

Elasticsearch features
Elasticsearch is a distributed, RESTful search and analytics engine that centrally stores your data so you can search, index, and analyze data of all shapes and sizes.
Data Storage
Flexibility
Search and analyze
Full-text search

Your incredibly fast search, our infrastructure
Spin up a free, 14-day trial of the Elasticsearch Service. No credit card required.
Management and operations
Management and operations
Scalability and resiliency
Elasticsearch operates in a distributed environment designed from the ground up for perpetual peace of mind. Our clusters grow with your needs — just add another node.
Clustering and high availability
A cluster is a collection of one or more nodes (servers) that together holds all of your data and provides federated indexing and search capabilities across all nodes. Elasticsearch clusters feature primary and replica shards to provide failover in the case of a node going down. When a primary shard goes down, the replica takes its place.
Learn about clustering and HAAutomatic node recovery
When a node leaves the cluster for whatever reason, intentional or otherwise, the master node reacts by replacing the node with a replica and rebalancing the shards. These actions are intended to protect the cluster against data loss by ensuring that every shard is fully replicated as soon as possible.
Learn about node allocationAutomatic data rebalancing
The master node within your Elasticsearch cluster will automatically decide which shards to allocate to which nodes, and when to move shards between nodes in order to rebalance the cluster.
Learn about automatic data rebalancingHorizontal scalability
As your usage grows, Elasticsearch scales with you. Add more data, add more use cases, and when you start to run out of resources, just add another node to your cluster to increase its capacity and reliability. And when you add more nodes to a cluster, it automatically allocates replica shards so you're prepared for the future.
Learn about scaling horizontallyRack awareness
You can use custom node attributes as awareness attributes to enable Elasticsearch to take your physical hardware configuration into account when allocating shards. If Elasticsearch knows which nodes are on the same physical server, in the same rack, or in the same zone, it can distribute the primary shard and its replica shards to minimize the risk of losing all shard copies in the event of a failure.
Learn about allocation awarenessCross-cluster replication
The cross-cluster replication (CCR) feature enables replication of indices in remote clusters to a local cluster. This functionality can be used in common production use cases.
Learn about CCRDisaster recovery: If a primary cluster fails, a secondary cluster can serve as a hot backup.
Geo-proximity: Reads can be served locally, decreasing network latency.
Cross-datacenter replication
Cross-datacenter replication has been a requirement for mission-critical applications on Elasticsearch for some time, and was previously solved partially with additional technologies. With cross-cluster replication in Elasticsearch, no additional technologies are needed to replicate data across datacenters, geographies, or Elasticsearch clusters.
Read about cross-datacenter replicationManagement and operations
Management
Elasticsearch comes with a variety of management tools and APIs to allow full control over data, users, cluster operations, and more.
Recover from snapshot
Elasticsearch clusters using cloud object storage can now transfer certain data like shard replication and shard recovery from ES nodes and object storage rather than transferring data between ES nodes thus reducing data transfer and storage costs.
Learn about recover from snapshotIndex lifecycle management
Index lifecycle management (ILM) lets the user define and automate policies to control how long an index should live in each of four phases, as well as the set of actions to be taken on the index during each phase. This allows for better control of cost of operation, as data can be put in different resource tiers.
Learn about ILMHot: actively updated and queried
Warm: no longer updated, but still queried
Cold/Frozen: no longer updated and seldom queried (search is possible, but slower)
Delete: no longer needed
Data tiers
Data Tiers are the formalized way to partition data into Hot, Warm and Cold nodes through a node role attribute that automatically defines the Index Lifecycle Management policy for your nodes. By assigning Hot, Warm, and Cold node roles, you can greatly simplify and automate the process of moving data from higher cost, higher performant storage to lower cost, lower performance storage, all without compromising insight.
Learn about Data tiers- Hot: actively updated and queried on most performant instance
Warm: data queried less frequently on lower performant instances
Cold: read only, seldom queried, significant storage reduction without performance degradation, powered by Searchable Snapshots
Snapshot lifecycle management
As a background snapshot manager, snapshot lifecycle management (SLM) APIs allow administrators to define the cadence with which to take snapshots of an Elasticsearch cluster. With a dedicated UI, SLM empowers users to configure retention for SLM policies and create, schedule, and delete snapshots automatically — ensuring that appropriate backups of a given cluster are taken on a frequent enough basis to be able to restore in compliance with customer SLAs.
Learn about SLMSnapshot and restore
A snapshot is a backup taken from a running Elasticsearch cluster. You can take a snapshot of either individual indices or the entire cluster and store the snapshot in a repository on a shared file system. There are plugins available that also support remote repositories.
Learn about snapshot and restoreSearchable snapshots
Searchable snapshots give you the ability to directly query your snapshots at a fraction of the time it would take to complete a typical restore-from-snapshot. This is achieved by reading only the necessary pieces of each snapshot index to complete the request. Together with the Cold Tier, Searchable snapshots can significantly reduce your data storage costs by backing up your replica shards in object based storage systems such as Amazon S3, Azure Storage or Google Cloud Storage while still providing full search access to them.
Learn about searchable snapshotsData rollups
Keeping historical data around for analysis is extremely useful but often avoided due to the financial cost of archiving massive amounts of data. Retention periods are thus driven by financial realities rather than by the usefulness of extensive historical data. The rollup feature provides a means to summarize and store historical data so that it can still be used for analysis, but at a fraction of the storage cost of raw data.
