Article
Data ingestion into watsonx.data for the enterprise
Key features, best practices, and benefits of ingesting data from IBM Db2 on Cloud into watsonx.data with DataStage on IBM Cloud Pak for Data
On this page
Data ingestion is the process of importing and loading data into IBM watsonx.data. Watsonx.data auto discovers the schema based on the source file being ingested. IBM Storage Ceph, IBM Cloud Object Storage, Amazon Web Services (AWS) S3, and MinIO are supported as the object storage buckets. Data can be ingested through the watsonx.data web catalog or the command-line interface (CLI).
Introduction to watsonx.data
The watsonx.data platform is an IBM lakehouse solution that uses an open data lakehouse architecture that combines data warehouse and data lake technologies. It provides fast, reliable, and efficient big data processing in the petabytes range that lets you choose from multiple fit-for-purpose engines based on your workload requirements, allowing you to optimize on cost.
It supports vendor-agnostic open formats like Apache Iceberg and Apache Hive meta store, which enables different engines to access and share data simultaneously. Its architecture fully separates the compute, metadata, and storage to offer flexibility. A cost-effective, simple object storage is also available.
The integrated Milvus vector database can be used to create vectorized embeddings for generative AI use cases. It allows for an open, hybrid, and governed data store to scale analytics and AI with all of your data wherever the data resides. The platform combines data from public clouds, private clouds, and on-premises infrastructures, and removes silos. This approach lets organizations leverage the scalability and flexibility of public cloud services while retaining control over sensitive data and applications in the private cloud or on premises.
As a governed data store that is optimized for all data and AI workloads, watsonx.data provides for greater value from your analytics ecosystem and puts AI to work. It integrates with IBM solutions and third-party services for easy development and deployment of use cases. This article explains how you can use IBM DataStage on IBM Cloud Pak for Data for data ingestion into watsonx.data.
As you read through this article, it’s a good idea to have:
- A basic understanding of developing DataStage jobs on IBM Cloud Pak for Data.
- Experience in IBM watsonx.data, IBM Cloud Object Storage, and IBM Db2 on Cloud. You can use this guide to get started with Db2 on Cloud.
- Assess to watsonx.data SaaS on IBM Cloud. The solution discussed in the article was developed on watsonx.data V1.1 on IBM Cloud.
- Access to an IBM Cloud Object Storage bucket. Refer to Getting started with IBM Cloud Object Storage for more information.
Watsonx.data data ingestion pattern
The following image shows a watsonx.data data ingestion pattern with DataStage.
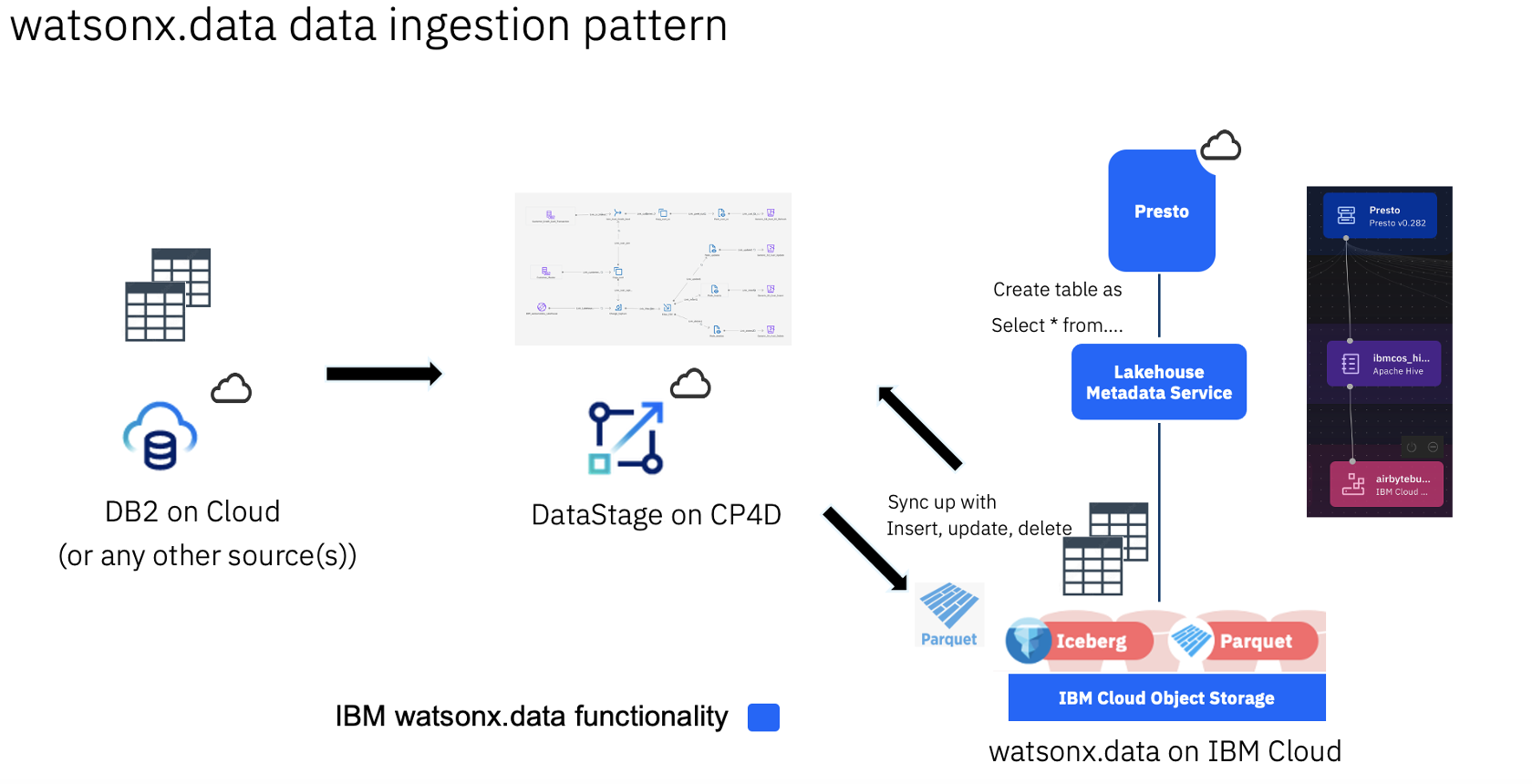
Key advantages of the ingestion pattern
The key advantages are:
Support for hybrid multicloud: The IBM Cloud Pak for Data architecture provides for a cloud-ready data integration architecture. It allows flexible deployment options for you to choose between public, private, and hybrid cloud, including on-premises options. Organizations can quickly set up integration pipelines, including complex data transformation during data ingestion.
Rich set of connectors: DataStage has a rich set of connectors to sources that exist in an enterprise. Data source connectors provide data connectivity and metadata integration to external data sources, such as relational and non-relational databases, cloud storage services, or messaging software. It provides connectivity to ERP and CRM systems like SAP and Salesforce that have their own proprietary interfaces. It also has file connectors for working with files, including complex mainframe files.
Large volumes of data migration: DataStage is used for migrating large data volumes given its powerful parallel processing engine, data partitioning, and scalability while handling big data. Because watsonx.data is a lakehouse solution that handles petabytes of data, this ingestion pattern leverages the scalability that is provided by the Red Hat OpenShift cluster. With auto-scaling enabled, additional compute pods are spun based on the custom resource definition. IBM Cloud Pak for Data provides for a cloud-ready data integration architecture. It offers flexible deployment options to choose between public, private, and hybrid clouds, including on-premises options to move data in a short time frame.
