Beyond RAG basics: Advanced strategies for AI applications


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Our recent virtual event with Cohere dove deep into the world of retrieval augmented generation (RAG), focusing on the critical considerations for building RAG applications beyond the proof-of-concept stage. Our speakers, Lily Adler, principal solutions architect at Elastic, and Maxime Voisin, senior product manager at Cohere, shared valuable insights on the challenges, solutions, and best practices in this evolving field of natural language processing (NLP).
Why build a stack of solutions to complement large language models?
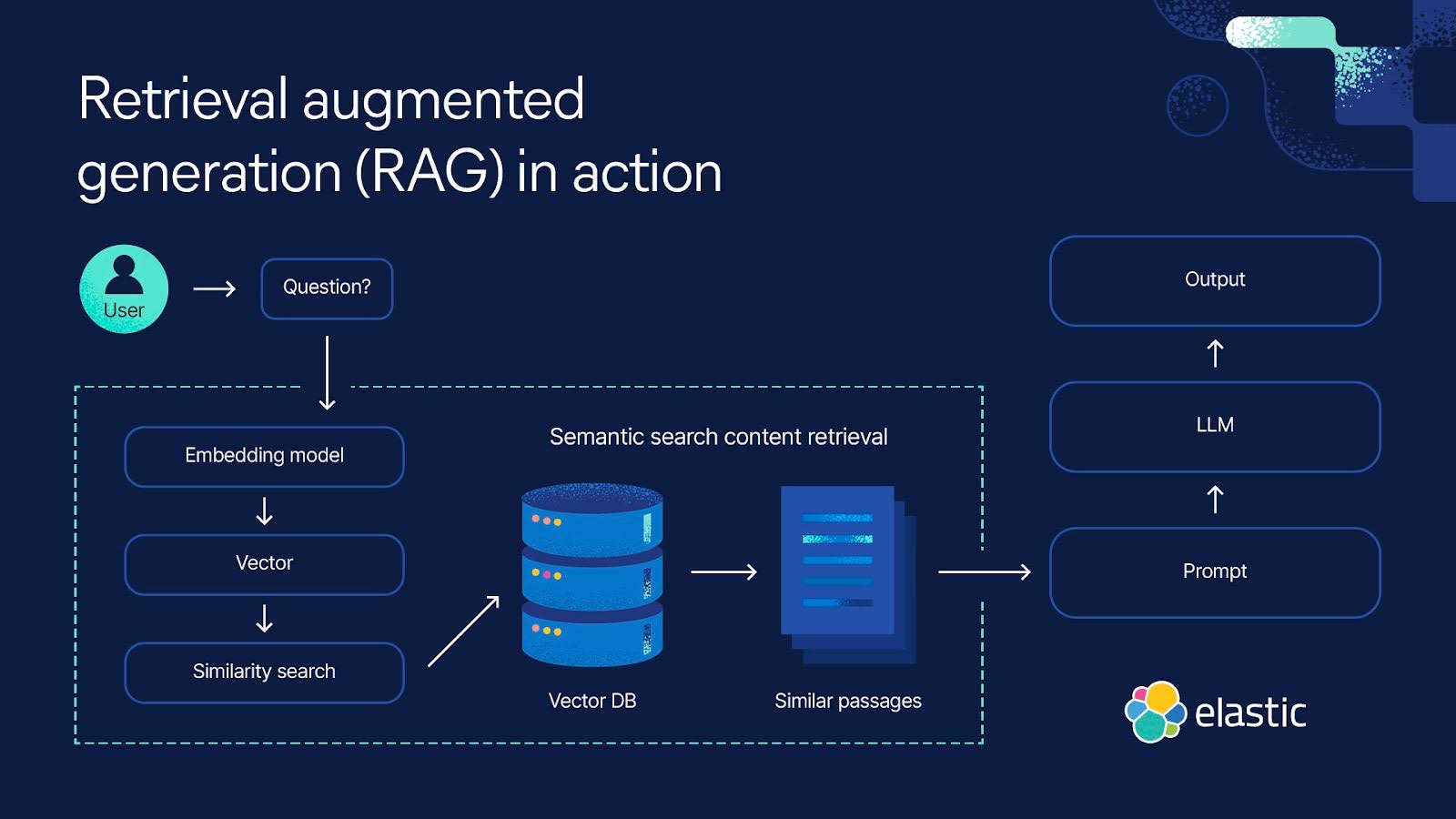
Large language models (LLMs) are powerful but far from perfect. They often make absurd mistakes like suggesting putting glue on pizza or eating rocks — errors stemming from their training data without an inherent layer of logic. This is where RAG comes in, adding a crucial layer of control and context to help ground responses from the LLM. RAG is all about integrating relevant information retrieval systems with LLMs to enhance text generations. By grounding LLMs in contextually relevant data, RAG not only boosts response accuracy but also offers significant advantages in cost reduction and overall control. It helps in leveraging external knowledge sources, making the AI outputs more reliable and relevant.
