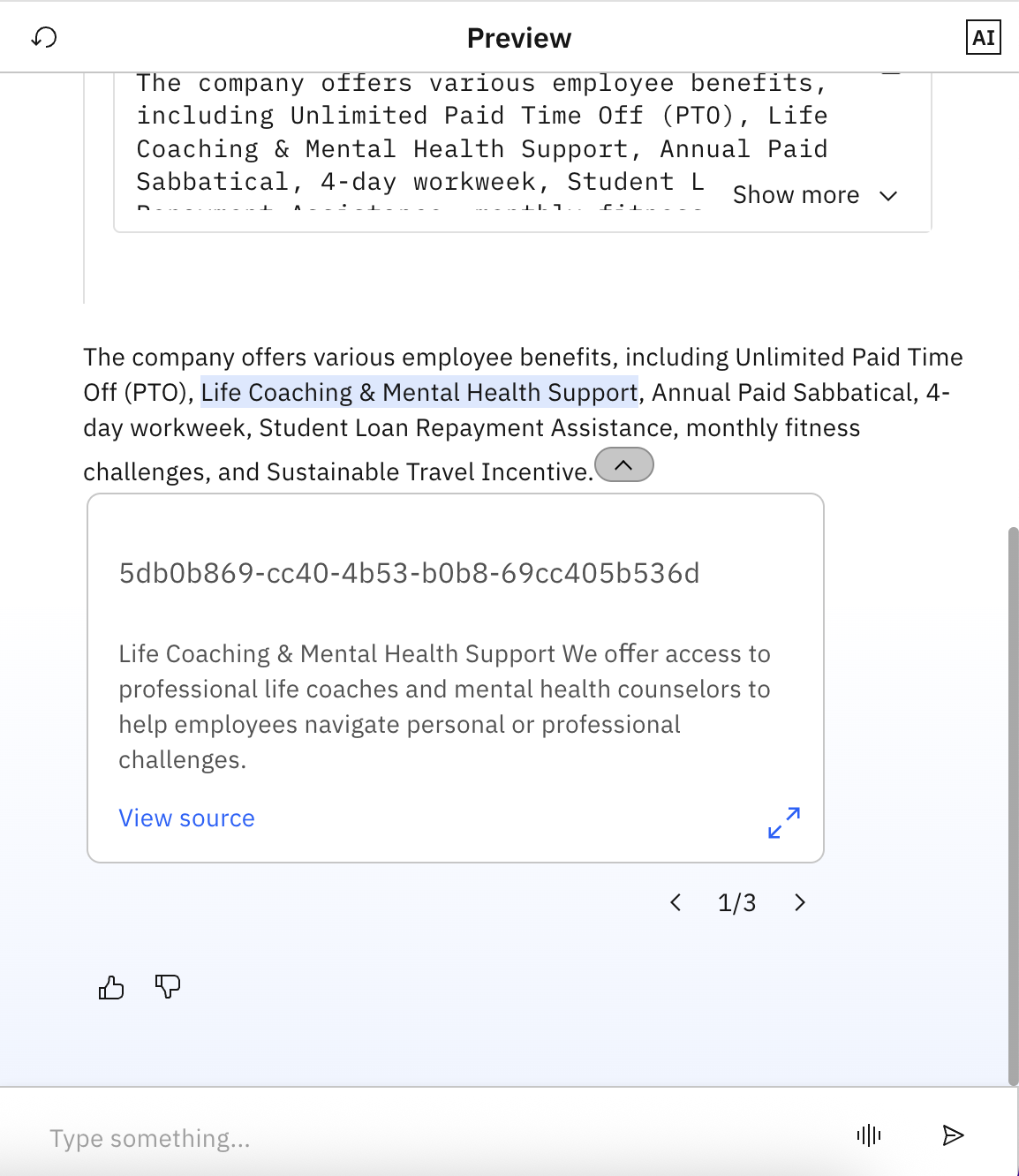
Click the arrow next to the response to view the source of the information within the documents stored in the Astra db database.
In this example, 1/3 means that the agent used three different source documents to generate the answer.
