About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Preparing data for fine-tuning LLMs for contract analysis using Data Prep Kit (DPK)
Use the Data Prep Kit for preprocessing your data to help fine-tune LLMs
On this page
In this tutorial, we explore how raw data can be prepared and processed in order to be used to fine-tune large language models (LLMs) for contract analysis using Data Prep Kit (DPK).
Fine-tuning LLMs involves taking pre-trained models and training them on smaller, domain-specific data sets to enhance their capabilities. However, simply feeding unstructured text data into the model is not sufficient. Proper data preparation is essential for transforming raw text into a structured format that is suitable for neural networks, directly impacting the model's performance.
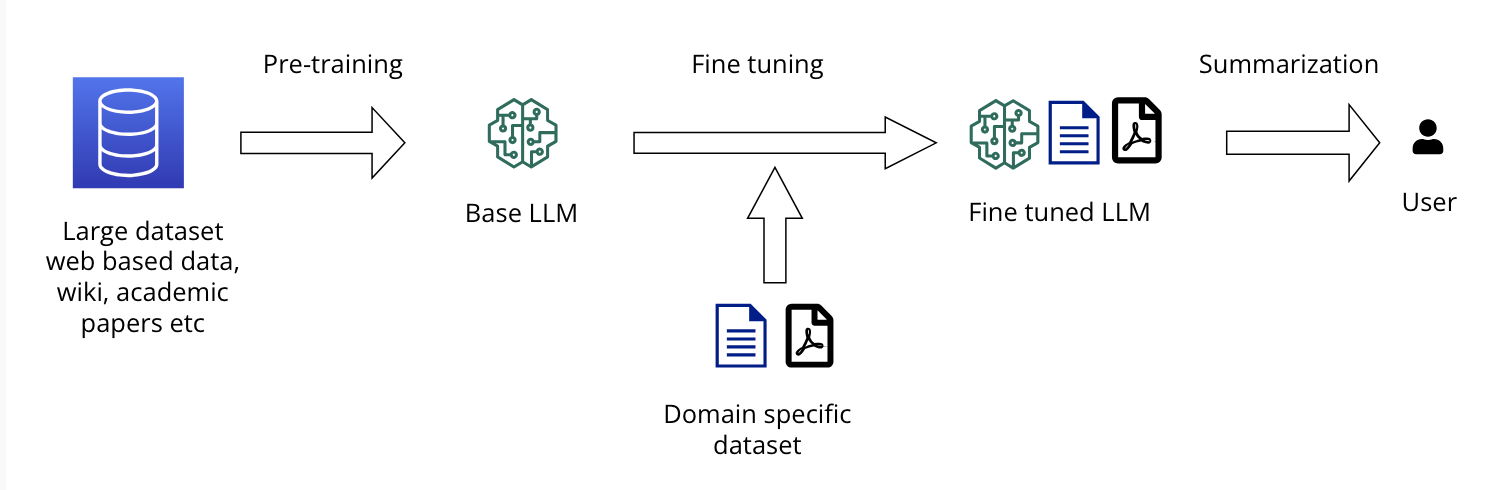
When working with unstructured text data like legal contracts, preprocessing is essential to transform the data into a structured format suitable for model training. Preprocessing steps, such as data ingestion, standardization, preparation, and tokenization, significantly impact model performance.
Data Prep Kit (DPK) is an open-source toolkit designed to streamline data preprocessing. DPK includes modular components (called "transforms"), and provides best practices for building data pipelines, from data ingestion to tokenization. DPK cleans and structures data, ensures uniform formatting, and prepares data for efficient tokenization.
In this tutorial, you learn how to use DPK to prepare data for fine-tuning and to achieve the business use case of contract analysis.
Consider a legal services company that needs to summarize lengthy contractual agreements into concise and accurate summaries. The goal in this case is to extract and highlight key sections of the contracts, such as Scope of Work, Compensation and Payment Terms, Termination Clauses, and Dispute Resolution. By fine-tuning an LLM with domain-specific contract data, the model can improve its ability to:
- Flag critical clauses (for example, confidentiality or dispute resolution).
