About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
IBM MQ high availability and disaster recovery options
Choosing the right resilience option for your queue manager
On this page
One of the great strengths of IBM MQ is that it can be installed on a large variety of platforms and can create messaging networks right across a hybrid cloud landscape. This breadth means that over time IBM MQ has evolved to provide a number of different mechanisms for availability, each suited to specific platform challenges. The high availability (HA) and disaster recovery (DR) options include multi-instance queue managers, replicated data queue managers, native HA with cross-region replication, and of course MQ clusters. This article will help you navigate this array of HA and DR options based on key architectural decisions.
Until relatively recently, IBM MQ would typically have been installed and administered by a central team. Developers would go to that team to request new queues or access existing ones. The central team would have made all the architectural decisions around how the infrastructure would handle high availability and disaster recovery. Those decisions would be quite coarse grained. Large, centralized queue managers with 100s or perhaps 1000s of queues would be designed to provide the highest levels of service and cater for the most challenging service level agreements required by the enterprise.
Things have changed. The adoption of DevOps approaches, and containerized platforms have made it possible, indeed desirable, for developers to own all the capabilities that make up their solutions. This gives developers more autonomy and control of their overall solution, enabling greater productivity.
IBM MQ is a great example of this. It is now possible to completely specify a queue manager with only a handful of configuration files. Pass these configuration files to your automation tooling and within a minute or two you have a running production ready queue manager specifically designed for your needs.
However, with great power comes great responsibility! No matter how good modern deployment techniques are, someone still needs to translate availability and recovery requirements into the architectural options available within the product. Before we had a central team with years of IBM MQ experience. Now, in many cases, it might be a choice for the developer who might have only minimal experience with the product.
In this article, we will explore different queue manager resilience options, including enough background for you to make the right choice whether you are a seasoned MQ administrator or an application developer coming to the product for the first time. The good news is that you probably don’t need to read the whole article! A quick look at the following table, should help you work out which mechanisms are most likely to be relevant to your needs. This table should help you navigate to the sections that are most relevant to you.
| Queue manager type | Platforms | Storage | HA | DR |
|---|---|---|---|---|
| Native HA queue manager | Containers or Linux (VMs/bare metal) | Individual block storage | Quorum based. MQ native replication. Low seconds. | MQ native replication |
| Replicated data queue manager (RDQM) | VMs (RHELx86) | Individual block storage | Quorum based. File system-based replication. Low seconds. | Operating system based replication |
| Multi-instance queue manager | VMs (or containers with caveats) | Shared (specific locking) | Two instances based on file locking. 10s of seconds. | Storage replication |
| External HA queue manager | VMs or containers | Shared RWO | Cold standby using external HA, or container platform. 10s of seconds to minutes. | Storage replication |
| Shared Queues | z/OS | z/OS coupling facility | z/OS specific capabilities. Near instant to low seconds depending on the failure type. | Storage replication |
Note: Because this article is targeted at application developers, we will not be covering z/OS shared queues in depth as these are usually administered by centralized teams. However, shared queues are well covered in the IBM MQ documentation.
We will also discuss the value of MQ clustering to workload balance across multiple active queue managers in order to further improve message availability.
Before we delve into the detail, we should note that there are a couple of other options available to you if you really don’t want to manage your own queuing infrastructure but have no central team. The simplest would be to consider the IBM MQ as a Service option where IBM manages the queue managers in the cloud on your behalf. The second, is the IBM MQ Appliance, which provides pre-installed IBM MQ infrastructure optimised for its own hardware, with high availability and disaster recovery capabilities built in. A good summary of all IBM MQ form factors is available as a in this blog post. However, assuming neither of those fit your needs and you are looking to manage your own MQ infrastructure, let’s continue to explore the software-based options.
Evaluating availability and recovery in messaging systems
To be able to correctly choose between the options in IBM MQ, we first need to explain what we mean by the terms used in this space, and specifically “high availability” (HA) and “disaster recovery” (DR). Different mechanisms are generally required for each HA and DR, so it is usually wise to consider them separately and architect for them independently. We will confirm their general meaning in IT but also identify specific subtleties in the context of messaging.
In evaluating both high availability and disaster recovery, we are really looking at the system’s ability to “recover”. In other words, how long the service provided by the system was affected, and what happened to its associated data as a result of the recovery.
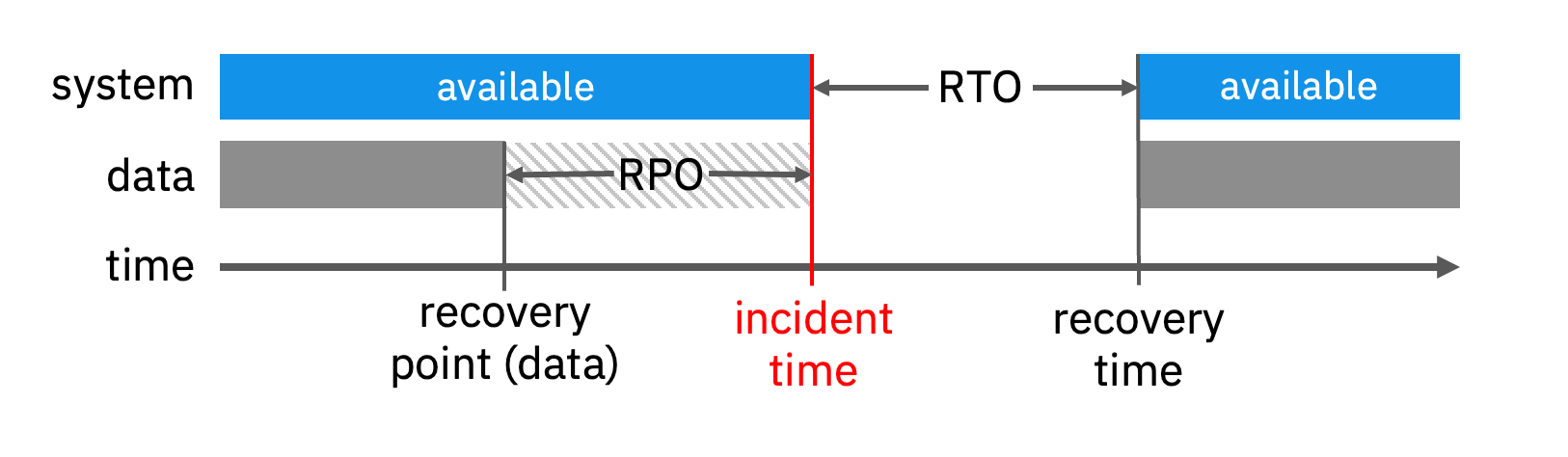
Two key concepts in HA and DR are Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
- Recovery Time Objective (RTO) refers to how long it takes following a failure to regain the ability to send and receive messages and to access existing messages.
- Recovery Point Objective (RPO) refers to the amount of messages that were lost as a result of the outage. Literally, at what “point in time” did we go back to compared to the time where the incident occurred.
We will refer to these concepts in the following definitions of HA and DR.
Defining high availability (HA)
High availability (HA) refers to the system’s ability to handle day to day issues, providing continued processing in the face of single component failures and performing of planned maintenance. Availability is typically measured in terms of the proportion of time the capability is available (for example, 99.9% or “three nines”). It is often referred to as “high” availability due to the minimal levels of downtime typically targeted.
From a time perspective, the aim in high availability is an RTO of close to zero. We should recover from single component’s failure so quickly that they have minimal effect, or ideally no effect, on systems or users that are dependent on the messaging service.
When applied to messaging, to recover successfully from a failure, you also expect to regain access to the messages that were already queued in the system. The target is an RPO of 0 in the provision for high availability, (that is, no loss of any messages). As we will see, it is possible that a proportion of the messages may become temporarily unavailable, but they should not be lost.
From a messaging perspective, there are in fact two categories of availability to consider;
- Service availability, which means whether messages can be sent and received through the system. In this context, “unavailable” means a messaging client is either unable to receive messages or unable to send new messages for a period of time. Note that if at least some messages can still be read, the system would still be considered to have service availability, which explains why we have the second category of “message availability”.
Message availability, which focuses on whether existing messages in the system can be read. If all messages can be read as usual, then the system has full message availability. If only some messages can be read, it has partial message availability. If none of the current messages can be read, the system is unavailable from this context. Message availability can be measured in terms of what percentage of messages are unavailable and how long they are unavailable for. The target is that messages are never lost, and that it is purely a matter of when they will become available again.
