elasticsearch Serverless
Pay only for what you use, with no infrastructure hassle. Discover the art of the possible with AI search, RAG-ready tools, and data analytics capabilities.
Pricing detailsIngest*
As low as $0.14
Per VCU per hour Search*
As low as $0.09
Per VCU per hour Machine Learning
As low as $0.07
Per VCU per hour Storage & Retention
As low as $0.047
Per GB retained per month Egress
As low as $0.05 Per GB
Per GB transferred per month *Vector profiles receive 50 GB free
Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant
$4.50 Per million input tokens$21 Per million output tokens Elastic Inference Service: ELSER on GPU
As low as $0.08
Per million output tokens |
|
| Ingest*Per VCU per hour | As low as $0.14 |
| Search*Per VCU per hour | As low as $0.09 |
| Machine LearningPer VCU per hour | As low as $0.07 |
| Storage & RetentionPer GB retained per month | As low as $0.047 |
| EgressPer GB transferred per month *Vector profiles receive 50 GB free |
As low as $0.05
|
| Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant |
$4.50
Per million input tokens
$21
Per million output tokens
|
| Elastic Inference Service: ELSER on GPUPer million output tokens |
As low as $0.08
|
*These prices take effect December 1, 2024.
Ingest and retention metering is based on the uncompressed, normalized, fully enriched data volume that you ingest into your serverless project. Metered volumes will be much higher than the "raw" or compressed data size "on the wire."
Support package
Limited support is included with a Standard subscription; all other support pricing is based on the percentage of your consumption. For more information on what's included in each support level, please go to elastic.co/support.
| Elastic Cloud organization subscription level* | Standard | Gold | Platinum | Enterprise |
|---|---|---|---|---|
| Support and total bill | ||||
| Support level | Limited | Base | Enhanced | Premium |
| % of charge | Included | 5% | 10% | 15% |
*Subscription level is selected during sign up
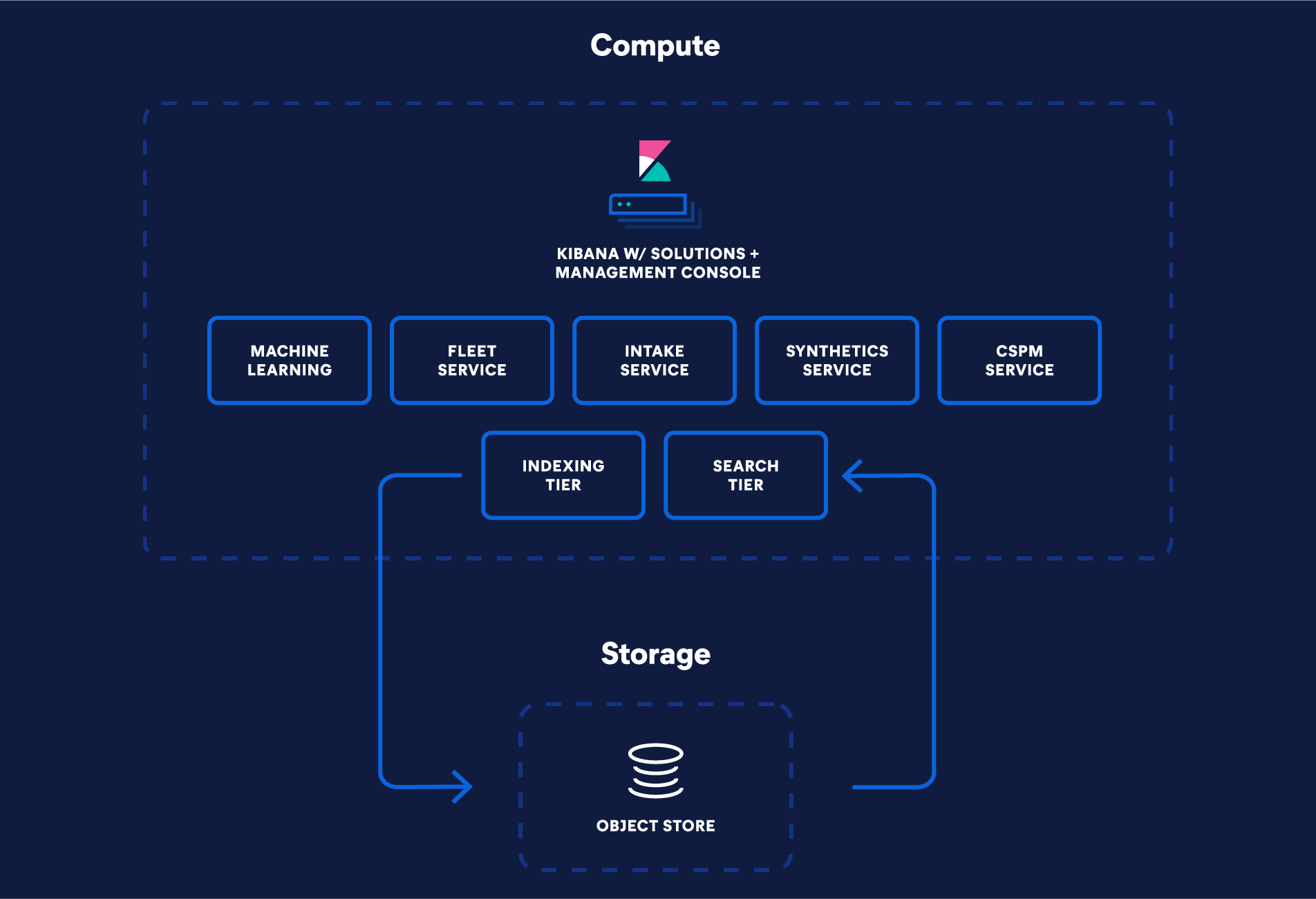
elasticsearch Serverless pricing components
elasticsearch Serverless charges separately for compute (VCUs with 1GB RAM) and storage (GB), offering scalable, performance-driven pricing to meet your latency and throughput goals.