Query pushdown capability: There is an option to push the query processing to the source system. This speeds up the processing time because joins and transformations can be done at the source, and only the final results are sent back. This avoids a lot of data that needs to flow over the network, greatly improving the performance and reducing the need to create a full dump of source data in the form of staging tables, which reduces cloud egress costs. Most of the other tools, especially the open source ETL software, don’t have this DataStage feature.
Data lineage and data observability: Using this stack, enterprise-grade implementations can also use IBM MANTA and IBM Databand to efficiently meet regulatory and compliance requirements as well as improve operational efficiency across data pipelines. Watsonx.data is integrated with IBM Knowledge Catalog for augmented data quality solutions.
Configuring DataStage on Cloud Pak for Data
The use case shown in the following DataStage flow illustrates some data transformations that can be done before loading the data into watsonx.data. For enterprise-grade data pipelines, there is also a need to ensure that the source data sources and the target lakehouse datastores in watsonx.data are always in sync as data sources continue getting data. This ensures that the sync process is efficient without the need to do a full refresh of source data.
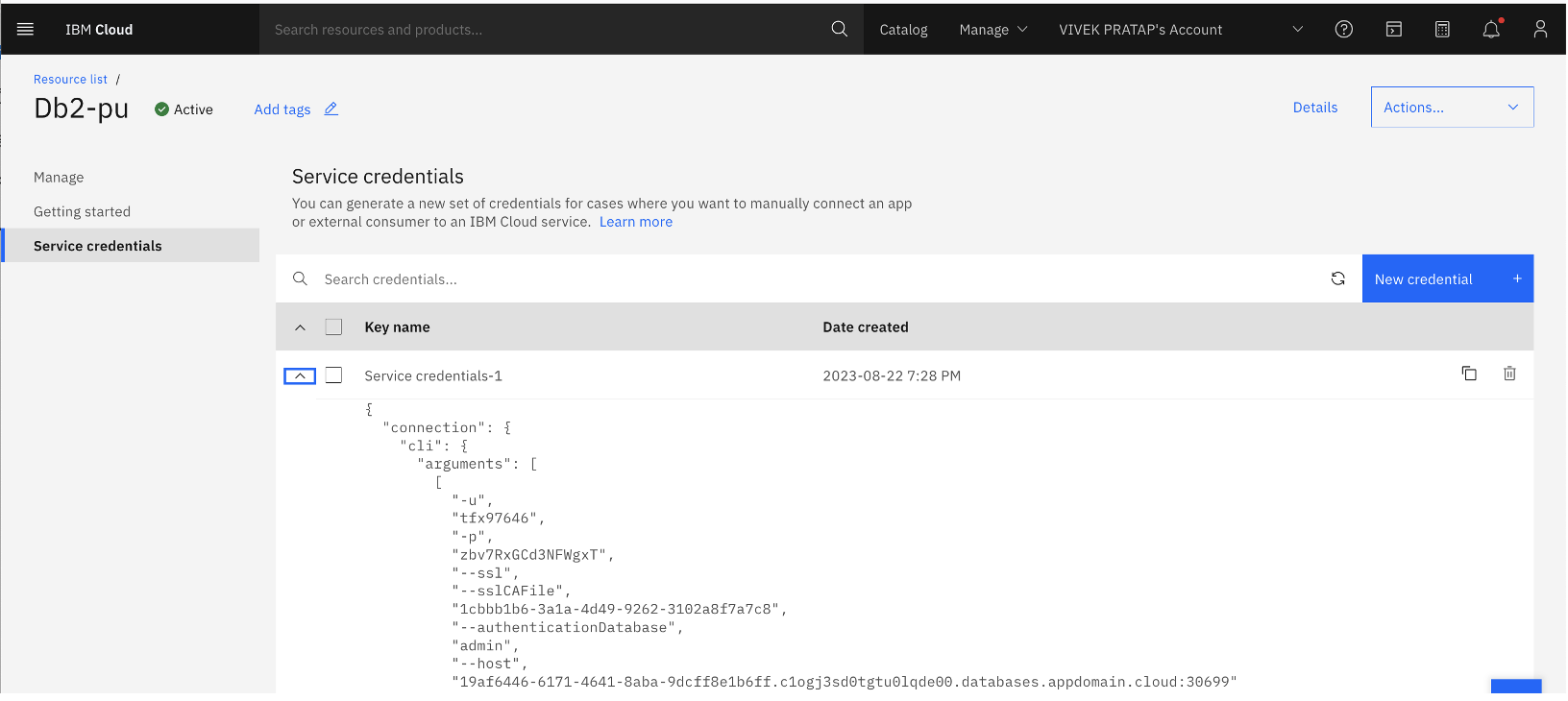
You can get the Service credentials from the IBM Cloud Resource list by expanding the Service credentials, as shown in the following image.