Learn about rollups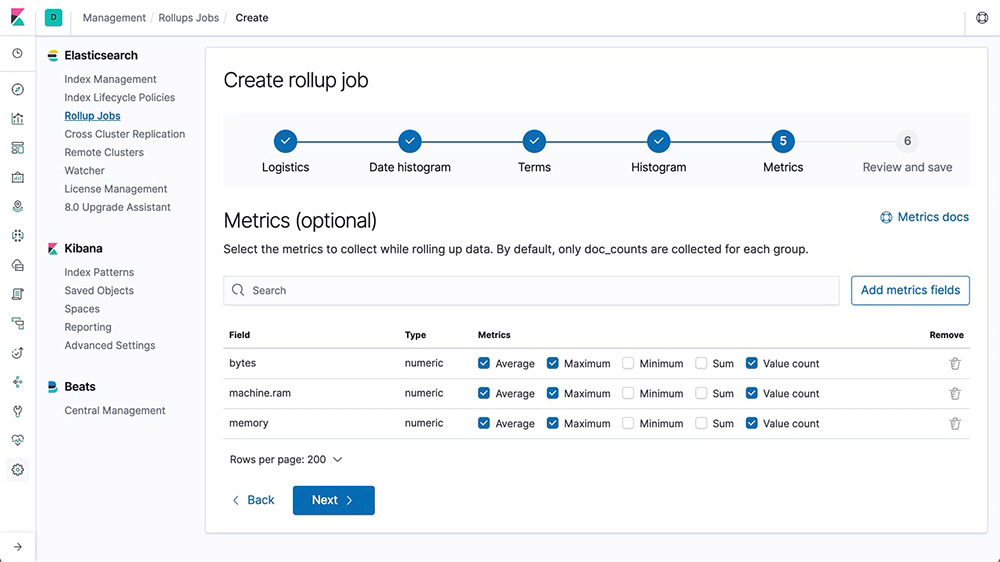
Data streams
Data streams are a convenient and scalable way to ingest, search, and manage continuously generated time-series data.
Learn more about data streamsTransforms
Transforms are two-dimensional, tabular data structures that make indexed data more digestible. Transforms perform aggregations that pivot your data into a new entity-centric index. By transforming and summarizing your data, it becomes possible to visualize and analyze it in alternative ways, including as a source for other machine learning analytics.
Learn about transformsUpgrade Assistant API
The Upgrade Assistant API allows you to check the upgrade status of your Elasticsearch cluster and reindex indices that were created in the previous major version. The assistant helps you prepare for the next major version of Elasticsearch.
Learn about the Upgrade Assistant APIAPI key management
The management of API keys needs to be flexible enough to allow users to manage their own keys, limiting access to their respective roles. Through a dedicated UI, users can create API keys and use them to provide long-term credentials while interacting with Elasticsearch, which is common with automated scripts or workflow integration with other software.
Learn about managing API keysManagement and operations
Security
The security features of the Elastic Stack give the right access to the right people. IT, operations, and application teams rely on these features to manage well-intentioned users and keep malicious actors at bay, while executives and customers can rest easy knowing data stored in the Elastic Stack is safe and secure.
Elasticsearch secure settings
Some settings are sensitive, and relying on filesystem permissions to protect their values is not sufficient. For this use case, Elasticsearch provides a keystore to prevent unwanted access to sensitive cluster settings. The keystore can optionally be password protected for additional security.
Learn more about secure settingsEncrypted communications
Network-based attacks on Elasticsearch node data can be thwarted through traffic encryption using SSL/TLS, node authentication certificates, and more.
Learn about encrypting communicationsEncryption at rest support
While the Elastic Stack does not implement encryption at rest out of the box, it is recommended that disk-level encryption be configured on all host machines. In addition, snapshot targets must also ensure that data is encrypted at rest.
Role-based access control (RBAC)
Role-based access control (RBAC) enables you to authorize users by assigning privileges to roles and assigning roles to users or groups.
Learn about RBAC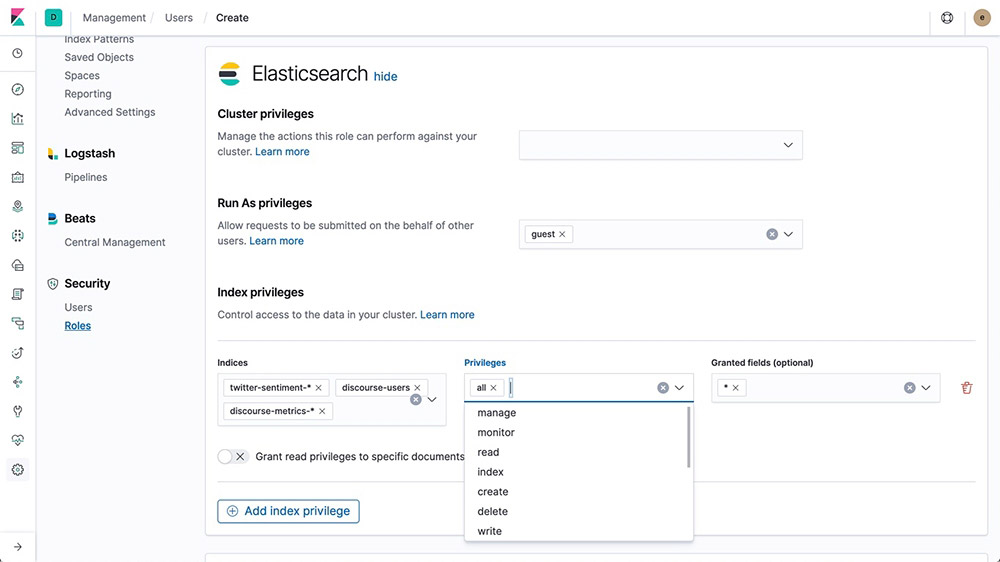
Attribute-based access control (ABAC)
The security features of the Elastic Stack also provide an attribute-based access control (ABAC) mechanism, which enables you to use attributes to restrict access to documents in search queries and aggregations. This allows you to implement an access policy in a role definition so users can read a specific document only if they have all the required attributes.