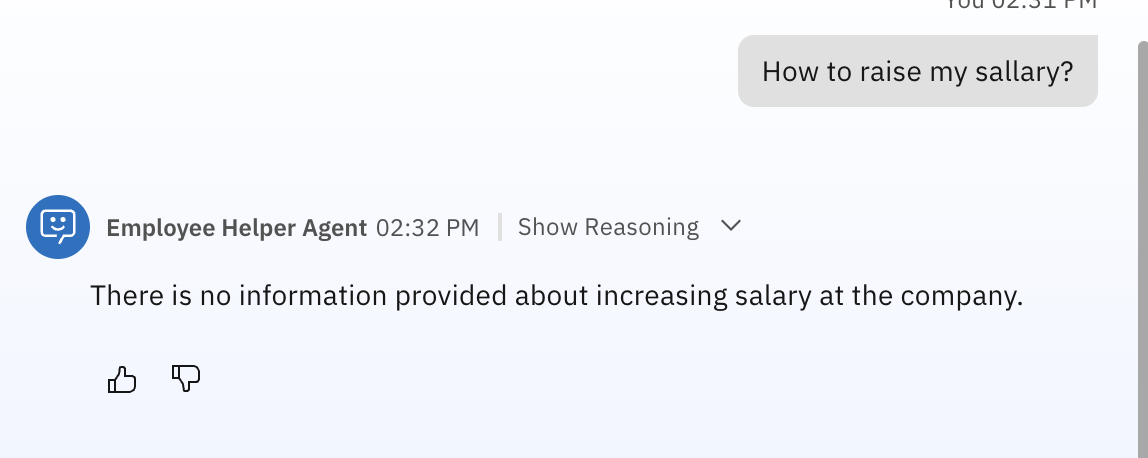
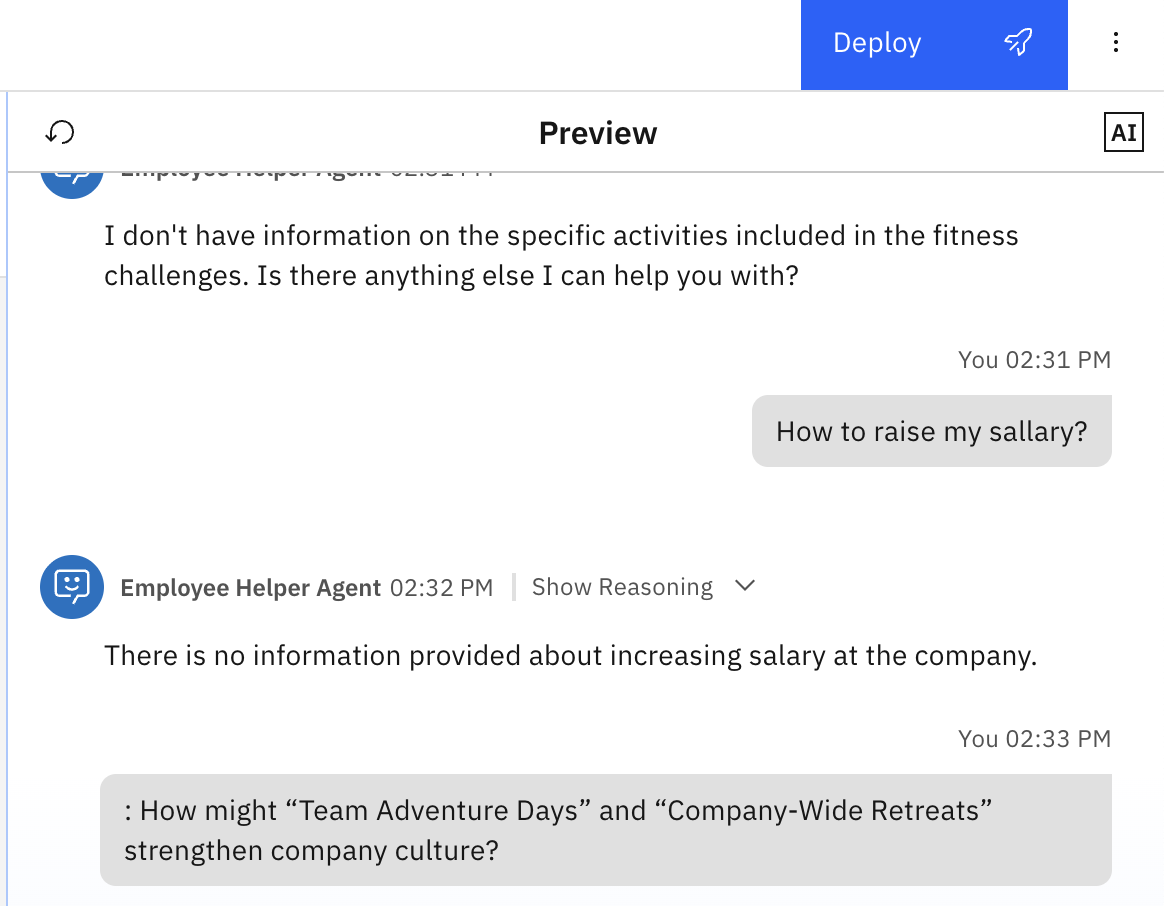
Ask questions that are not included in the document, for example:
How to raise my salary?