A slightly more subtle measure of availability looks at consumer lag. The time between when messages are put into the messaging system and when they are read from the system and processed. If queues build up because of a failure, then the time taken to clear down those queues may also need to be considered part of the message availability since the newly queued messages are effectively unavailable during that lag period.
It's important to recognize that there may be different RTOs for each of the above depending on the service level agreement (SLA) we need to meet. We might for example require a service availability with an RTO measured in less than a second to ensure we can always accept incoming work. However, we might be able to accept a message availability with an RTO in minutes since a delay to the processing of messages already in the system might be acceptable.
Defining disaster recovery (DR)
Disaster recovery (DR) refers to much more serious situations where multiple components have failed, reaching right up to whole regions becoming unavailable. In short, recovery kicks in when availability runs out of steam. For this reason, it is often referred to as “disaster” recovery.
RTO timescales are much longer than for HA, and manual intervention is typically required since multiple systems must be aligned. While the individual systems might themselves be able to recover rapidly, gaining confidence that the data is sufficiently consistent across multiple systems might take time. It will in more cases be a human decision around when and how to return to service, and this could take hours or even days.
Furthermore, to protect against regional failure, it is often necessary to be able to perform recovery in an alternative region, which needs to be perhaps at least several hundred miles or kilometers from the original sites. Due to the inherent physical limitation (that is, the speed of light affecting the latency, and in turn the time it takes to know for sure that data has reached its destination), it is often impractical to replicate data synchronously into another region as application performance would be significantly impacted. The implication of this is that the recovery site is not guaranteed to have exactly the same data as the live site. Therefore, it is typically impossible to avoid some data loss during a full and abrupt disaster. Using our earlier terms, this means that in a DR situation there is always a chance of an RPO > 0. The aim of architecting for DR is to minimize that RPO, but you are unlikely to be able to eliminate it.
Planned outages
Of course, the best way to improve both your HA and DR stance is to tackle issues in advance. The “nines” of high availability provide for a certain amount of scheduled downtime if required, and maintenance such as keeping up with security patches and refreshing hardware will go a long way towards avoiding unplanned outages that affect HA and DR. One of the primary advantages of pre-emptive maintenance is that it can be done in a controlled manner, scheduled at a time that least affects dependent systems, and generally with an RPO of 0 and RTO close to 0. Interestingly, we can often make use of the technologies primarily designed for unplannable DR scenarios, to perform these planned outages.
The evolution of multi-site HA and DR
Historically, it was a common pattern for customers to have a couple of physically separate data centers with different power feeds. High availability (HA) was catered for by replication within a given data center. Failing from one data center (DC) to the other was seen as a disaster recovery (DR) scenario.
Over time, networking has improved to the point where some sets of data centers that were sufficiently close together (that is, at most, tens of kilometers) that the pair of DCs then become part of a more broadly resilient HA stance rather than for their original DR purpose. Around the same time, we saw an increasing need to provision for full region disasters, so DR sites were typically created in a distant region (that is, at least several hundred kilometers).
For brevity, skipping over multiple further iterations, we come to modern cloud-based deployments. High availability is handled by what cloud providers call “regions” which consist of sets of “close” data centers often referred to as Availability Zones (AZs) within the region. These are physically independent for resiliency, but close enough to have good enough networking that synchronous replication between them is possible. A region therefore enables similar availability to the previously described “close proximity” of 2 DCs. However, more typically, you see at least 3 AZs used to provide HA due to the quorum paradigms typically used in cloud-based architecture.
There are of course times when an entire region can go down or be impacted as a whole. In these rare events, we must ensure we also have a DR mechanism to regain service and message availability as soon as possible. For these scenarios, an equivalent capability is usually made available in another region. Since synchronous replication would typically be impossible, we then need to architect for acceptable values of RPO.
IBM MQ queue manager high availability options
Now that we have a common understanding of how HA and DR apply to messaging, we’ll look at the most popular options available with IBM MQ, across the widest used platforms.
IBM MQ has multiple HA options to handle failure of a queue manager instance. In all cases, these enable reinstatement of that queue manager with no data loss (RPO=0), right down to the most recent message update. However, some options provide greater protection against hardware and system level failures outside of MQ’s control.
These queue managers are known as native HA queue managers, replicated data queue managers, multi-instance queue managers, and external HA queue managers.
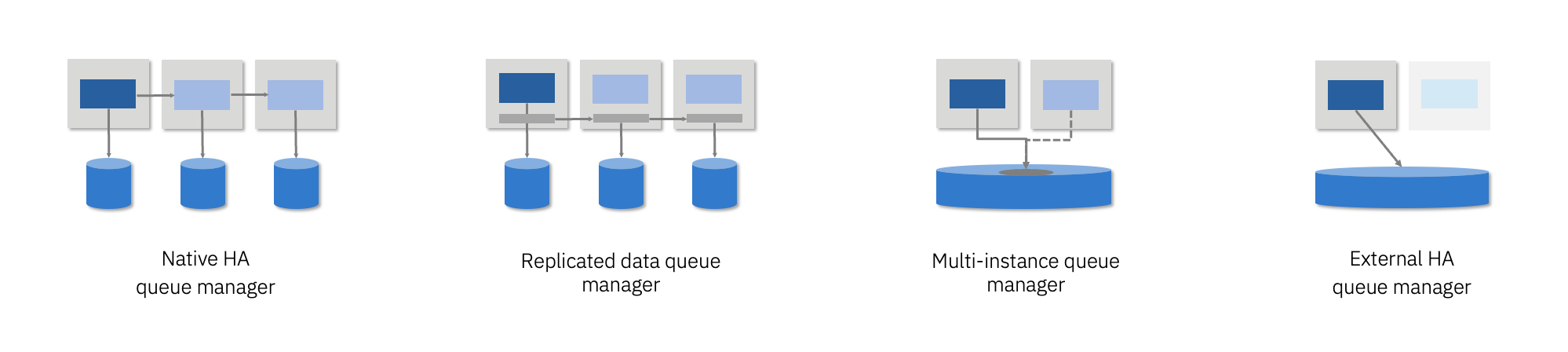
These are the options provided “out of the box” from IBM MQ. Note that we have deliberately omitted the “Shared Queues” capability on z/OS since it is not an option a developer would be considering. However, it is an extremely robust and mature mechanism still commonly used by MQ administrators providing MQ on that environment.
These options all focus on the availability of an individual queue manager. Their primary focus is message availability, which means they restore access to the queue manager data as quickly as possible.
All of these options ensure that there is one and only one active instance of a queue manager to ensure the integrity of existing messages, preventing loss and duplication following a failure.
Restoring a working queue manager also results in an equivalent improvement in service availability. With the more advanced of these options, queue managers can return within a few seconds. Later in this article, we will discuss how we can combine multiple queue managers in a topology to further improve service availability.
Choosing between the above options depends on your availability requirements (that is, how many “nines”), the form factor or platform being used, your approach to dependencies, and the desired footprint. Let’s look at each of these types of queue manager resilience in turn.
Native HA queue manager
Going forward, native HA is the primary strategic approach to high availability in queue managers.
A native HA queue manager is a quorum-based three instance model that can be deployed both on container, and also on Linux based virtual machines or bare metal. It is called “native” HA because the replication and leadership algorithms are all performed natively by MQ itself.