The following image shows the DataStage job details for ingesting data into watsonx.data.
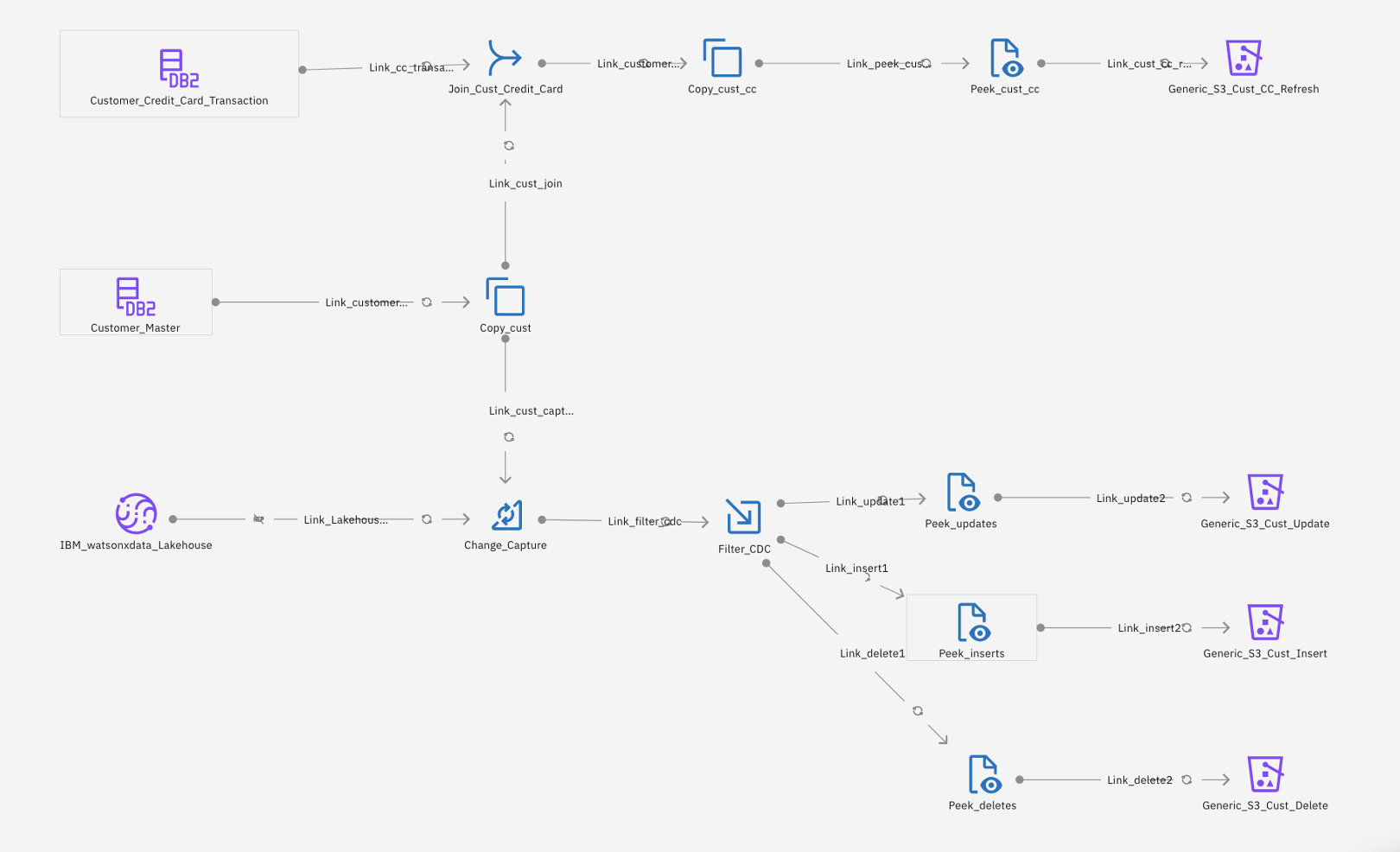
The DataStage job flow shown previously covers two key functions:
It shows some of the data transformations that are required while moving data from the data source to watsonx.data. Data transformation needs can vary depending on the requirements. The output data set can be made ready for future processing by writing into an IBM Cloud Object Storage bucket.