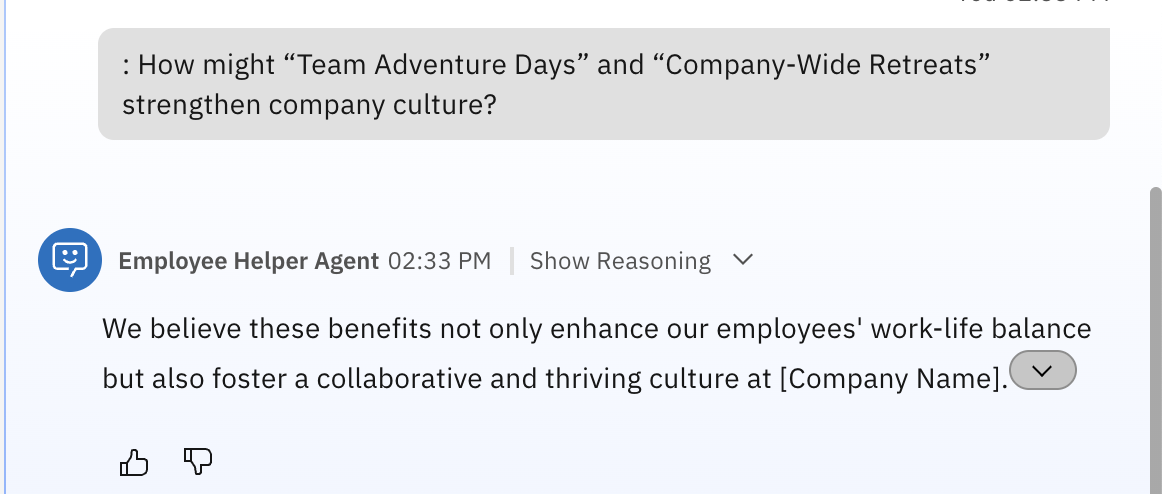
For more advanced testing, try asking questions that require synthesis, for example:
How might “Team Adventure Days” and “Company-Wide Retreats” strengthen company culture?
Step 8. Deploy the AI agent
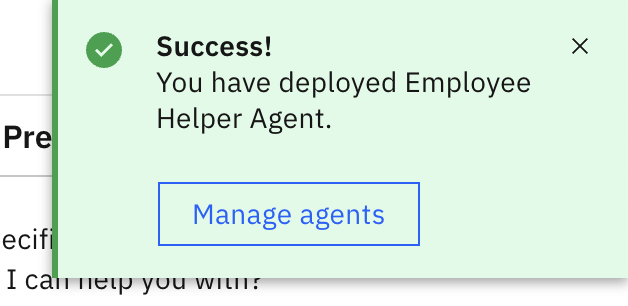
Click Deploy, then click Deploy again in the Pre-deployment summary page to confirm the Employee Helper Agent AI agent deployment.
After deployment, a Success message is displayed.
You can now interact with the Employee Helper Agent AI agent in the main chat of watsonx Orchestrate and try more complex questions.
Summary
In this tutorial, you learned how to load data into Astra db and set up document retrieval for an AI Agent by using watsonx Orchestrate.
Using watsonx Orchestrate with Astra db provides several benefits:
- Scalability: The serverless architecture of Astra db scales automatically, while watsonx Orchestrate manages workflows efficiently.
- Simplicity: You can focus on business logic instead of infrastructure.
- Relevance: Advanced vector search in Astra db ensures that the agent retrieves the most relevant context for accurate answers.
Acknowledgments
This tutorial is produced as part of an IBM Open Innovation Community initiative: Agentic AI (AI for Developers and Ecosystem).
The authors deeply appreciate the support of Ahmed Azraq, and Bindu Umesh for the guidance and expertise on reviewing and contributing to this tutorial.