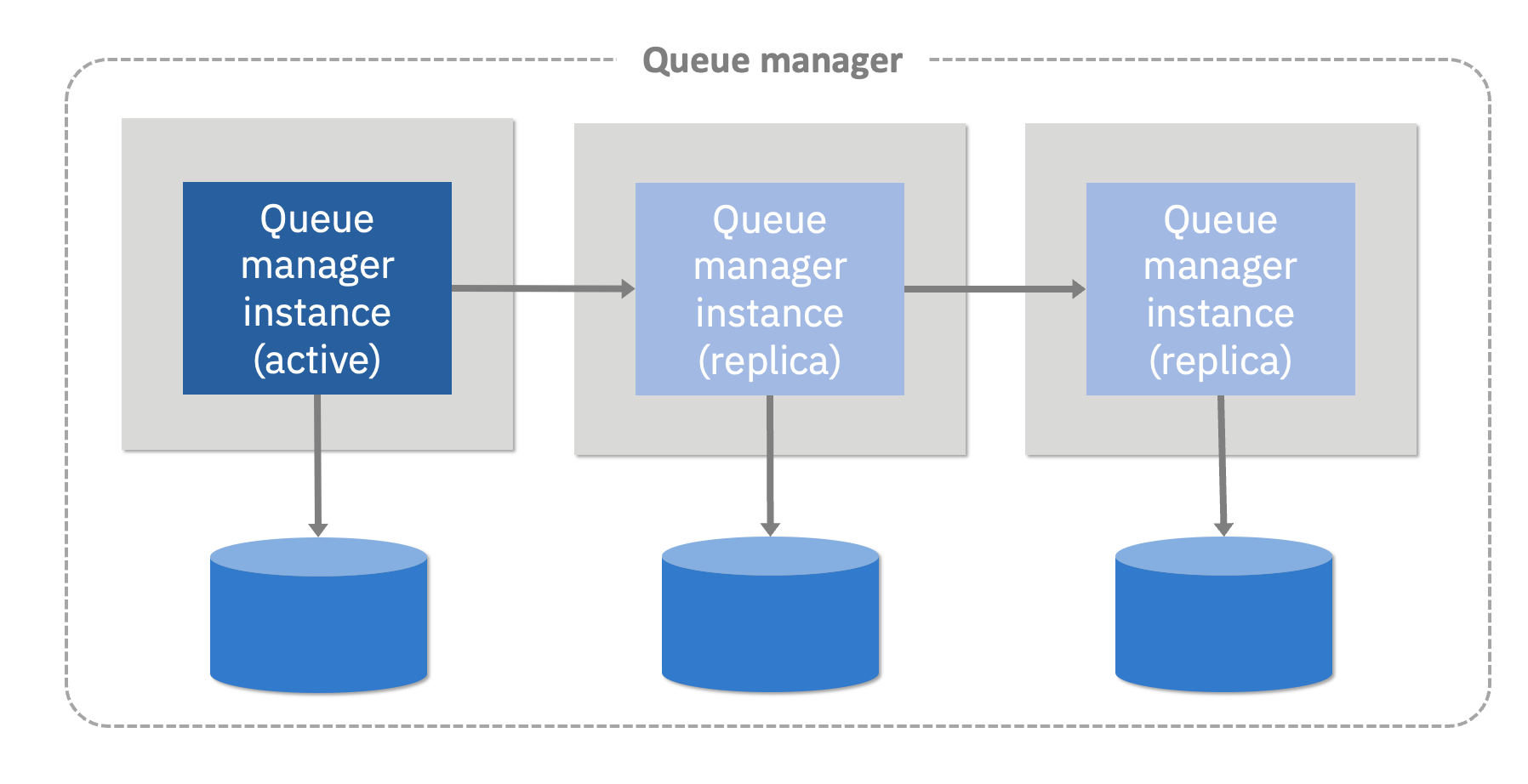
Instances of native HA queue managers only require simple unreplicated block storage (known in containers as RWO or “read/write once”), and simple local fast disks can be used to maximize performance at reduced cost. Clients point to the one active instance which then replicates its data to the other two standby instances. If a failure occurs, a consensus algorithm known as “Raft” is used to elect one and only one new leader. When the new leader starts accepting traffic, connected clients are re-routed automatically to the new leader.
Native HA therefore avoids dependencies on sophisticated shared storage classes (known in containers as RWX or “read/write many”) that are required by multi-instance queue managers . It also avoids the complexities associated with dependencies on specific updates to the operating system needed by replicated data queue managers (RDQM).
Native HA queue managers work well with cloud deployments that use multiple availability zones and within on-premise clusters with at least 3 operating system nodes. The replicas are spread across nodes which have physical segregation but short enough latency to enable synchronous replication.
Native HA also provides an asynchronous replication mechanism known as “cross region replication,” which can be used for DR and is described in a later section.
In summary:
- Three instance footprint due the use of the quorum pattern.
- No dependency on complex shared storage – simple unreplicated block storage (RWO) can be used.
- No dependency on specific operating system additions or configuration.
- Can be used in containers, and from IBM MQ 9.4.4 forward, it can also be used on Linux virtual machines and bare metal.
- Failover to a new leader can be single digit seconds.
Replicated data queue manager: HA (RDQM:HA)
An RDQM:HA is a quorum-based synchronous replication between exactly three instances, designed for Red Hat Enterprise Linux.
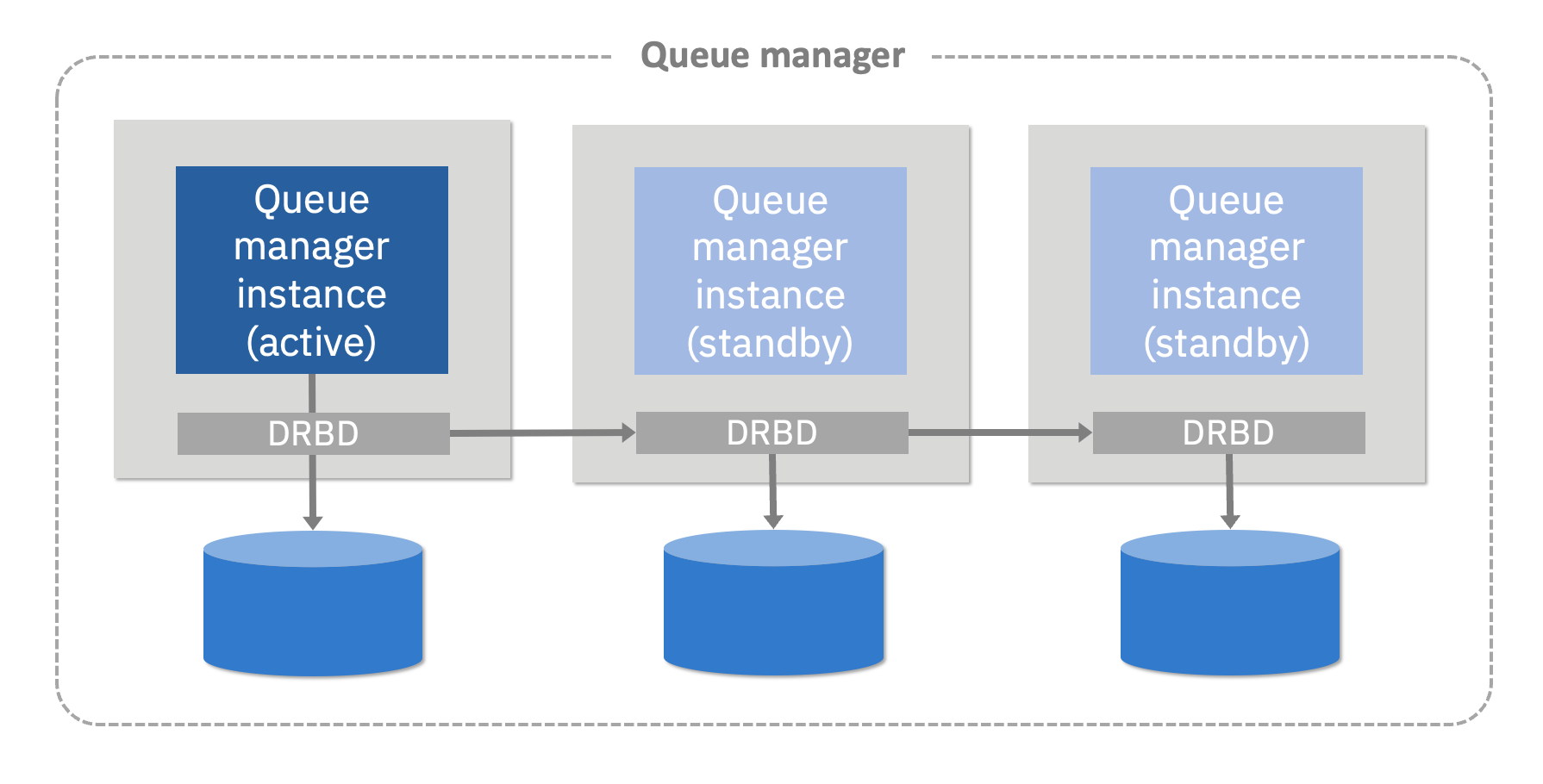
RDQM:HA instances only require standard local disk storage, so there are no dependencies on sophisticated shared storage. Simple local fast disks should be used. One instance is the leader to which clients connect, and the others are followers that are ready to take over if the leader fails. Replication is performed by specifically configured features that MQ installs into the Red Hat Enterprise Linux operating system. The queue manager data is replicated synchronously across the 3 instances, which can be spread across separate virtual or physical machines.