Your RAG is only as good as your retrieval engine. And there's no magic bullet to make it perfect. But there are a few best practices.
Maxime Voisin, Senior Product Manager (RAG) at Cohere
Understanding RAG architecture
A basic RAG architecture begins with user questions, using vector databases to retrieve relevant data, such as documents, images, and audio. This data then provides essential context for the LLM to generate a more accurate response.
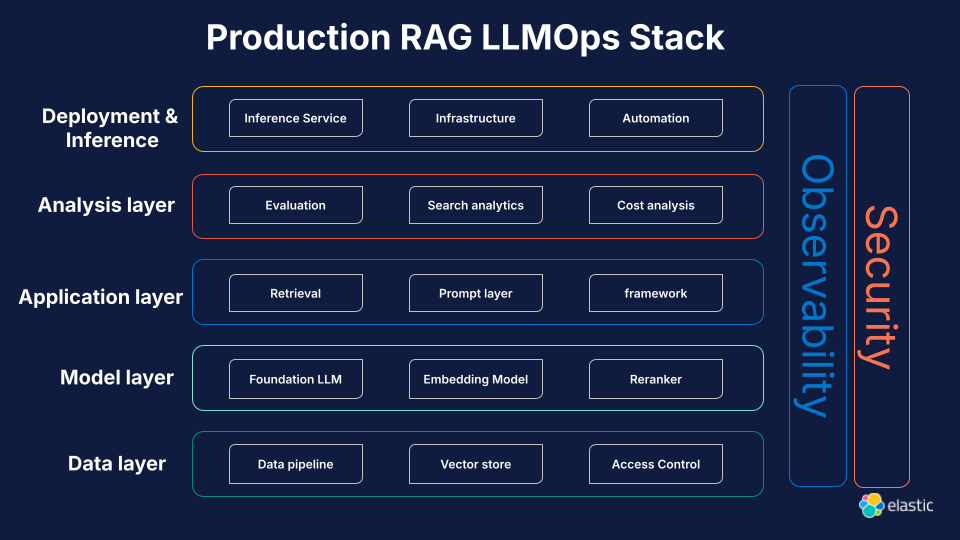
However, an advanced RAG setup involves several layers with each playing a pivotal role:
Data layer: Determines the type (structured or unstructured) and storage of information. Effective data management is crucial for high-quality information retrieval.
Model layer: Incorporates foundational LLMs and embedding models. Fine-tuning these models is essential for handling specific tasks and improving performance in text generations.
Application layer: Manages retrieval, prompts, and application logic, ensuring seamless integration of relevant documents into the workflow.
- Analysis and deployment layers: Ensure the solution is fit for purpose and efficiently deployed. Continuous analysis helps in refining model performance and adapting to new data.
Strategic data layer management
Effective RAG solutions begin with a thorough understanding of the data landscape. When dealing with unstructured data like images or documents or structured data, such as databases, a robust chunking strategy is indispensable:
Large vs. small chunks: Balancing context richness with precision. Large chunks provide more context but may reduce precision while small chunks are more precise but may lack complete information.
Token overlapping: Ensuring continuous context across chunks, which helps in maintaining coherence in the retrieved information.
Collapsing relevant chunks: Maintaining precision while always referencing the source for validation, ensuring the reliability of the information provided.
Security and legal considerations are also paramount. Access control mechanisms (LDAP, Active Directory) and privacy concerns, such as redacting sensitive information using named entity recognition, must be carefully managed to ensure compliance and user trust. These measures are essential to prevent data spills and unauthorized access to sensitive information.
Evaluating the model layer
Using human-labeled data sets and appropriate metric choices (recall vs. precision) are fundamental for effective information retrieval. Additionally, cost and speed are critical factors, necessitating trade-offs among these elements:
Recall: Ensuring all relevant documents are retrieved. High recall is crucial in legal or compliance scenarios where missing relevant information can have significant consequences.
Precision: Ensuring the retrieved documents are highly relevant to the query. High precision is important in consumer applications to avoid user frustration.