The job flow does a change delta capture so that instead of doing a full refresh, only the delta insert, update, or delete records are passed to watsonx.data.
The flow job shown in the following image joins two Db2 on Cloud tables (the Customer_Credit_Card_transaction table and the Customer_Master table), and drops the Customer_Name fields in the copy stage. Data gets loaded into the IBM Cloud Object Storage bucket on IBM Cloud and is a full data refresh of the data.
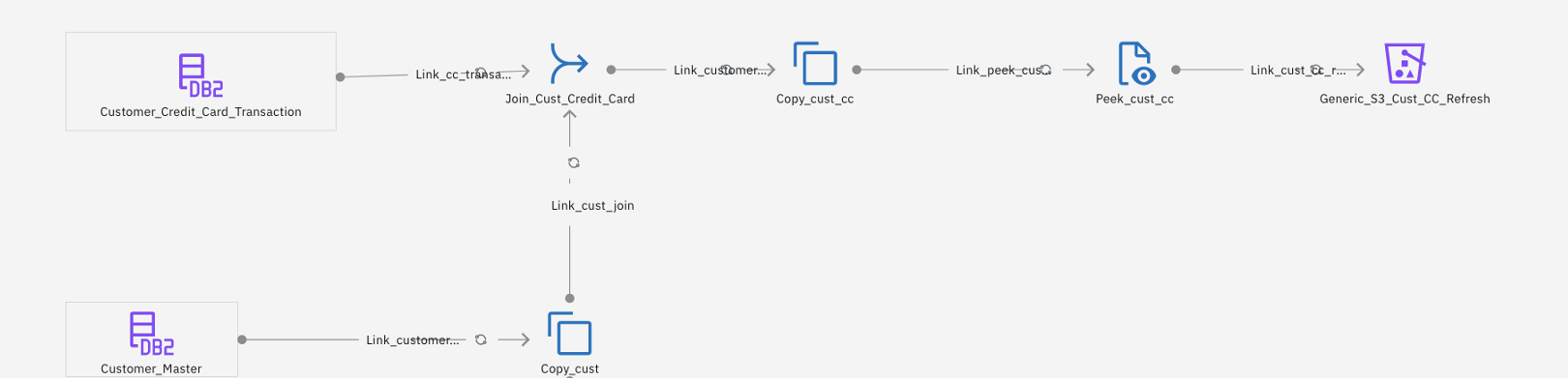