Virtual Compute Unit (VCU)
There are three specialized VCU types available to perform specific tasks.
Ingest VCUs: Handle data indexing into the Search AI Lake.
Search VCUs: Handle user driven searches, alerting rules, aggregations, transforms and geospatial queries against data in the Search AI Lake.
Machine Learning VCUs: Manage inference, ELSER workloads, and machine learning jobs.

Token usage
Elastic Managed Large Language Model usage per million Input and Output tokens: Leverage AI-powered search as a service without deploying a large language model (LLM) in your project.
ELSER usage charged per million tokens: Leverage ELSER on GPU for semantic search use cases

Adaptive resource provisioning
Ingest and ML compute resources automatically scale to meet workload demands.
Search compute resources dynamically adjust to workloads, ensuring consistent performance and responsiveness. With flexible Search Power settings, you have control over resource allocations to meet your performance needs.

Storage & retention
elasticsearch Serverless uses object stores for persistent storage in the Search AI Lake.
All data, regardless of type, recency, and frequency of use, is accessible from the Search AI Lake. The size of the Search AI Lake can be controlled with manual or managed data retention policies.
Storage is measured in GB.

Configurations
Two infrastructure configurations are available for elasticsearch Serverless: general purpose and vector (API only).
The general purpose option is used by default for all new projects and is appropriate for most use cases.
The vector option allocates more VCUs to your project for higher performance, but it also incurs additional costs due to the higher VCU allocation. This option is only recommended for projects using dense_vector field mappings with int4 or int8, with high dimensionality.
The same elasticsearch, just easier
Frequently asked questions
Serverless projects use the core components of the Elastic Stack, such as elasticsearch and Kibana, and are based on Elastic’s Search AI Lake architecture that decouples compute and storage. Search and indexing operations are separated, which offers flexibility for scaling your workloads while ensuring a high level of performance.
Enjoy the following benefits with elasticsearch Serverless:
- Management free. Elastic manages the underlying Elastic cluster, so you can focus on your data. With serverless projects, Elastic is responsible for automatic upgrades, data backups, and business continuity.
- Autoscaled. To meet your performance requirements, the system automatically adjusts to your workloads.
- Optimized data storage. Your data is stored in the Search Lake of your project, which serves as a cost-efficient and performant storage. A high performance layer is available on top of the Search Lake for your most queried data.
- Pay for the performance you need. Pay for ingest, search, and ML resources separately as needed by the workloads you run.
Elastic Cloud is a powerful platform that accommodates many computing needs. Serverless projects are purpose built for use cases while providing a fully managed autoscaled experience. This specialization and operational model is what sets serverless apart today.
elasticsearch Serverless is currently available on select Cloud provider regions, with some features yet to come in the future. We are fully invested in expanding our serverless offering to more regions and cloud providers. We recommend checking the documentation for technical compatibility such as security, compliance, and availability.
It's simple to get started on elasticsearch Serverless:
- Create elasticsearch Serverless projects in the Cloud Console.
- Choose the use case-optimized project type that is most fitting for your needs.
- Get started with your use-case optimized project experience.
We recommend sending data directly from your application or using Connector clients. For sending data in an existing elasticsearch instance, we recommend using Logstash to migrate large volumes.
Search Power settings allow you to manage the compute resources to optimize search performance (throughput and latency) and manage costs. There are three Search Power settings for elasticsearch Serverless projects. The Performant setting is on by default and provides a performant search experience for data of all sizes. It is possible to choose any one of the following settings:
On-demand: Autoscales based on data and search load with a lower minimum baseline for resource use. This flexibility results in more variable query latency and reduced maximum throughput.
Performant: Delivers consistently low latency and will autoscale to accommodate moderately high query throughput
High-throughput: Optimized for high-throughput scenarios, autoscaling to maintain query latency even at very high query volumes
In elasticsearch Serverless, you pay for the resources used to handle your workloads and performance needs. We have a few examples to give you an idea about what you could pay, and how to think about costs.
Example 1 - Dev environment with 2GB searchable data, 1% ingest utilization (15 minutes per day), 8% search utilization (2 hours per day)
- On-demand: $24/month
- Performant: $27/month
Example 2 - Prod environment with 20GB searchable data, 5% ingest utilization (1 hour per day), 33% search utilization (8 hours per day)
- On-demand: $190/month
- Performant: $210/month
*The pricing estimates provided in the examples are for illustrative purposes only. Actual costs may vary based on factors such as data type, query complexity, traffic patterns, usage duration, and specific configurations. These estimates are intended to help you understand potential pricing scenarios but should not be relied upon as a final cost. For precise cost calculations, we recommend monitoring your usage.
The General Purpose profile offers a great performance for the price especially for most search use cases. It is the right profile for full-text search, semantic search using ELSER or sparse vector embeddings, sparse vectors and dense vectors using compression such as BBQ (default on serverless). We recommend using the General Purpose instance for most search use cases.
We recommend using the Vector Optimized profile only for uncompressed dense vectors when you want better performance. Though the per VCU cost is the same for General Purpose and Vector Optimized profile, the Vector Optimized profile provides a larger amount of RAM for searchable data, so it leads to higher VCU consumption, and is more expensive while providing significantly better performance for uncompressed vector data.
Discover everything you can do with Elastic Cloud Serverless