Learn about ABACField- and document-level security
Field-level security restricts the fields that users have read access to. In particular, it restricts which fields can be accessed from document-based read APIs.
Learn about field-level securityDocument-level security restricts the documents that users have read access to. In particular, it restricts which documents can be accessed from document-based read APIs.
Learn about document-level securityAudit logging
You can enable auditing to keep track of security-related events such as authentication failures and refused connections. Logging these events enables you to monitor your cluster for suspicious activity and provides evidence in the event of an attack.
Learn about audit loggingIP filtering
You can apply IP filtering to application clients, node clients, or transport clients, in addition to other nodes that are attempting to join the cluster. If a node's IP address is on the blacklist, the Elasticsearch security features allow the connection to Elasticsearch but it is dropped immediately and no requests are processed.
IP address or range
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Whitelist
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Hostname
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Learn about IP filtering
Security realms
The security features of the Elastic Stack authenticate users by using realms and one or more token-based authentication services. A realm is used to resolve and authenticate users based on authentication tokens. The security features provide a number of built-in realms.
Learn about security realmsSingle sign-on (SSO)
The Elastic Stack supports SAML single sign-on (SSO) into Kibana, using Elasticsearch as a backend service. SAML authentication allows users to log in to Kibana with an external identity provider, such as Okta or Auth0.
Learn about SSOThird-party security integration
If you are using an authentication system that is not supported out of the box with the security features of the Elastic Stack, you can create a custom realm to authenticate users.
Learn about third party securityManagement and operations
Alerting
The alerting features of the Elastic Stack give you the full power of the Elasticsearch query language to identify changes in your data that are interesting to you. In other words, if you can query something in Elasticsearch, you can alert on it.
Highly available, scalable alerting
There's a reason organizations large and small trust the Elastic Stack to handle their alerting needs. By reliably and securely ingesting data from any source, in any format, analysts can search, analyze, and visualize key data in real time — all with customized, reliable alerting.
Learn about alertingNotifications via email, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Link alerts with built-in integrations for email, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters, and Slack. Integrate with any other third-party system via a webhook output.
Learn about alert notification options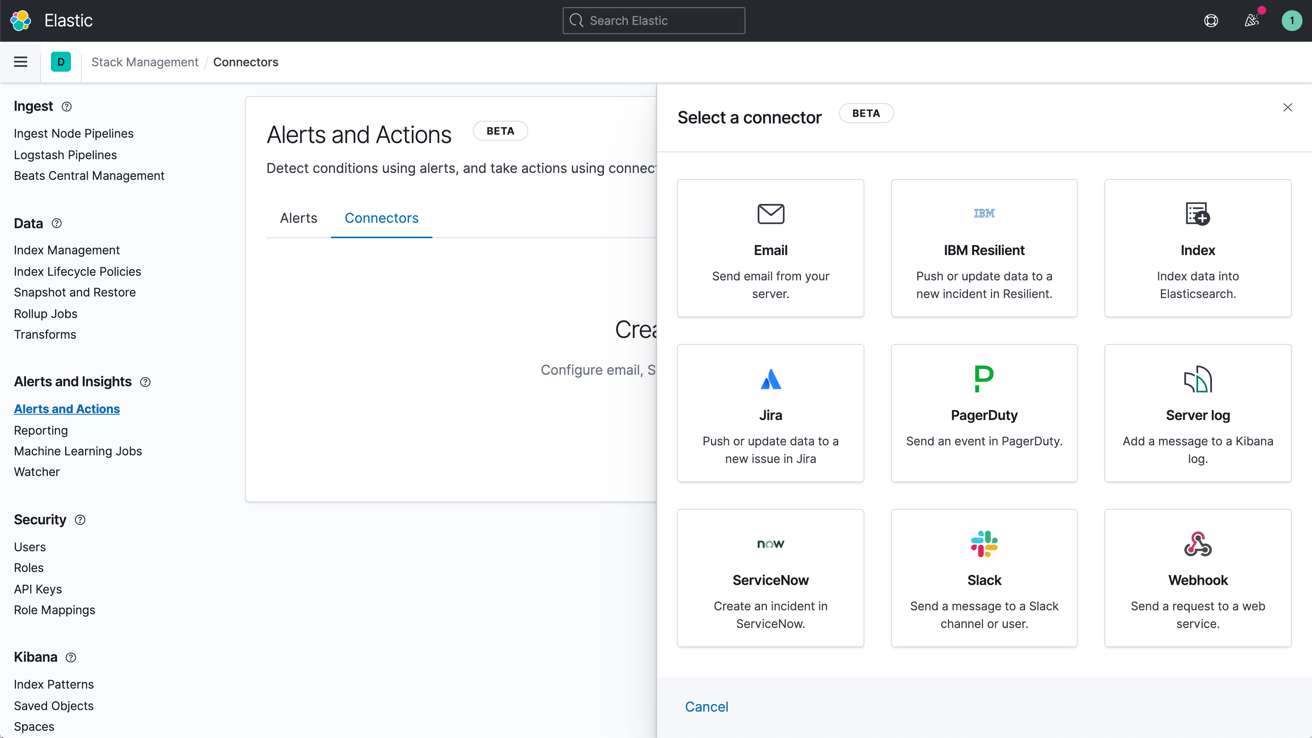
Management and operations
Clients
Elasticsearch allows you to work with data in whatever way you're most comfortable. With its RESTful APIs, language clients, robust DSL, and more (even SQL), we're flexible so you don't get stuck.