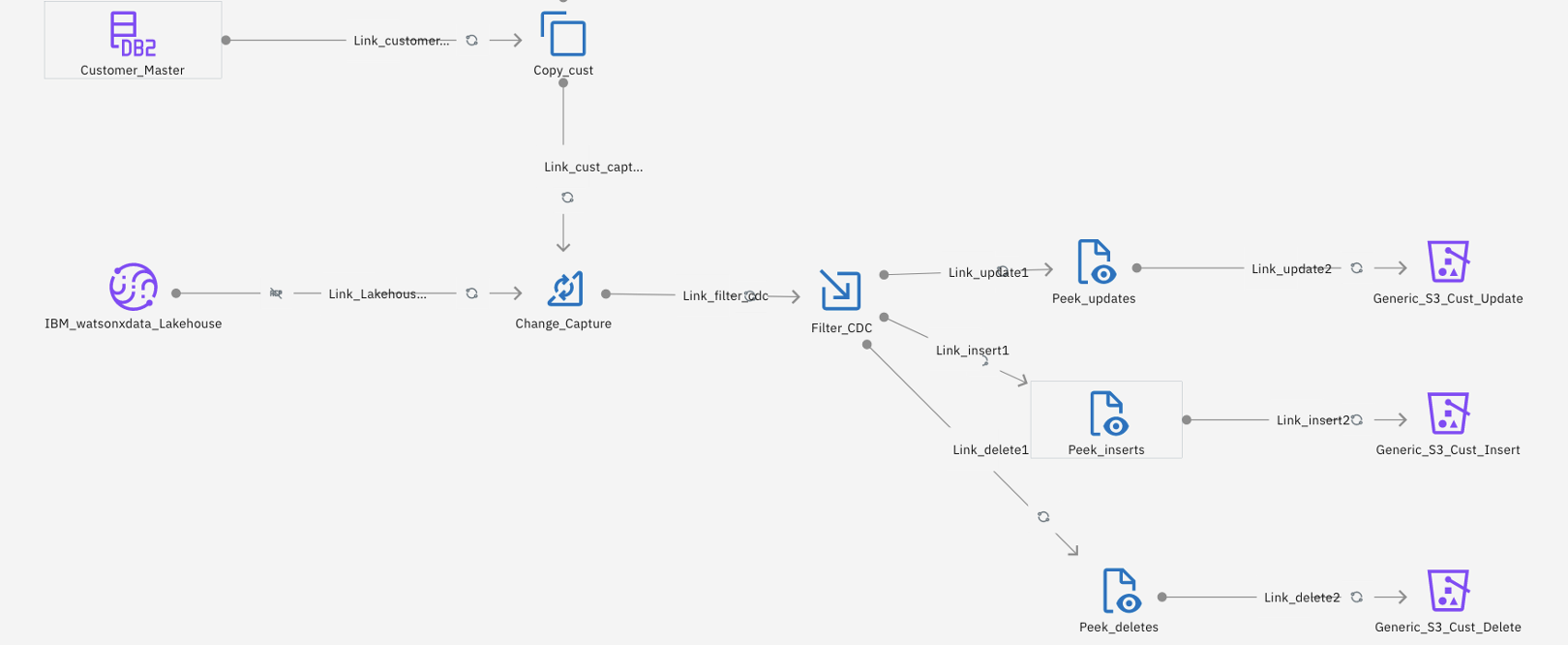
The lower part of the flow job, as shown in the following image, is for doing a change data capture between the target Customer_Master table in Apache Iceberg that already exists on watsonx.data from the previous runs and the source Db2 table. The target table must be in sync with the source table. Instead of doing a full refresh, the change capture stage in DataStage identifies only the change delta comprised of inserts, updates, and deletes after comparing the source and target tables.