For extra resilience, these machines can be spread across three sites, such as availability zones within a cloud region, so long as the network latency is low enough. In the case of failure, it uses quorum to establish a new leader, which is a common pattern for cloud-based multi-site resilience. MQ clients do not need to be aware of the 3 instances since they are automatically rerouted via a floating IP address.
Note that RDQM also provides an asynchronous replication mechanism which can be used for DR, which is described later in this article.
RDQM, however, is dependent on replication provided by a technology known as Distributed Replicated Block Device (DRBD). This is a storage solution for Red Hat Enterprise Linux that mirrors data between multiple hosts, functioning transparently to applications. These DRBD modules must be added to the kernel of the operating system. When the queue manager writes to local disk, this is intercepted by DRBD and replicated to the other local disks. This ties the implementation to a very specifically installed Red Hat Enterprise Linux installation. It also makes it impractical to use on container environments which should be agnostic to the underlying host operating system.
In summary:
- Three instance footprint due the use of the quorum pattern.
- No dependency on specific types of shared storage – local disks can be used. This reduces infrastructure costs and typically improves performance and speed of problem resolution.
- Dependency on Red Hat Linux with specific kernel updates.
- Cannot be used in containers due to DRBD kernel driver dependencies.
- Failover to a new leader can be single digit seconds.
- Entire HA solution is provided by IBM, supported and rigorously tested in similar configurations to your own.
Multi-instance queue manager
With a multi-instance queue manager, two instances of the same queue manager use a shared file system, both attaching to the same set of storage. The first instance to obtain a lock becomes the active instance, allowing it to record message updates to that storage. If the active instance fails, the lock is released and the standby instance automatically takes over, gaining access to the same message data.
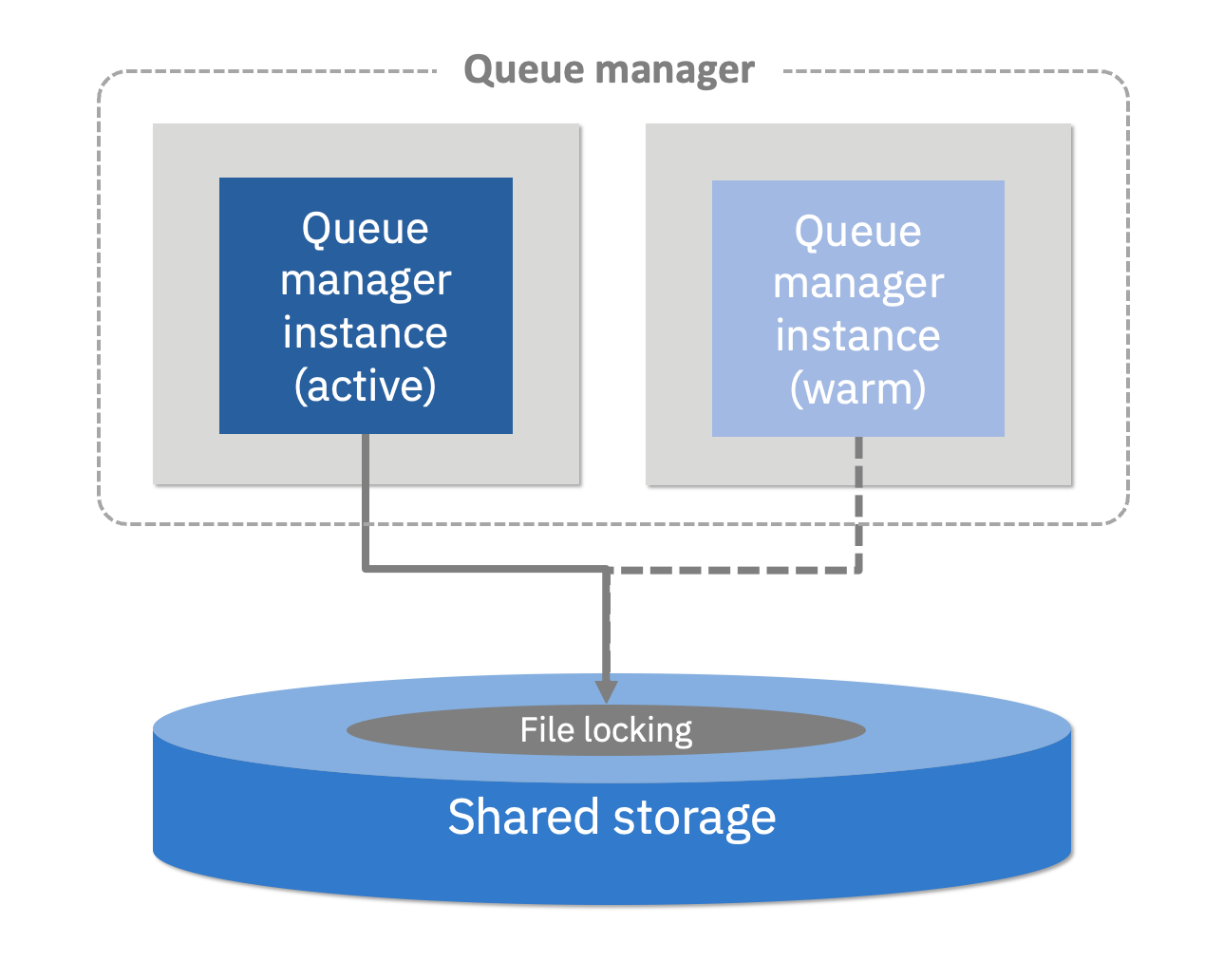
The multi-instance queue manager provide greater availability compared to the external HA queue manager since there is a standby queue manager already running, which is ready to take over from the original.
This is the technique that has been traditionally used with closely located 2 data center topologies. This works well where the file system accurately and consistently adheres to the POSIX standards that MQ relies on to guarantee data integrity, and the shared lease locking that multi-instance requires. However, this is not always the case, and although MQ provides help in assessing this, it can be hard to detect in advance of all failure scenarios.
There are also performance considerations, both in the access to the file system and the speed of detection of a failed instance and the timely releasing of the locks. The former will reduce message performance, and the latter will increase RTO. Additionally, the level of resiliency to storage failures, and the ability to distribute the two instances, relies on the file system’s approach to resiliency and data replication.
In summary:
- Two instance footprint due to the warm standby queue manager.
- Dependent on sophisticated sharable storage capabilities.
- Can be used in containers.
- Switch to standby generally occurs in the order of 10s of seconds dependent on the storage layer’s locking implementation.
- Due to the high dependency of MQ on the storage, file system choice is critical, and performance can be impacted.
- Runtime problems can be hard to resolve, and your combination of MQ and file system may be unique to you.
External HA queue manager
For the external HA queue manager, only a single instance of the queue manager is present, and therefore it is sometimes referred to as a “single instance queue manager” especially in the context of containers. Availability is provided by an HA infrastructure external to MQ which reinstates the queue manager following a failure, and it is dependent on replicated storage that can be re-mounted in the new location.