Language clients
Elasticsearch uses standard RESTful APIs and JSON. We also build and maintain clients in many languages such as Java, Python, .NET, SQL, and PHP. Plus, our community has contributed many more. They're easy to work with, feel natural to use, and, just like Elasticsearch, don't limit what you might want to do with them.
Explore the available language clientsElasticsearch DSL
Elasticsearch provides a full Query DSL (domain-specific language) based on JSON to define queries. Query DSL provides powerful search options for full-text search, including term and phrase matching, fuzziness, wildcards, regex, nest queries, geo queries, and more.
Learn about Elasticsearch DSLGET /_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL is a feature that allows SQL-like queries to be executed in real time against Elasticsearch. Whether using the REST interface, command line, or JDBC, any client can use SQL to search and aggregate data natively inside Elasticsearch.
Learn about Elasticsearch SQL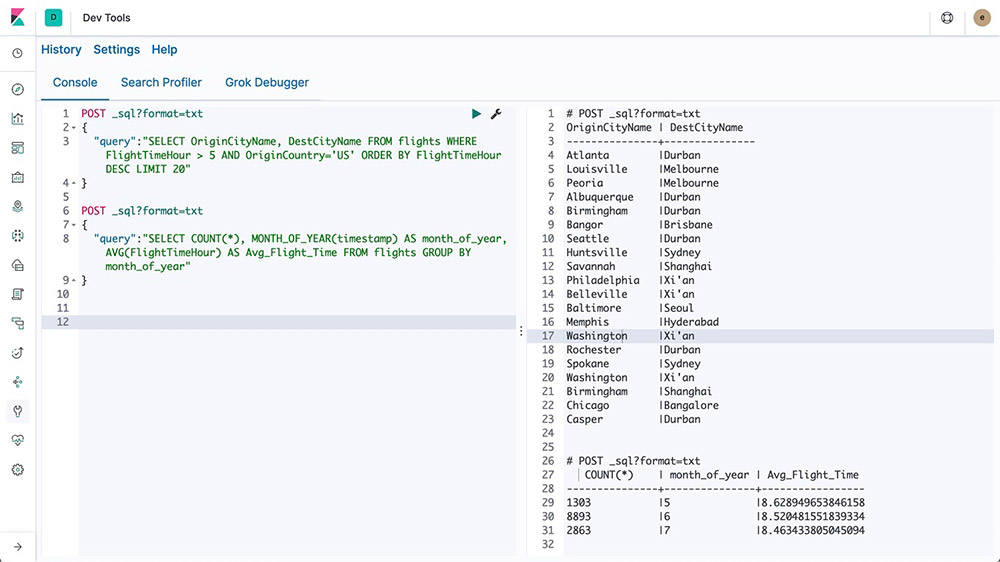
Event Query Language (EQL)
With the capability to query sequences of events matching specific conditions, Event Query Language (EQL) is purpose built for use cases like security analytics.
Learn about EQLJDBC client
The Elasticsearch SQL JDBC driver is a rich, fully featured JDBC driver for Elasticsearch. It is Type 4 driver, meaning it is a platform-independent, standalone, direct-to-database, pure Java driver that converts JDBC calls to Elasticsearch SQL.
Learn about the JDBC clientODBC client
The Elasticsearch SQL ODBC driver is a feature-rich 3.80 ODBC driver for Elasticsearch. It is a core-level driver, exposing all of the functionality accessible through the Elasticsearch SQL ODBC API, converting ODBC calls into Elasticsearch SQL.
Learn about the ODBC clientTableau Connector for Elasticsearch
The Tableau Connector for Elasticsearch makes it easy for Tableau Desktop and Tableau Server users to access data in Elasticsearch.
Download the Tableau ConnectorCLI tools
Elasticsearch provides a number of tools for configuring security and performing other tasks from the command line.
Explore the different CLI toolsManagement and operations
REST APIs
Elasticsearch provides a comprehensive and powerful REST API that you can use to interact with your cluster.
Document APIs
Perform CRUD operations (create, read, update, delete) on individual documents, or across multiple documents using document APIs.
Explore the available document APIsSearch APIs
The Elasticsearch search APIs allow you to implement more than just full-text search. They also help you implement suggesters (term, phrase, completion, and more), perform ranking evaluation, and even provide feedback about why a document was or wasn't returned with the search.