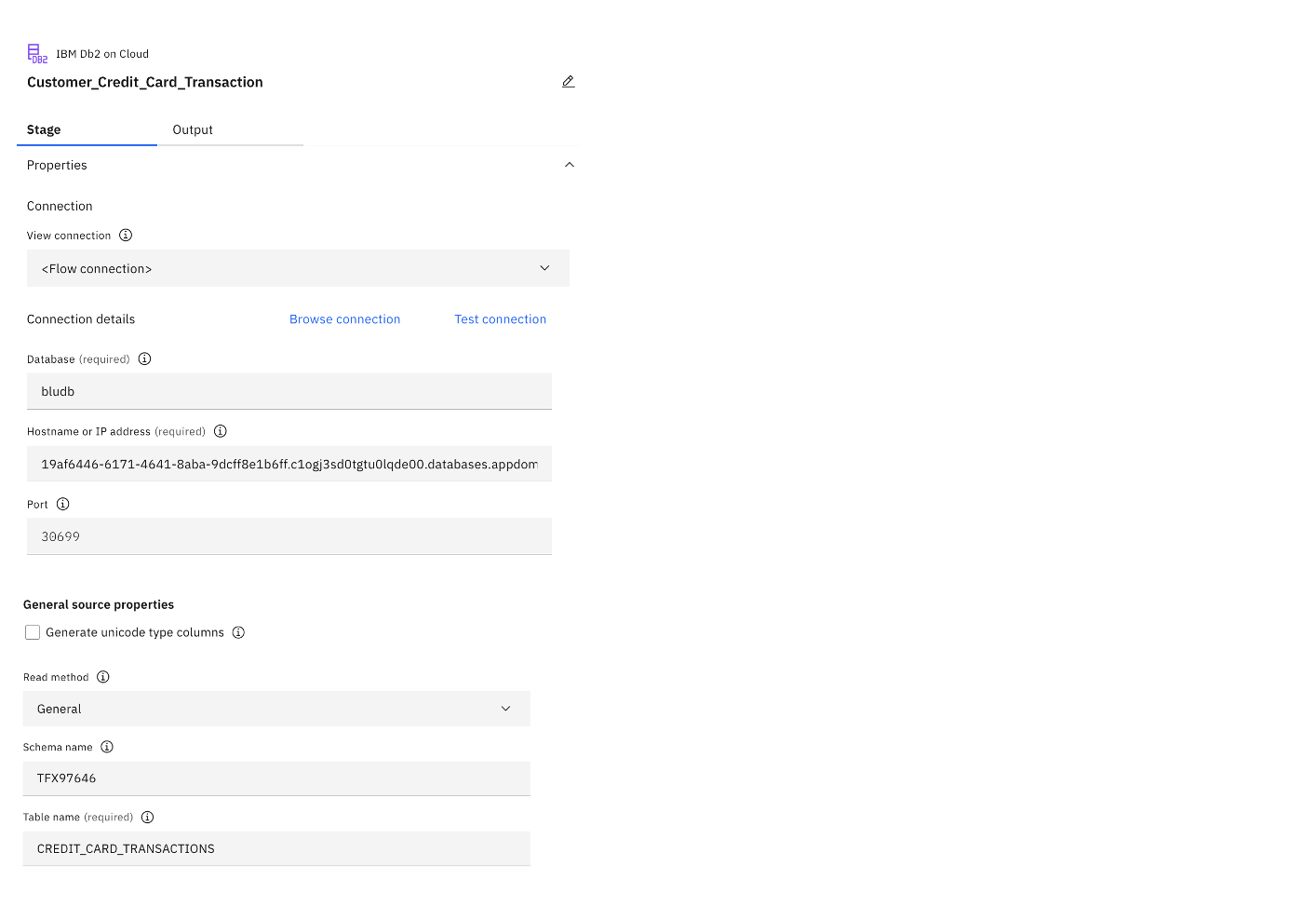
Some of the key settings for the IBM Db2 Connector stage are specified in the following image. These credentials can be picked up from the Service credentials page for Db2 on Cloud that was shown previously.
The following image shows IBM watsonx.data connector connections.