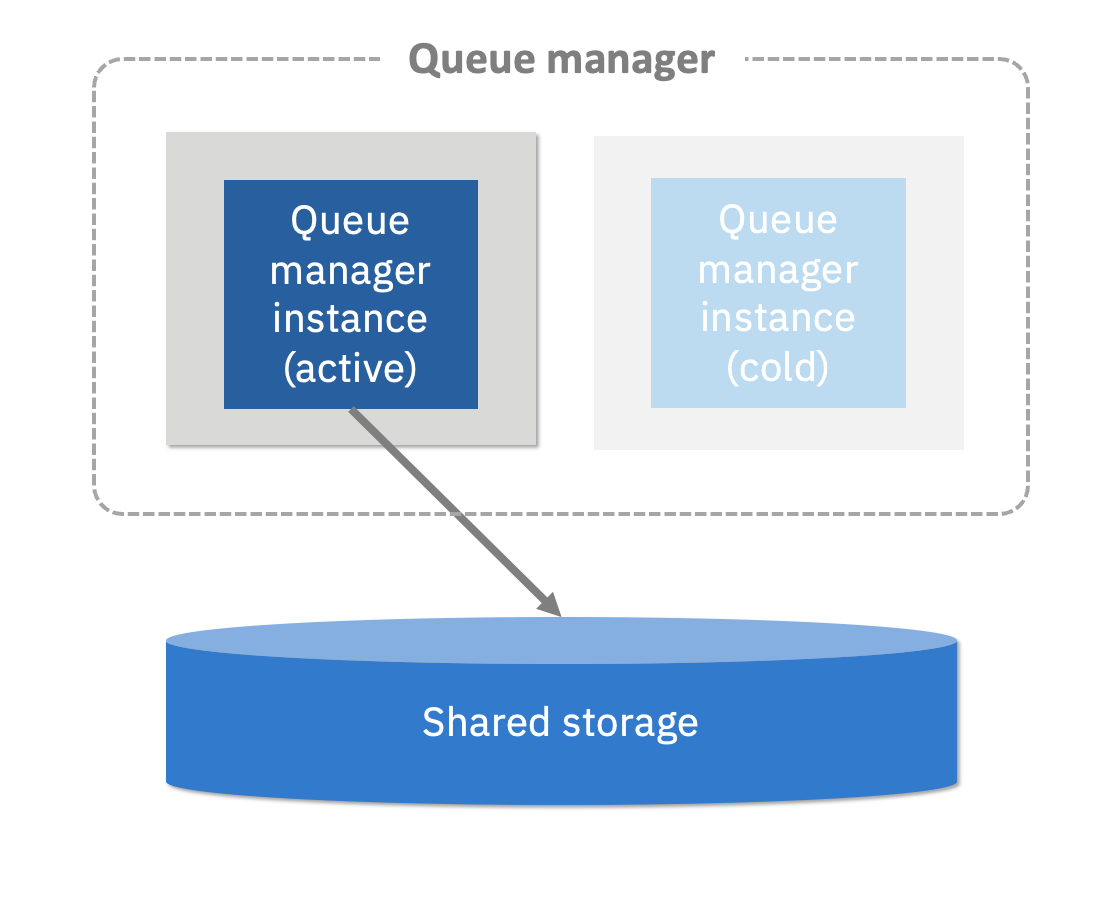
The external HA queue manager work well when availability requirements are quite relaxed, and in the same order of magnitude of time it takes to reinstate a component. However, the service availability is dependent on an HA mechanism that is beyond IBM MQ’s control. HA is therefore tied intrinsically to how the platform handles reinstatement, such as a separate HA solution or hypervisor reinstating a virtual machine or Kubernetes automatically reinstating a pod.
Message availability is dependent on the storage layer ensuring that the queue data has been replicated synchronously to wherever the queue manager will be reinstated. This will therefore require the configuration, operation and cost of relatively sophisticated storage replication.
A popular example today of a system that provides a level of automatic re-instatement of failed workload is Kubernetes. However, Kubernetes is cautious when state is involved, and nodes fail or become unreachable. In these situations, Kubernetes requires manual intervention to recover, to ensure that it does not introduce a “split brain” situation. For this reason, reinstatement times vary from quick to indefinite, requiring a manual intervention. This inconsistency makes it hard to assure the RTO for this option and is one of the reasons the later options were introduced.
In summary:
- Relatively simple approach with small footprint.
- Dependent on provision and support of fast externalised reliable storage.
- Dependant on an external HA mechanism for component reinstatement.
- Can be used in containers.
- Reinstatement can be in the order of minutes.
- RTO in Kubernetes can be very inconsistent.
IBM MQ horizontal scaling for active/active high availability
The options we’ve discussed so far cater to reinstating a single queue manager, along with all its messages, in the case of a failure, which is an active/passive approach where the entirety of the queue data is unavailable during the failover. With those techniques alone, it is possible to reduce the time span of a return to service down to a few seconds, which is sufficient for many asynchronous interactions.
If required, even higher availability can be achieved using an active/active approach whereby queue data is distributed across multiple separate active queue managers. This approach only works if the client application is also scaled to multiple active instances and global ordering of all messages is not required.
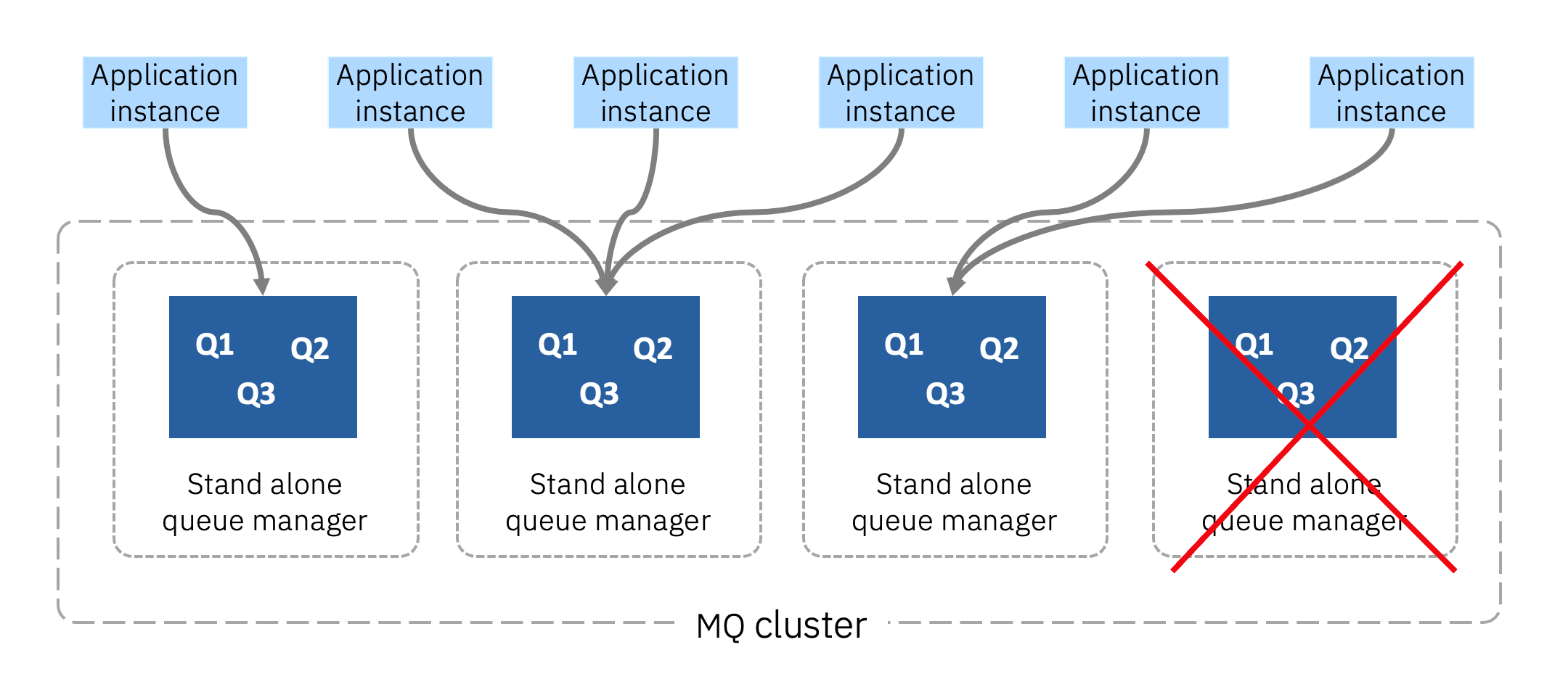
With this technique, if a queue manager needs to be reinstated, it only interrupts a fraction of the connected applications and you only lose access to a fraction of the messages during the failover. Both service and message availability only suffer a partial outage and most clients are completely unaffected. The more you scale out, the better the effect on improved availability. With 4 queue managers, only 25% of the connected clients and the associated queue data would see any effect during a single queue manager failover.