Explore the available search APIsAggregations APIs
The aggregations framework helps provide aggregated data based on a search query. It is based on simple building blocks called aggregations that can be composed in order to build complex summaries of the data. An aggregation can be seen as a unit of work that builds analytic information over a set of documents.
Explore the available aggregations APIsMetrics aggregations
Bucket aggregations
Pipeline aggregations
Matrix aggregations
Cumulative cardinality aggregations
Geohexgrid aggregations
Ingest APIs
Use the ingest APIs to perform CRUD operations on your data pipelines, or use the simulate pipeline API to execute a specific pipeline against the set of documents.
Explore the available ingest APIsManagement APIs
Manage your Elasticsearch cluster programatically with a variety of management-related APIs. There are APIs for the management of indices and mappings, clusters and nodes, licensing and security, and much more. And if you need your results in a human-readable format, just use the cat APIs.
Management and operations
Integrations
As an open source, language-agnostic application, it's easy to extend the functionality of Elasticsearch with plugins and integrations.
Elasticsearch-Hadoop
Elasticsearch for Apache Hadoop (Elasticsearch-Hadoop or ES-Hadoop) is an open source, stand-alone, self-contained, small library that allows Hadoop jobs to interact with Elasticsearch. Use it to easily build dynamic, embedded search applications to serve your Hadoop data or perform deep, low-latency analytics using full-text, geospatial queries and aggregations.
Learn about ES-HadoopApache Hive
Elasticsearch for Apache Hadoop offers first-class support for Apache Hive, a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop-compatible file systems.
Learn about the Apache Hive integrationApache Spark
Elasticsearch for Apache Hadoop offers first-class support for Apache Spark, a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, and Python, and an optimized engine that supports general execution graphs.
Learn about the Apache Spark integrationBusiness intelligence (BI)
Thanks to its JDBC and ODBC interfaces, a broad range of third-party BI applications can use Elasticsearch SQL capabilities.
Explore the available BI and SQL integrationsPlugins and integrations
As an open source, language-agnostic application, it's easy to extend the functionality of Elasticsearch with plugins and integrations. Plugins are a way to enhance the core Elasticsearch functionality in a custom manner, while integrations are external tools or modules that make it easier to work with Elasticsearch.
Explore the available Elasticsearch pluginsAPI extension plugins
Alerting plugins
Analysis plugins
Discovery plugins
Ingest plugins
Management plugins
Mapper plugins
Security plugins
Snapshot/restore repository plugins
Store plugins
Management and operations
Deployment
Public cloud, private cloud, or somewhere in between — we make it easy for you to run and manage Elasticsearch.
Download and install
It's as easy as ever to get started. Just download and install Elasticsearch and Kibana as an archive or with a package manager. You'll be indexing, analyzing, and visualizing data in no time. And with the default distribution, you can also test out Platinum features such as machine learning, security, graph analytics, and more with a free 30-day trial.
Download the Elastic StackElastic Cloud
Elastic Cloud is our growing family of SaaS offerings that make it easy to deploy, operate, and scale Elastic products and solutions in the cloud. From an easy-to-use hosted and managed Elasticsearch experience to powerful, out-of-the-box search solutions, Elastic Cloud is your springboard for seamlessly putting Elastic to work for you. Try any of our Elastic Cloud products for free for 14 days — no credit card required.
Get started in Elastic CloudStart a free trial of Elasticsearch Service
Elastic Cloud Enterprise
With Elastic Cloud Enterprise (ECE), you can provision, manage, and monitor Elasticsearch and Kibana at any scale, on any infrastructure, while managing everything from a single console. Choose where you run Elasticsearch and Kibana: physical hardware, virtual environment, private cloud, private zone in a public cloud, or just plain public cloud (e.g., Google, Azure, AWS). We've covered them all.
Try ECE free for 30 daysElastic Cloud on Kubernetes
Built on the Kubernetes Operator pattern, Elastic Cloud on Kubernetes (ECK) extends the basic Kubernetes orchestration capabilities to support the setup and management of Elasticsearch and Kibana on Kubernetes. With Elastic Cloud on Kubernetes, simplify the processes around deployment, upgrades, snapshots, scaling, high availability, security, and more for running Elasticsearch in Kubernetes.
Deploy with Elastic Cloud on KubernetesHelm Charts
Deploy in minutes with the official Elasticsearch and Kibana Helm Charts.
Read about the official Elastic Helm ChartsDocker containerization
Run Elasticsearch and Kibana on Docker with the official containers from Docker Hub.
Run the Elastic Stack on DockerIngest and enrich
Ingest and enrich
Ingest
Get data into the Elastic Stack any way you want. Use RESTful APIs, language clients, ingest nodes, lightweight shippers, or Logstash. You aren't limited to a list of languages, and since we're open source, you're not even limited in the type of data that can be ingested. If you need to ship a unique data type, we provide the libraries and steps for creating your own unique ingest methods. And if you want, you can share them back with the community so the next person doesn't have to reinvent the wheel.
Clients and APIs
Elasticsearch uses standard RESTful APIs and JSON. We also build and maintain clients in many languages such as Java, Python, .NET, SQL, and PHP. Plus, our community has contributed many more. They're easy to work with, feel natural to use, and, just like Elasticsearch, don't limit what you might want to do with them.
Ingest node
Elasticsearch offers a variety of node types, one of which is specifically for ingesting data. Ingest nodes can execute pre-processing pipelines, composed of one or more ingest processors. Depending on the type of operations performed by the ingest processors and the required resources, it may make sense to have dedicated ingest nodes that will only perform this specific task.