Effective fine-tuning of the LLMs is critical for optimizing these metrics and improving the overall performance of the RAG system.
Addressing challenges in generative models
To increase verifiability and reduce hallucinations in generative models, use models that provide citations, choose those with lower hallucination rates, and improve context window utilization. This will enhance coherence in the generated text. Additionally, models trained specifically for RAG applications can significantly reduce the likelihood of inaccuracies and improve the overall reliability of the system.
LLMs make mistakes, humans make mistakes as well, although LLMs make mistakes that are a bit more silly because there's not that layer of logic for LLM.
Lily Alder, Principal Solutions Architect at Elastic

Beyond RAG basics: Strategies and best practices
Join us to explore advanced techniques in retrieval augmented generation (RAG) and elevate your RAG systems.
Advanced RAG techniques
Parallel queries: Handling multipart questions with parallel search queries significantly improves response accuracy in RAG systems, making them adept at tackling complex user requests. This technique enables the system to break down and address different parts of a query simultaneously, ensuring a comprehensive and accurate response.
RAG with tools: Extending RAG capabilities by integrating tools to handle complex data types (such as spreadsheets and SaaS apps) opens new possibilities for AI applications like workplace assistants. This incorporation allows RAG systems to interact with external knowledge sources, providing more comprehensive answers. For example, querying a database or a spreadsheet to provide data-driven responses can enhance the utility of the system in business and productivity applications.
- Agentic RAG: Equipping RAG systems with agentic capabilities allows for sequential reasoning and dynamic planning, making them robust against more complex queries. Agentic RAG systems can utilize multiple tools and adjust their plans based on the results they gather. This flexibility allows for more sophisticated problem-solving abilities and can handle intricate tasks that require multiple steps and logical reasoning.
Deploying retrieval augmented generation at scale
Scaling RAG solutions involves addressing three main areas:
Cost management: Choose efficient models and optimize vector search databases to control costs effectively. Cost analysis and regular monitoring can help in identifying areas for optimization, ensuring the solution remains cost-effective.
Security and reliability: Implement disaster recovery, service level objectives, and adopt a site reliability engineering (SRE) approach to ensure robust infrastructure. These measures help in maintaining uptime and reliability, which is critical for production environments.
- Continuous analysis: Utilize observability tools to monitor and evaluate LLM responses over time, adapting to changes and ensuring consistent performance. Continuous evaluation helps in maintaining the quality of information retrieval and adjusting to any evolving requirements.
Practical implementation strategies
Several tools and frameworks, such as LangChain, LlamaIndex, Autogen, and Cohere's API, offer out-of-the-box solutions to implement advanced RAG systems efficiently. Leveraging these tools can help you avoid starting from scratch, accelerating deployment and reducing overhead. They provide prebuilt components for information retrieval and natural language processing tasks, enabling faster and more reliable implementations.
For example, LangChain can help in building complex workflows by chaining different processes while LlamaIndex offers efficient indexing solutions for fast retrieval. Autogen, on the other hand, simplifies the generation of responses by providing a range of preconfigured settings and templates.
Collaborations and resources
Elastic and Cohere have been at the forefront of information retrieval and RAG research and development. Here’s how you can dive deeper into RAG:
Watch the full webinar: Beyond RAG basics: Strategies and best practices for implementing RAG.
Test the latest AI search capabilities with AI Playground, a free hands-on lab covering how to build RAG systems.
- For further reading and hands-on workshops, visit Elastic Search Labs. This resource offers valuable information, tutorials, and code samples pertinent to various RAG use cases, including tutorials for using Elastic with Cohere.
Start a free trial to get started building apps with search AI.
By understanding the intricacies of RAG and implementing best practices in natural language processing, you can build robust AI applications that leverage external knowledge sources for more accurate and reliable responses. Whether you are focusing on simple RAG systems or more advanced implementations, the goal is to create solutions that are scalable, cost-effective, and provide value through precise information retrieval and text generations.
The Elastic AI Ecosystem
Cohere is a valued partner in the Elastic AI Ecosystem which offers developers pre-built Elasticsearch vector database integrations from a trusted network of industry-leading AI companies to deliver seamless access to the critical components of GenAI applications across AI models, cloud infrastructure, MLOps frameworks, data prep and ingestion platforms, and AI security & operations.
These integrations help developers:
Deliver more relevant experiences through RAG
Prepare and ingest data from multiple sources
Experiment with and evaluate AI models
Leverage GenAI development frameworks
Observe and securely deploy AI applications
Originally published on August 13, 2024; Updated December 17, 2024.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