Having multiple queue managers also serves another purpose, which is enabling the throughput to be scaled horizontally. IBM MQ queue managers are incredibly efficient, and many requirements can be satisfied through vertical scaling (adding CPU to the queue manager). As such, it is rare that the limiting factor on performance will be CPU, and more often the limiting factor will be network or disk bandwidth. These too can be increased, but should you reach the limits of what you can reasonably provide on an individual infrastructure, horizontal scaling across multiple queue managers, across multiple nodes, opens up another dimension of potentially limitless scaling.
There is a compromise to horizontal scaling in stateful systems such as messaging. The purpose of horizontal scaling is to provide multiple completely independent systems to minimize the effect of a single failure. If you perform horizontal scaling with any stateful system, such as a message queue or topic, you inevitably partition the data. In many use cases, where each item of data is processed completely independently, this might have no consequences. However, if your application logic relies on strict ordering of messages within a queue, or correlation of messages across queues (for example, in request/response scenarios), you will need to design your application to be aware that your queue data is partitioned. This is really a separate topic beyond the scope of this article, but in short, it might involve ensuring that related data lands on the same queue partition or ensuring client applications always attach to the same partition.
If you implement horizontal scaling, you are restricting your ability to route messages around failures, implicitly pinning them to a single target, reducing the service and message availability as a result. Therefore, the first priority when trying to maximize availability with this approach is to remove messaging ordering requirements from the applications.
IBM MQ clustering
To implement an active/active MQ architecture, it is possible to statically set up a number of queue managers and statically associate application instances to them. However, it is typically more convenient to use IBM MQ’s in-built clustering.
It is perfectly reasonable for the queue managers within the cluster to also use a high availability mechanism. In the following diagram we see a cluster of queue managers, each of which is itself configured for Native HA.
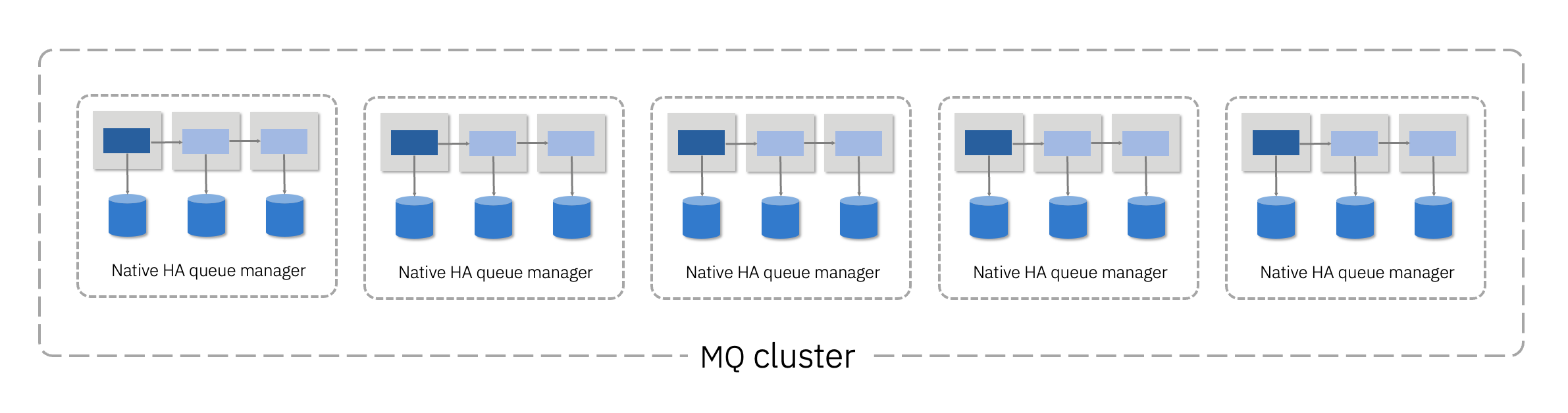
This combines all the benefits. From a message availability point of view Native HA minimizes the time each individual queue manager is down during a failover, and the cluster ensures that only a fraction of the messages are affected. From a service availability point of view, the cluster ensure a working queue manager is always available, and Native HA ensures the full set of queue managers are back in active service as fast as possible.
There are two types of clusters in MQ, both of which have a place in improving availability:
- MQ clusters (termed “traditional MQ clusters” in this article): The original type of cluster is simply known in the documentation as an MQ cluster. This can be used both for load balancing messages across queues (which is what we need for our horizontal scaling) and also for dynamically networking queue managers together across a landscape.
- Uniform clusters: Uniform clusters are a latterly introduced specialism of the traditional MQ cluster that ensures applications working a set of identical (uniform) queues, are distributed evenly across them.
A good comparison of the two cluster types is available in a separate article.
Let’s look at each of these in turn, and how they can each contribute to improving our availability characteristics.
Traditional MQ clustering to spread messages over multiple queues
A traditional MQ cluster is a collection of queue managers that are logically associated. They share information with each other about what queues they contain and what channels there are between them. Better still, they dynamically create MQ channels and the configuration needed to ensure the most efficient movement of messages through the cluster, which allows them to direct messages across the cluster to wherever a named queue resides. MQ clusters are one of the most important capabilities enabling MQ to create a messaging network.
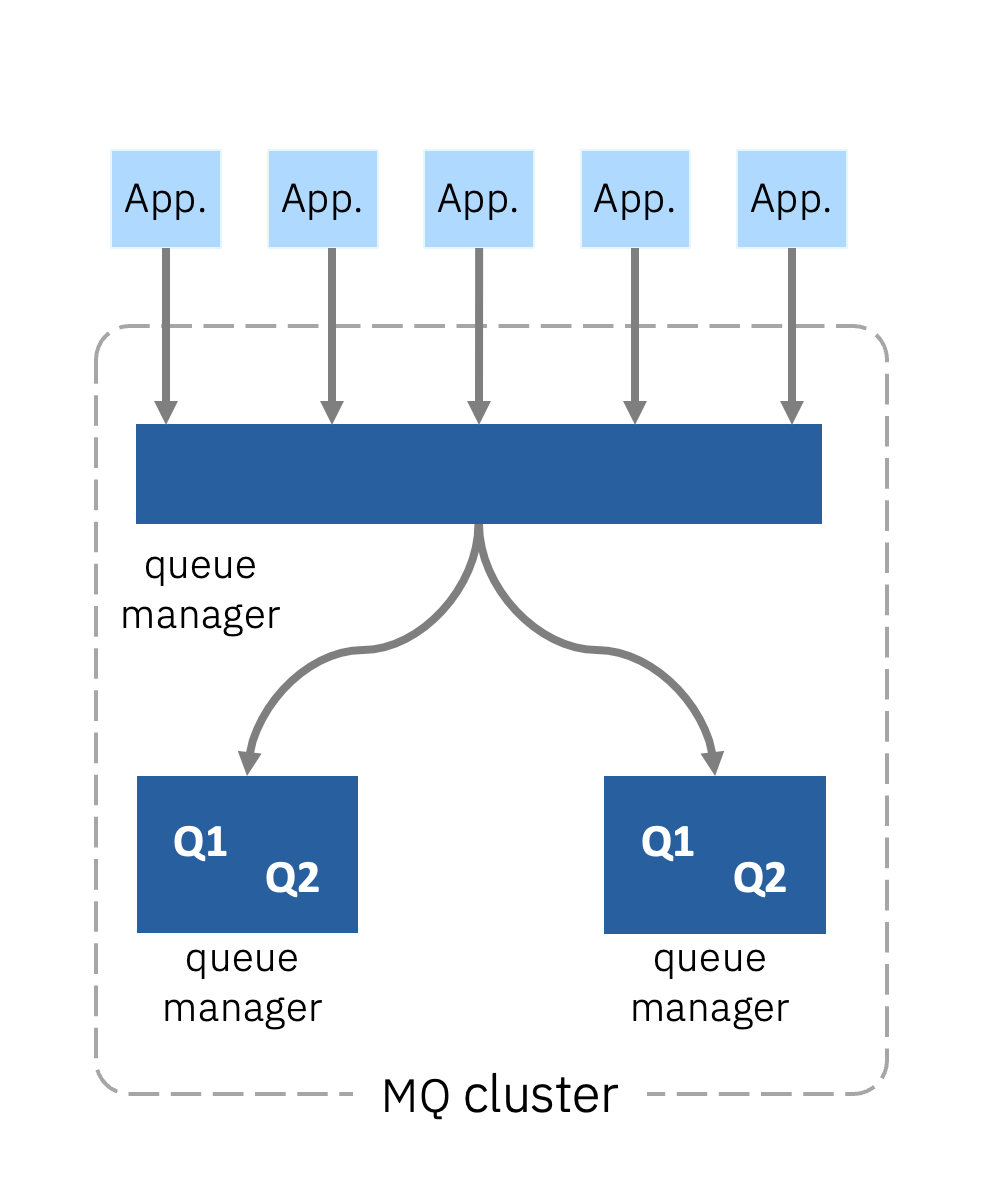
They also have one further capability that is particularly relevant here. If there is more than one destination queue of a given name, the cluster will automatically workload balance messages across those queues. MQ clusters is one of the simplest ways to configure horizontal scaling. This assumes of course that your application can also scale to provide an instance to feed from each of the queues.