Beats
Beats are open source data shippers that you install as agents on your servers to send operational data to Elasticsearch or Logstash. Elastic provides Beats for capturing a variety of common logs, metrics, and other various data types.
Auditbeat for Linux audit logs
Filebeat for log files
Functionbeat for cloud data
Heartbeat for availability data
Journalbeat for systemd journals
Metricbeat for infrastructure metrics
Packetbeat for network traffic
Winlogbeat for Windows event logs
Logstash
Logstash is an open source data collection engine with real-time pipelining capabilities. Logstash can dynamically unify data from disparate sources and normalize the data into destinations of your choice. Cleanse and democratize all your data for diverse advanced downstream analytics and visualization use cases.
Community shippers
If you have a specific use case to solve, we encourage you to create a community Beat. We've created an infrastructure to simplify the process. The libbeat library, written entirely in Go, offers the API that all Beats use to ship data to Elasticsearch, configure the input options, implement logging, and more.
With 100+ community-contributed Beats, there are agents for Cloudwatch logs and metrics, GitHub activities, Kafka topics, MySQL, MongoDB Prometheus, Apache, Twitter, and so much more.
Explore the available community-developed BeatsIngest and enrich
Data enrichment
With a variety of analyzers, tokenizer, filters, and enrichment options, Elasticsearch turns raw data into valuable information.
Elastic Common Schema
Uniformly analyze data from diverse sources with the Elastic Common Schema (ECS). Detection rules, machine learning jobs, dashboards, and other security content can be applied more broadly, searches can be crafted more narrowly, and field names are easier to remember.
Processors
Use an ingest node to pre-process documents before the actual document indexing happens. The ingest node intercepts bulk and index requests, it applies transformations, and it then passes the documents back to the index or bulk APIs. Ingest node offers over 25 different processors, including append, convert, date, dissect, drop, fail, grok, join, remove, set, split, sort, trim, and more.
Analyzers
Analysis is the process of converting text, like the body of any email, into tokens or terms which are added to the inverted index for searching. Analysis is performed by an analyzer which can be either a built-in analyzer or a custom analyzer defined per index using a combination of tokenizers and filters.
Example: Standard Analyzer (default)
Input: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Output: the 2 quick brown foxes jumped over the lazy dog's bone
Tokenizers
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. The tokenizer is also responsible for recording the order or position of each term (used for phrase and word proximity queries) and the start and end character offsets of the original word which the term represents (used for highlighting search snippets). Elasticsearch has a number of built-in tokenizers which can be used to build custom analyzers.
Example: Whitespace tokenizer
Input: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Output: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filters
Token filters accept a stream of tokens from a tokenizer and can modify tokens (e.g., lowercasing), delete tokens (e.g., remove stopwords), or add tokens (e.g., synonyms). Elasticsearch has a number of built-in token filters which can be used to build custom analyzers.
Character filters are used to pre-process the stream of characters before it is passed to the tokenizer. A character filter receives the original text as a stream of characters and can transform the stream by adding, removing, or changing characters. Elasticsearch has a number of built-in character filters which can be used to build custom analyzers.
Learn about character filtersLanguage analyzers
Search in your own language. Elasticsearch offers over 30 different language analyzers, including many languages with non-Latin character sets like Russian, Arabic, and Chinese.
Dynamic mapping
Fields and mapping types do not need to be defined before being used. Thanks to dynamic mapping, new field names will be added automatically, just by indexing a document.
Match enrich processor
The match ingest processor allows users to look up data at the time of ingestion and indicates the index from which to pull enriched data. This helps Beats users that need to add a few elements to their data — rather than pivoting from Beats to Logstash, users can consult the ingest pipeline directly. Users will also be able to normalize data with the processor for better analytics and more common queries.
Geo-match enrich processor
The geo-match enrich processor is a useful and practical way to allow users to improve their search and aggregation capabilities by leveraging their geo data without needing to define queries or aggregations in geo coordinate terms. Similar to the match enrich processor, users can look up data at the time of ingestion and find the optimal index from which to pull enriched data.
Data Storage
Data Storage
Flexibility
The Elastic Stack is a powerful solution that can be thrown at almost any use case. And while it's best known for its advanced search capabilities, its flexible design makes it an optimal tool for many different needs, including document storage, time series analysis and metrics, and geospatial analytics.
Data types
Elasticsearch supports a number of different data types for the fields in a document, and each of those data types offers its own multiple subtypes. This allows you to store, analyze, and utilize data in the most efficient and effective way possible, regardless of the data. Some of the types of data Elasticsearch is optimized for include:
text
Shapes
Numbers
Vectors
Histogram
Date/time series
Flattened field
Geo-points/geo-shapes
Unstructured data (JSON)
Structured data
Full-text search (inverted index)
Elasticsearch uses a structure called an inverted index, which is designed to allow very fast full-text searches. An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears. To create an inverted index, we first split the content field of each document into separate words (which we call terms, or tokens), create a sorted list of all the unique terms, and then list in which document each term appears.
Document store (unstructured)
Elasticsearch does not require data to be structured in order to be ingested or analyzed (though structuring will improve speeds). This design makes it simple to get started, but also makes Elasticsearch an effective document store. Though Elasticsearch is not a NoSQL database, it still provides similar functionality.