- Generate high-quality, concise summaries tailored to legal terminology.
Organizations working with legal contracts like Master Service Agreements (MSAs), often face challenges in managing, reviewing, and fine-tuning legal documents at scale. With a repository of contracts, there is a pressing need for a streamlined process to analyze, extract, and refine critical clauses and terms to ensure compliance, clarity, and adaptability.
Fine-tuning the model on domain-specific language, legal terminology, and the structure of contracts handled by the organization ensures the model can:
- Understand context better by capturing the nuances in legal phrasing and identifying clauses with higher accuracy.
- Deliver tailored outputs by summarizing contracts in a way that aligns with the firm's specific requirements and priorities.
- Maintain consistency by producing uniform results across large data sets, thereby reducing human error.
By training on enterprise-specific contract data sets, firms can automate repetitive tasks, such as clause extraction and risk identification, while maintaining high levels of precision and compliance. This customization not only saves time but also enhances the insights derived from contracts, giving businesses a competitive edge.
Prerequisites
The latest version of the Data Prep Kit is available on PyPi for Python 3.10, 3.11, or 3.12. It can be installed using:
pip install 'data-prep-toolkit-transforms[language]==1.1.1
For instructions on setting up a virtual environment and installing the Data Prep Kit, refer to the Quick Start Guide.
The sample data sets used in this tutorial can be found in our GitHub repo. These documents represent Master Service Agreements (MSAs), which are legal contracts that outline the terms and conditions between service providers and clients for ongoing services or projects.
Steps
In this tutorial, you will use the Data Prep Kit to perform the data preparation steps:
- Conversion of PDF files to parquet file format
- Identification of hate, abuse, or profanity (HAP) content
- Identification of Personally Identifiable Information (PII)
- De-duplication of data
- Chunking of documents
- Assessment of document quality
- Tokenization of the data
Let’s dive into each step and see how the Data Prep Kit (DPK) helps ensure the model is trained on clean, structured, and high-quality datasets.
Step 1. Conversion of PDFs to parquet files
First, you must convert unstructured contract data (such as PDFs, DOCX, PPTX, images, or ZIP files) into a structured format.
The Docling2Parquet transform iterates through these files and generates Parquet files containing the converted documents in Markdown or JSON format. Parquet offers columnar storage, which aids in compression, efficient storage, and faster processing.
Use the following code to convert the PDFs to Parquet files.
from dpk_docling2parquet.transform_python import Docling2Parquet
Docling2Parquet(input_folder= input_folder,
output_folder= "files-pdf2parquet",
data_files_to_use=['.pdf'],
docling2parquet_contents_type='text/markdown').transform()
This step ensures that the contracts are stored in a compressed, structured format that is ideal for downstream processing.
Step 2: Identification of hate, abuse, or profanity (HAP) content
The identification of HAP content ensures that the data that is used to train models is free from harmful or inappropriate content that could introduce bias into LLM outputs. HAP content encompasses hate speech (discriminatory language targeting groups), abusive language (insults or threats), and profanity (offensive or vulgar expressions). The HAP Scorer is a tool used to assess and quantify the levels of harmful content, assigning a score between 0 and 1, where 0 indicates neutral content and 1 represents high levels of harmful content.
While not a common focus in traditional contract analysis, the identification of HAP content is becoming increasingly relevant in the context of training language models for legal applications.
In practice, the contract text is processed through the HAP Scorer to detect any harmful language, and content with high HAP scores is either filtered out or flagged for further review. By filtering HAP content, this step ensures that the training data set remains ethical, fair, and unbiased, which is essential for maintaining the integrity of automated contract analysis and decision-making processes.
Use the following code to identify HAP content and assign a HAP score:
from dpk_hap.transform_python import HAP
# create parameters
HAP(input_folder="files-pdf2parquet",
output_folder="files-hapoutput",
model_name_or_path= 'ibm-granite/granite-guardian-hap-38m',
annotation_column= "hap_score",
doc_text_column= "contents",
inference_engine= "CPU",
max_length= 512,
batch_size= 128,
).transform()
In this use case, we are working with legal contracts, where the likelihood of encountering HAP content is minimal. However, if a document receives a high HAP score, the DPK filter transform can be used to flag and remove documents with a HAP score that exceeds the defined threshold. This approach ensures that any harmful or inappropriate content is effectively pruned from the data set.