Service availability is dramatically improved since if one of the queues is unavailable (such as because its queue manager down) the cluster will automatically redirect new and in-transit message traffic to the remaining queues of the same name such that they can be picked up by the receiving application instances.
Message availability is improved because we have now partitioned the messages across multiple queues. If a queue manager fails, only a portion of the messages become unavailable during a failover.
There will be a partial loss of message availability for messages that have already reached a queue if that queue manager suffers a failure. The high availability solutions of the queue manager discussed earlier will soon kick in and that subset of messages will get processed naturally when the queue manager is reinstated, which might only take a few seconds.
Uniform clusters to balance application clients
Applications’ connections to queue managers (also known as client connections) are deliberately “sticky” (which means they remain with the queue manager they first connected to) for reasons of efficiency of connection use. However, if an application instance fails, we want to redistribute other applications to work that queue manager to ensure the messages get processed, effecting our message availability. Equally, should a queue manager fail, we don’t want applications to sit idle, we need it to keep processing to retain the same overall message throughput, and avoid building up a message processing lag that again would affect message availability due to consumer lag.
This is where the “uniform cluster” comes in. A uniform cluster is a logical set of queue managers that have identical queues, channels, and other configurations (they are “uniform”). Applications connected to a unform cluster are automatically rebalanced if the load across them becomes uneven, and the applications themselves are unaware of this occurring, such as if a queue manager disappears, or one re-appears, or even if the workload distribution just becomes uneven over time. The uniform cluster ensures that we are always using each of the queue managers at their greatest efficiently. If an application instance goes down, another will take its place on that queue manager, minimizing the effect on message availability.
Taking our earlier example, we can see that the uniform cluster dynamically redistributes the application connections to MQ to ensure that there are an even number on each of the available queue managers.
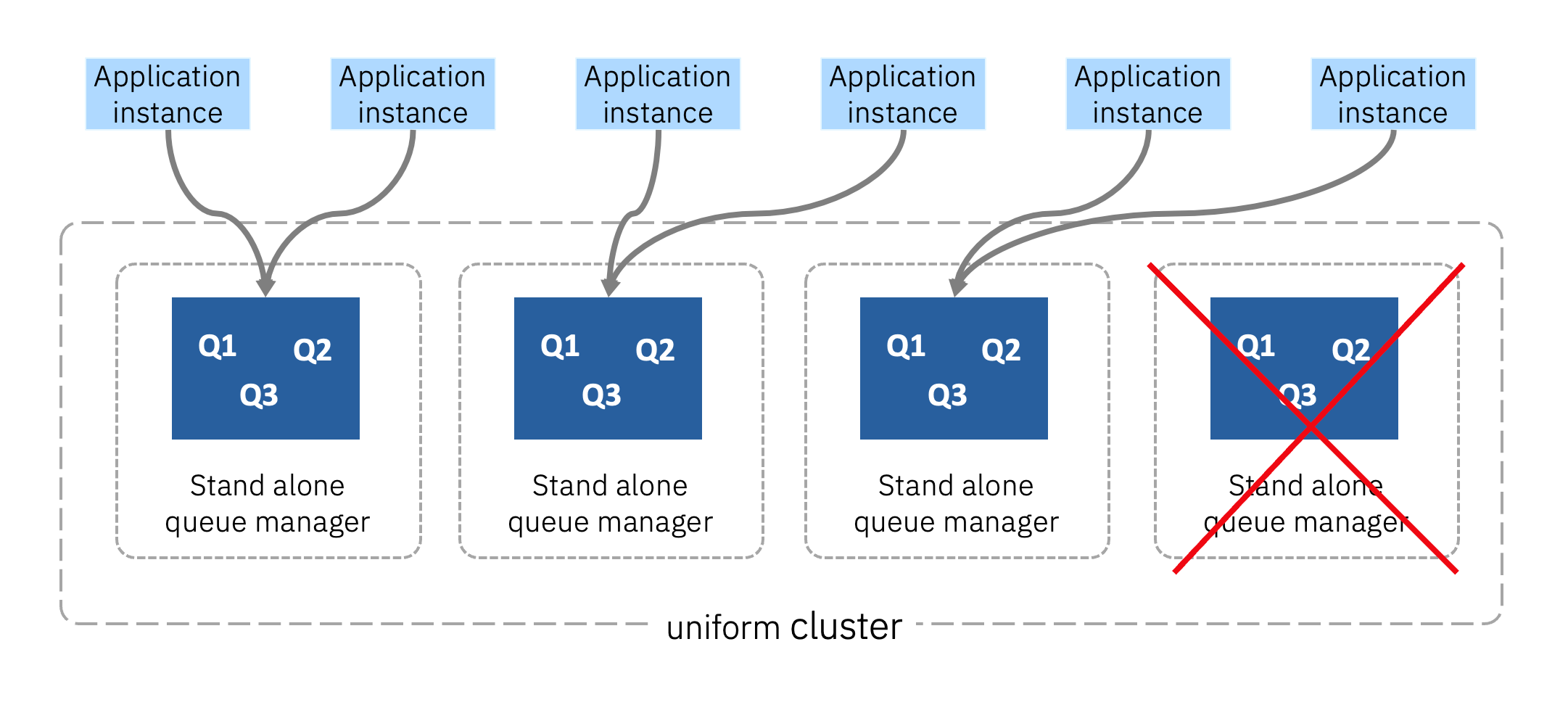
This constant balancing of connections enables a dynamic change in the number of queue managers within the cluster, with existing applications redistributed to take advantage of it automatically. Multiple applications might end up connected to the same queue manager, and this is perfectly acceptable. This “competing consumer” pattern is something messaging capabilities such as IBM MQ were designed to handle.
There are some edge cases to consider. What if an instance of a consuming application goes down and cannot be brought back up for a while? If you have plenty more application instances than queues, the unform clustering will happily find an application instance to move across and take its place. However, you do need to have at least the same number of application clients as queue managers, so what if there are no application instances that can be moved across and messages are temporarily orphaned on a queue manager. MQ clusters don’t automatically redistribute messages that have already landed on a destination queue. This is because it is typically preferable to wait for the application to return and consume them as planned. However, they can be moved automatically using utilities such as the “cluster queue monitor” (amqsclm) if required.
Learn more about uniform clustering in IBM MQ in this series of articles and tutorials.
IBM MQ disaster recovery (DR) options
The disaster scenario kicks in when it becomes clear that it will not be possible for the high availability mechanism to handle the failure. This could be due to region-wide events such as a power loss, an earthquake, flood, war, or pandemic. In such situations, the recovery sites must be sufficiently far away as to not be affected yet need to be as up-to-date on data as possible. These are opposing objectives: the further away it is, the harder it will be to keep the data in step.
For a site to be considered eligible for disaster recovery, it typically needs to be at least many hundreds of kilometers away from the main region. This is far enough that the network latency will be too significant for synchronous replication to be possible without dramatically slowing down the applications on the main site. For this reason, the technology options used for disaster recovery are typically different to those used for high availability and focus on asynchronous replication. The inevitable consequence is that there is a possibility of some data loss, hence it is almost certain that you will have to accept a Recovery Point Objective (RPO) > 0. RPO will be based on any lag in synchronization, and how long the main site continued running after connectivity was lost to the DR site. In a quiet period that could be zero, but with significant load on the system, the RPO will be greater than zero depending on bandwidth between sites and whether the main site continued after cross region connectivity was lost. The RTO is also likely to be significantly larger due to the seriousness of the situation and the coordination with the multiple systems involved.