Time series / analytics (columnar store)
An inverted index allows queries to look up search terms quickly, but sorting and aggregations require a different data access pattern. Instead of looking up the term and finding documents, they need to be able to look up the document and find the terms that it has in a field. Doc values are the on-disk data structure in Elasticsearch, built at document index time, which makes this data access pattern possible, allowing search to occur in a columnar fashion. This lets Elasticsearch excel at time series and metrics analysis.
Geospatial (BKD trees)
Elasticsearch uses the BKD tree structures within Lucene to store geospatial data. This allows for the efficient analysis of both geo-points (latitude and longitude) and geo-shapes (rectangles and polygons).
Data Storage
Security
Security doesn't stop at the cluster-level. Keep data safe all the way down to the field-level within Elasticsearch.
Field- and document-level API security
Field-level security restricts the fields that users have read access to. In particular, it restricts which fields can be accessed from document-based read APIs.
Document-level security restricts the documents that users have read access to. In particular, it restricts which documents can be accessed from document-based read APIs.
Learn about document-level securityData encryption at rest support
While the Elastic Stack does not implement encryption at rest out of the box, it is recommended that disk-level encryption be configured on all host machines. In addition, snapshot targets must also ensure that data is encrypted at rest.
Data Storage
Management
Elasticsearch gives you the ability to fully manage your clusters and their nodes, your indices and their shards, and most importantly, all the data held within.
Clustered indices
A cluster is a collection of one or more nodes (servers) that together holds all of your data and provides federated indexing and search capabilities across all nodes. This architecture makes it simple to scale horizontally. Elasticsearch provides a comprehensive and powerful REST API and UIs that you can use to manage your clusters.
Data snapshot and restore
A snapshot is a backup taken from a running Elasticsearch cluster. You can take a snapshot of either individual indices or the entire cluster and store the snapshot in a repository on a shared file system. There are plugins available that also support remote repositories.
Rollup indices
Keeping historical data around for analysis is extremely useful but often avoided due to the financial cost of archiving massive amounts of data. Retention periods are thus driven by financial realities rather than by the usefulness of extensive historical data. The rollup feature provides a means to summarize and store historical data so that it can still be used for analysis, but at a fraction of the storage cost of raw data.
Search and analyze
Search and analyze
Full-text search
Elasticsearch is known for its powerful full-text search capabilities. Its speed comes from an inverted index at its core and its power comes from its tunable relevance scoring, advanced query DSL, and wide range of search enhancing features.
Inverted index
Elasticsearch uses a structure called an inverted index, which is designed to allow very fast full-text searches. An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears. To create an inverted index, we first split the content field of each document into separate words (which we call terms, or tokens), create a sorted list of all the unique terms, and then list in which document each term appears.
Runtime fields
A runtime field is a field that is evaluated at query time (schema on read). Runtime fields can be introduced or modified at any time, including after the documents have been indexed, and can be defined as part of a query. Runtime fields are exposed to queries with the same interface as indexed fields, so a field can be a runtime field in some indices of a data stream and an indexed field in other indices of that data stream, and queries need not be aware of that. While indexed fields provide optimal query performance, runtime fields complement them by introducing flexibility to change the data structure after the documents have been indexed.
Lookup runtime field
Lookup runtime fields gives you the flexibility of adding information from a lookup index to results from a primary index by defining a key on both indices that links documents. Like runtime fields, this feature is used at query time providing flexible data enrichment.
Cross-cluster search
The cross-cluster search (CCS) feature allows any node to act as a federated client across multiple clusters. A cross-cluster search node won't join the remote cluster; instead, it connects to a remote cluster in a light fashion in order to execute federated search requests.
Relevance scoring
A similarity (relevance scoring / ranking model) defines how matching documents are scored. By default, Elasticsearch uses BM25 similarity — an advanced, TF/IDF-based similarity that has built-in tf normalization optimal for short fields (like names) — but many other similarity options are available.
Vector search (ANN)
Building off of Lucene 9's new approximate nearest neighbor or ANN support based on HNSW algorithm, the new _knn_search API endpoint facilitates a more scalable and performant search by vector similarity. It does that by enabling a trade off between recall and performance, i.e. enabling much better performance on very large datasets (compared with the existing brute force vector similarity method) by making a minor compromises on recall.
Query DSL
Full-text search requires a robust query language. Elasticsearch provides a full Query DSL (domain-specific language) based on JSON to define queries. Create simple queries to match terms and phrases, or develop compound queries that can combine multiple queries. Additionally, filters can be applied at query time to remove documents before they're given a relevance score.
Asynchronous search
The asynchronous search API enables users to run long-running queries in the background, track query progress, and retrieve partial results as they become available.
Highlighters
Highlighters enable you to get highlighted snippets from one or more fields in your search results so you can show users where the query matches are. When you request highlights, the response contains an additional highlight element for each search hit that includes the highlighted fields and the highlighted fragments.
Type ahead (auto-complete)
The completion suggester provides auto-complete/search-as-you-type functionality. This is a navigational feature to guide users to relevant results as they are typing, improving search precision.
Suggesters (did-you-mean)
The phrase suggester adds did-you-mean functionality to your search by building additional logic on top of the term suggester to select entire corrected phrases instead of individual tokens weighted based on ngram-language models. In practice this suggester will be able to make better decisions about which tokens to pick based on co-occurrence and frequencies.