Step 3: Identification of Personally Identifiable Information (PII)
PII (Personally Identifiable Information) includes any data that can uniquely identify an individual. Examples include:
- Names (individuals, companies, signatories).
- Addresses (home, office, billing, shipping).
- Contact information (phone numbers, emails).
- Financial data (bank details, salaries, invoices).
- Legal identifiers (contract numbers, tax IDs).
In the context of contract analysis, the PII Redactor plays a crucial role by scanning and masking sensitive data within contracts, such as personally identifiable information (PII). This process ensures compliance with privacy regulations by preventing the unauthorized exposure of sensitive details. By removing or obfuscating PII while retaining the integrity of non-sensitive information, the PII Redactor supports both legal compliance and effective data-driven decision-making within the contract analysis process.
Use the following code to redact PII:
from dpk_pii_redactor.transform_python import PIIRedactor
PIIRedactor(input_folder='files-pdf2parquet',
output_folder= 'files-piiredacted',
pii_redactor_entities = ["PERSON", "EMAIL_ADDRESS","ORGANIZATION","PHONE_NUMBER", "LOCATION"],
pii_redactor_operator = "replace",
pii_redactor_transformed_contents = "title").transform()
Step 4: De-duplication of data
In this step, you remove redundant documents to avoid skewing the fine-tuning process.
The exact deduplication transform identifies and removes identical documents in a data set by comparing them hash-for-hash to ensure exact matching. Fine-tuning could involve small-scale, domain adaptation, or full-scale fine-tuning for deep model modification. In our contract analysis use case, the text corpus could include document summary pairs, multiple summary styles, and domain-specific texts for the contracts.
De-duplication minimizes redundancy, reducing the risk of overfitting during model fine-tuning.
Use the following code to de-duplicate the data.
from dpk_ededup.transform_python import Ededup
Ededup(input_folder="files-doc-chunk",
output_folder="files-ededup",
ededup_doc_column="contents",
ededup_doc_id_column="document_id").transform()
Step 5: Document chunking
Document chunking is an essential step for processing large, unstructured contract documents into smaller, manageable pieces, improving both the efficiency of training and the quality of the model’s outputs.
The chunking process helps prepare the data for better model training by breaking down complex documents into digestible parts. It also aids in the efficient allocation of computational resources, as large documents are divided into smaller chunks that can be processed independently. This step is vital in ensuring that the contract analysis model receives data in a format that promotes optimal learning and allows the model to focus on smaller, meaningful sections of each contract.
Use the following code to chunk the documents:
from dpk_doc_chunk.transform_python import DocChunk
DocChunk(input_folder='files-piiredacted',
output_folder='files-doc-chunk',
doc_chunk_chunking_type= "li_markdown").transform()
Step 6: Assessment of document quality
This step ensures that only high-quality and relevant documents are used for model training. Several new columns prefixed with docq_ will be introduced to evaluate document quality. Specifically:
- docq_contain_bad_word: A Boolean indicator that identifies whether a document contains inappropriate or unprofessional language. Ideally, this value should be False, ensuring that documents used for training do not contain offensive or irrelevant content.
- docq_lorem_ipsum_ratio: A numerical ratio representing the proportion of placeholder text ('lorem ipsum') in a document relative to its total content. Ideally, this value should be 0, indicating that the document does not contain any placeholder text.
These indicators help filter out documents that could negatively impact the fine-tuning process, ensuring a cleaner dataset
Use the following code to evaluate the documents for completeness, consistency, and relevance:
from dpk_doc_quality.transform_python import DocQuality
DocQuality(input_folder='files-doc-chunk',
output_folder= 'files-doc-quality',
docq_text_lang = "en",
docq_doc_content_column ="contents").transform()
Documents flagged with bad words or deemed incomplete are filtered out before further processing.