If systems are designed for DR correctly, the main factor determining RTO and RPO in a disaster situation is generally not about technical limitations. It is the fact that it typically needs to be a manual decision to co-ordinate and perform the switchover to disaster recovery facilities.
For each of the high availability options mentioned earlier, there is a related disaster recovery technique best suited to that mechanism.
NativeHA Cross Region Replication (CRR)
Native HA CRR enables data replication asynchronously from one Kubernetes cluster to a second Kubernetes clusters using the same underlying technology as Native HA.
By definition, CRR is “cross region” which means synchronous replication would be impractical due to the network latency. For this reason, CRR is always asynchronous. In an unplanned switch over typical of a disaster recovery scenario, there is a possibility of some data loss (RPO>=0). However, CRR can also be used for planned switchover scenarios such as moving a queue manager to a different infrastructure. In this situation, there would be no data loss (RPO=0).
Unlike with RDQM, CRR does not reduce messaging performance when DR network capacity is exceeded. Instead, the RPO at the recovery site will increase due to the increased lag in replicated data flowing. For this reason, there are metrics available via the dspmq command that enable you to monitor how large the back log is and to what point in time you could recover to.
It's worth noting that the newly introduced CRR capability was featured in a recent presentation in TechCon 2025.
In summary:
- No storage replication technology is required.
- Replication is handled entirely by MQ with no external dependencies.
- Cross region replication is always asynchronous, but it is continuously replicating so provides a better RPO than periodic backups. RPO>=0 for unplanned DR. RPO=0 for planned switch over.
- No dependencies on specific operating system additions or configuration.
- Additional infrastructure is required for the DR site, and this has running “warm” queue managers in order to receive the replicated queue data.
Only runs on containers today.
Note: A statement of direction has been published regarding future provision of CRR in some non-container environments.
Replicated data queue manager: DR (RDQM:DR)
RDQM provides synchronous and asynchronous replication specifically designed for disaster recovery. It uses the same underlying technology as for high availability (DRBD). RDQM:DR can be used independently from RDQM:HA or in conjunction with it.
With RDQM:DR, performance degrades rapidly with increasing latency between data centers. IBM will support a latency of up to 5 millseconds for synchronous replication and 100 milliseconds for asynchronous replication. As a result, the synchronous option can only be used between sites in the same region with good network links. Full DR across regions will always have to be asynchronous.
Additional infrastructure is required for the RDQM:DR instance. When used in combination with RDQM:HA, RDQM:DR could requires 6 virtual machines, although multiple queue managers could be deployed on that infrastructure.
While the asynchronous DR replication doesn’t wait for confirmation from the recovery site, RDQM:DR does require sufficient capacity in the network and its buffering layers to send this stream of data. If the network bandwidth is too low for the rate of replicated message data being generated, the live site will slow down. This has the benefit of keeping the RPO low, but messaging performance might be adversely impacted as a result.
In summary:
- No separate storage replication technology is required but the queue manager infrastructure must be Red Hat Linux configured with DRBD.
- Replication to a separate region will require the asynchronous option.
- Additional infrastructure is required for the DR site, which must be warm from a DRBD perspective.
- Cannot run on containers due to the Linux kernel updates.
- Consistent RPO.
- Insufficient network bandwidth may reduce messaging performance.
DR options for external HA and multi-instance queue managers
For both external HA and for multi-instance queue managers, the main approach to DR is to perform asynchronous replication to the DR site of the storage that is used by the queue manager. With multi-instance queue managers, as mentioned previously, only certain storage types provide the necessary locking mechanisms.
Alternatively, or additionally, periodic backups of the queue data files can be performed to ensure you can restore to known points in time. The backup of the log and queue files needs to be done consistently using for example a LVM snapshot or by quiescing the queue manager before the backup.
The main concern here is that you must ensure that you have copied and synchronized all the right files in a way that ensures consistency across various aspects of the queue manager’s state. This requires a detailed knowledge of how IBM MQ works including the organization of the underlying file system. You also need to support this independent mechanism going forward. This is in contrast to the mechanisms described earlier where MQ itself performs the replication and the whole infrastructure is supported by IBM.
In summary:
- Separate technologies and processes beyond IBM MQ need to be configured, operated and maintained such as storage replication and periodic backups in order to provide for disaster recovery. It is important to consider how these will be supported, and what level of testing will be required to ensure they have been configured correctly.
- The queue manager infrastructure on the DR site doesn’t necessarily need to be provisioned in advance, it could be provisioned on demand depending on the DR RTO. The backed up/replicated storage must be present on that site though.
Do you always need data replication for DR?
It is natural to think that a non-zero RPO is still better than no data replication at all, but let’s think about that for a moment.
With messaging, you’re constantly changing the stored data by adding and removing messages on the queues. This is especially true if you follow the good practices of keeping your queue depths small. Queues with few messages will often run empty, rather than building up large backlogs of messages. So, it’s possible that the messages on your asynchronously replicated recovery site are significantly different to the contents of the live queues at the time of a disaster.
You should understand what that means to the applications using those queues. How will they handle this difference? Sometimes it can be clearer, after a true DR, to start from clean queues. This also saves you the complexity and cost of constantly replicating the data. Ultimately, this comes down to your needs, and, as we’ve seen, MQ supports you either way.
There also may be disaster scenarios where the main sites storage is still accessible even though the queue managers themselves cannot be started. In this situation, it might be best that the queue data files are directly copied to the DR site in order to ensure they are as up to date as possible.
Furthermore, there is the possibility that the queue managers are still running but are inaccessible to the applications. In this situation, a utility such as dmpmqmsg utility (formerly qload) would allow you to copy or move the contents of a queue to a file. This might provide a better recovery point than asynchronous replication that could be some way behind the main site.
All but the most catastrophic circumstances are covered by a good HA configuration across multiple sites in a region. And, due to its synchronous nature, it will have an RTO of zero. It’s worth considering whether the added complexity of the architecture, the operational support, and the additional infrastructure and licenses required for DR replication is worth it for the remaining disaster scenarios.
For many businesses it is worth it, and this is why we have evolved the mechanisms discussed in this article, but it’s still worth asking the question.
Conclusion
We’ve covered an enormous amount of detail, but it’s worth remembering that the initial set of choices narrow down quite quickly if you know your target platform.
For containers, and Linux on VMs or bare metal:
- The best and most advanced option in containers would be Native HA with the related Cross Region Replication for DR. This would give you rapid reinstatement and a fully supported, dependency-free approach to both HA and DR, all implemented within IBM MQ itself. It also removes another single point of failure by avoiding shared storage.
- Replicated Data Queue Manager (RDQM) is still an option, and since we have many customers on this technology, it will be supported for sometime into the future. However, the dependency on the DRBD update to the operating system has been shown to be complex to maintain and it is for this reason that we created the dependency free Native HA option. Generally speaking new features will be added to Native HA rather than to RDQM.
- A multi-instance queue manager is also still an option, but it is gradually falling out of favor due to the very specific requirements on storage types and the complexity of setting up replication for DR.
- An external HA queue manager would be the most basic option, but you’d have to set up and support your own reinstatement mechanism, as well as storage replication for DR. This could be costly and will require significant additional testing and operational attention. The HA RPO will be at least as long as it takes to start an operating system instance for VMs. From a container perspective this simply isn’t a very cloud native approach and may go against strategic guidelines.
For non-Linux (that is, Windows):
- The first choice here would be a multi-instance queue manager since neither Native HA nor RDQM are available beyond Linux. You’ll need to be aware of storage specifics around locking mechanisms and set up and support your own DR replication.
- An external HA queue manager would be the more basic option, but you’d have to set up and support your own reinstatement mechanism, as well as storage replication for DR, and the HA RPO will be at least as long as it takes to start an operating system instance.
However, remember, just because it is becoming easier to create and run your own queue managers doesn’t mean you have to! You could consider IBM MQ as a Service and let IBM run them for you. You could use an IBM MQ Appliance, which significantly simplifies the administration of queue managers, and has out of the box HA. Both of those options still enable you to automate the creation of queue managers and configuration of queues as part of your solution’s pipeline, so maybe you don’t need to choose between all the above options after all!
Acknowledgements
Sincere thanks to Anthony Beardsmore, Callum Jackson, Jon Rumsey and Dave Ware for their invaluable insights and technical review of this article.