Corrections (spell check)
The term suggester is at the root of spell check, suggesting terms based on edit distance. The provided suggest text is analyzed before terms are suggested. The suggested terms are provided per analyzed suggest text token.
Percolators
Flipping the standard search model of using a query to find a document stored in an index, percolators can be used to match documents to queries stored in an index. The percolate query itself contains the document that will be used as a query to match with the stored queries.
Query profiler/optimizer
The profile API provides detailed timing information about the execution of individual components in a search request. It provides insight into how search requests are executed at a low level so you can understand why certain requests are slow and take steps to improve them.
Permissions-based search results
Field-level security and document-level security restrict search results to only what users have read access to. In particular, it restricts which fields and documents can be accessed from document-based read APIs.
Dynamically updateable synonyms
Using the analyzer reload API, you can trigger reloading of the synonym definition. The contents of the configured synonyms file will be reloaded and the synonyms definition the filter uses will be updated. The _reload_search_analyzers API can be run on one or more indices and will trigger reloading of the synonyms from the configured file.
Results pinning
Promotes selected documents to rank higher than those matching a given query. This feature is typically used to guide searchers to curated documents that are promoted over and above any "organic" matches for a search. The promoted or "pinned" documents are identified using the document IDs stored in the _id field.
Search and analyze
Analytics
Searching for data is just a start. Powerful analytical features of Elasticsearch allow you take the data you've searched for and find deeper meaning. Whether through aggregating results, finding relationships between the documents, or creating alerts based on threshold values, it's all built on a foundation of powerful search functionality.
Aggregations
The aggregations framework helps provide aggregated data based on a search query. It is based on simple building blocks called aggregations that can be composed in order to build complex summaries of the data. An aggregation can be seen as a unit-of-work that builds analytic information over a set of documents.
Metrics aggregations
Bucket aggregations
Pipeline aggregations
Matrix aggregations
Geohexgrid aggregations
Random sampler aggregations
Graph exploration
The Graph explore API enables you to extract and summarize information about the documents and terms in your Elasticsearch index. The best way to understand the behavior of this API is to use Graph in Kibana to explore connections.
Search and analyze
Machine learning
Elastic machine learning features automatically model the behavior of your Elasticsearch data — trends, periodicity, and more — in real time to identify issues faster, streamline root cause analysis, and reduce false positives.
Forecasting on time series
After Elastic machine learning creates baselines of normal behavior for your data, you can use that information to extrapolate future behavior. Then create a forecast to estimate a time series value at a specific future date or estimate the probability of a time series value occurring in the future
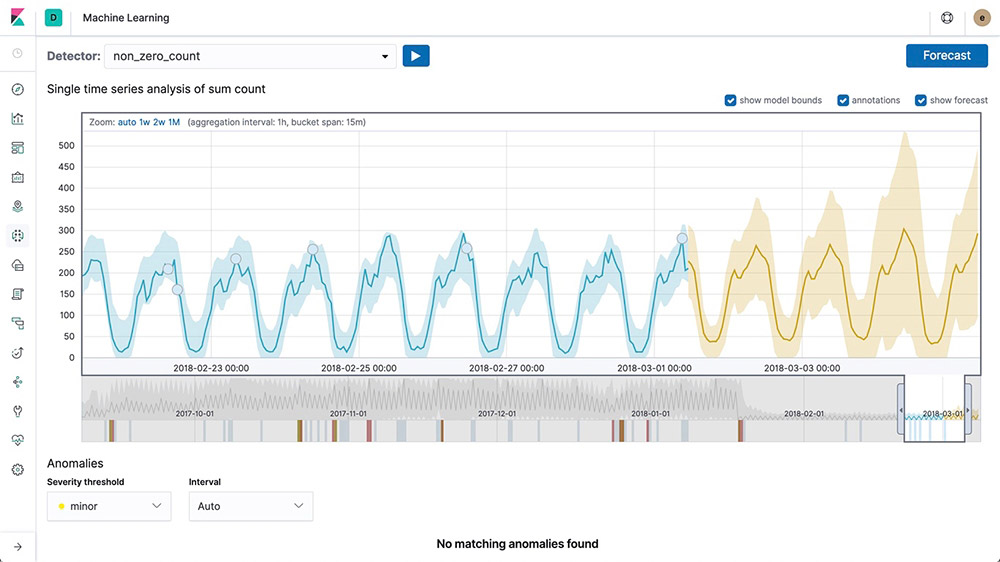
Anomaly detection on time series
Elastic machine learning features automate the analysis of time series data by creating accurate baselines of normal behavior in the data and identifying anomalous patterns in that data. Anomalies are detected, scored, and linked with statistically significant influencers in the data using proprietary machine learning algorithms.
Anomalies related to temporal deviations in values, counts, or frequencies
Statistical rarity
Unusual behaviors for a member of a population
Alerting on anomalies
For changes that are harder to define with rules and thresholds, combine alerting with unsupervised machine learning features to find the unusual behavior. Then use the anomaly scores in the alerting framework to get notified when problems arise.
Inference
Inference enables you to use supervised machine learning processes – like regression or classification – not only as a batch analysis but in a continuous fashion. Inference makes it possible to use trained machine learning models against incoming data.
Language identification
Language identification is a trained model that you can use to determine the language of text. You can reference the language identification model in an inference processor.