For the contracts used in this tutorial, you can view the results generated by the doc_quality transform.
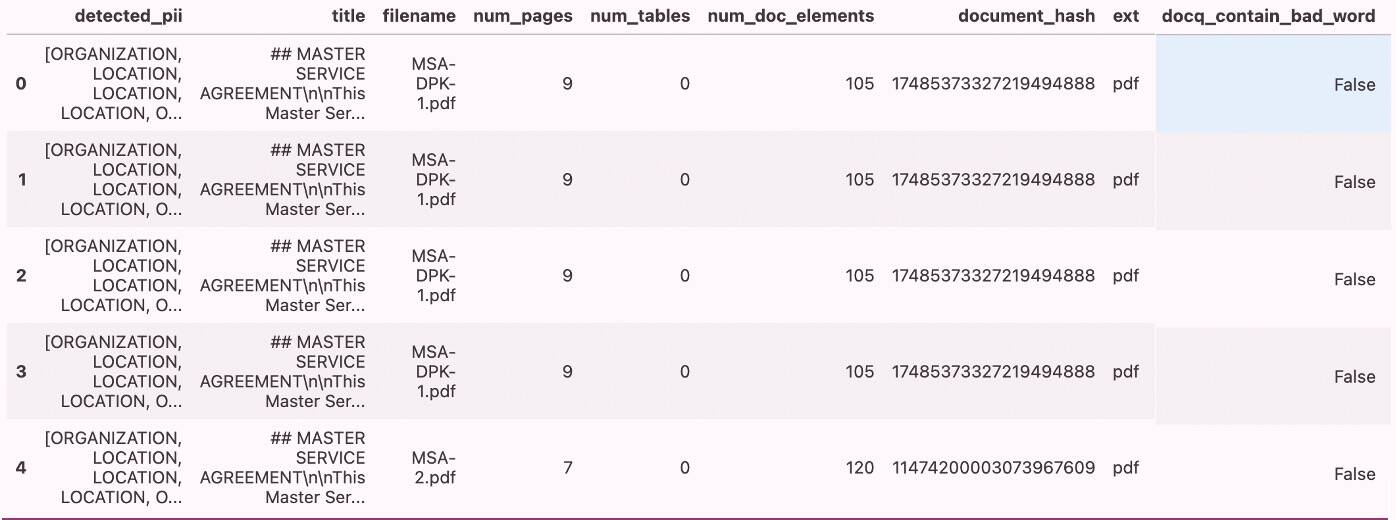
Based on the document quality results, since docq_lorem_ipsum_ratio > 0 and docq_contain_bad_word = True are not flagged, it means that our document quality is good. Therefore, there’s no need to filter out the best documents. However, in cases where document quality issues are identified, the DPK filter transform can be applied to remove documents containing inappropriate language or incomplete content. This helps maintain a clean and relevant data set, which ensures better quality for the fine-tuning process.
Step 7: Tokenization of Data
Tokenization is the process of converting text into smaller units (tokens) that a LLM can process. The data tokenization transform operates by converting a (non-empty) input table into an output table using a pre-trained tokenizer.
Use the following code to tokenize the text:
from dpk_tokenization.transform_python import Tokenization
Tokenization(input_folder= "files-doc-quality",
output_folder= "files-tokenization",
tkn_tokenizer= "hf-internal-testing/llama-tokenizer",
tkn_chunk_size= 20_000).transform()
Summary and next steps
Fine-tuning LLMs for contract analysis ensures better productivity, improved accuracy, and compliance—critical for the legal domain. By using the Data Prep Kit for the preprocessing steps to help fine-tune LLMs, you can:
- Streamline the preparation of complex contract data sets.
- Ensure compliance with privacy regulations.
- Improve the ethical and unbiased nature of training data.
- Achieve higher-quality fine-tuned LLMs for summarizing legal contracts.
You can explore the complete implementation of the DPK transforms for fine-tuning LLMs in our Jupyter Notebook in our GitHub repo.
You can learn how to fine tune the IBM Granite Model to create a specialized LLM using the LoRA transformer technique in this tutorial.