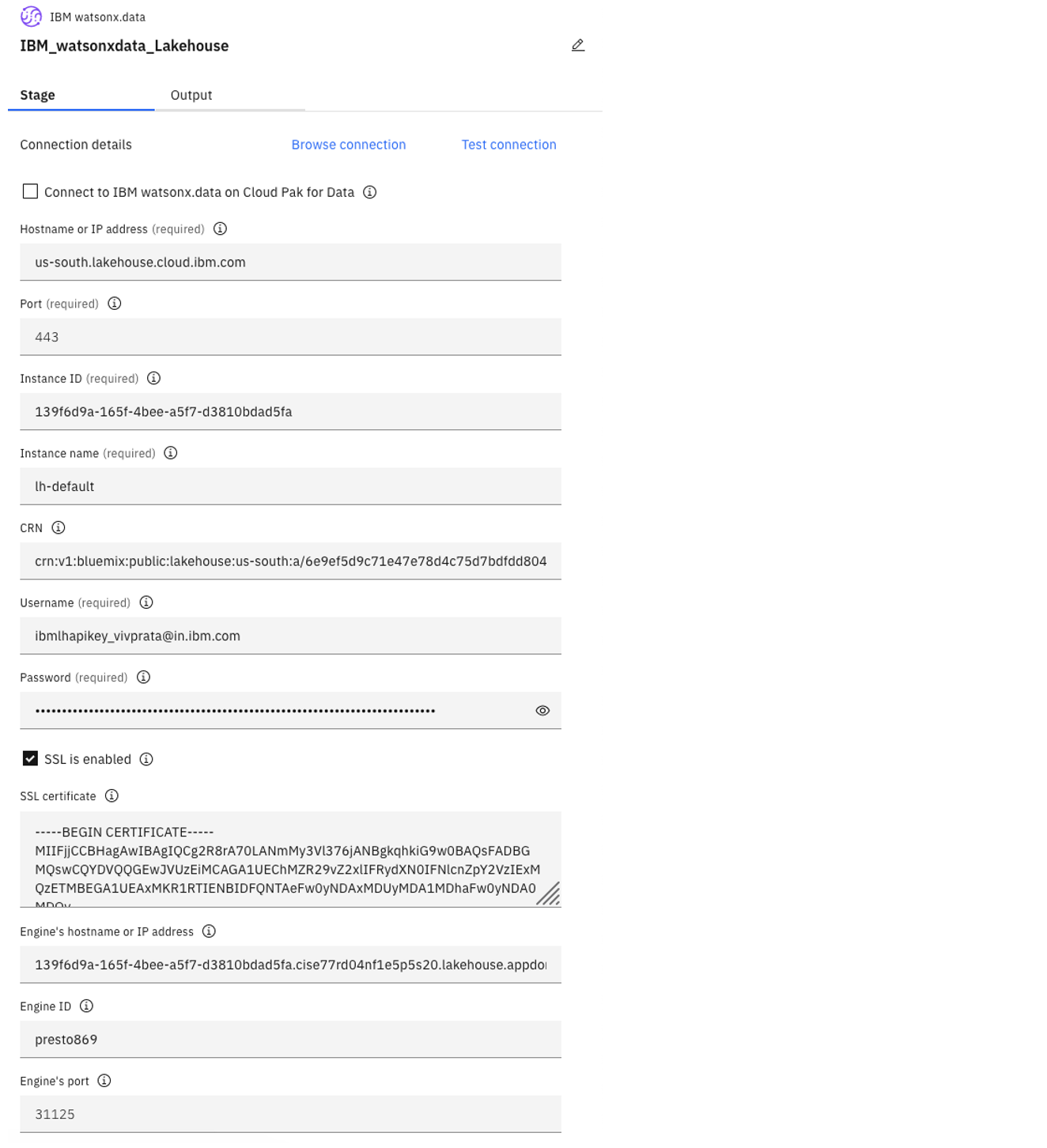
For these connections, you need:
Hostname or IP address: You can find this information from the URL of the watsonx.data web console:
https://<hostname-or-IPaddress>/watsonx-data/#/home?instanceId=<instance-id>. For example,us-south.lakehouse.cloud.ibm.com.Port: The default port number is 443. If the connection has a different port, you can find this number in the URL of the watsonx.data web console.
Instance ID: You can find this value in the watsonx.data console navigation menu. Click the Instance details link, as shown at the bottom of the following image.
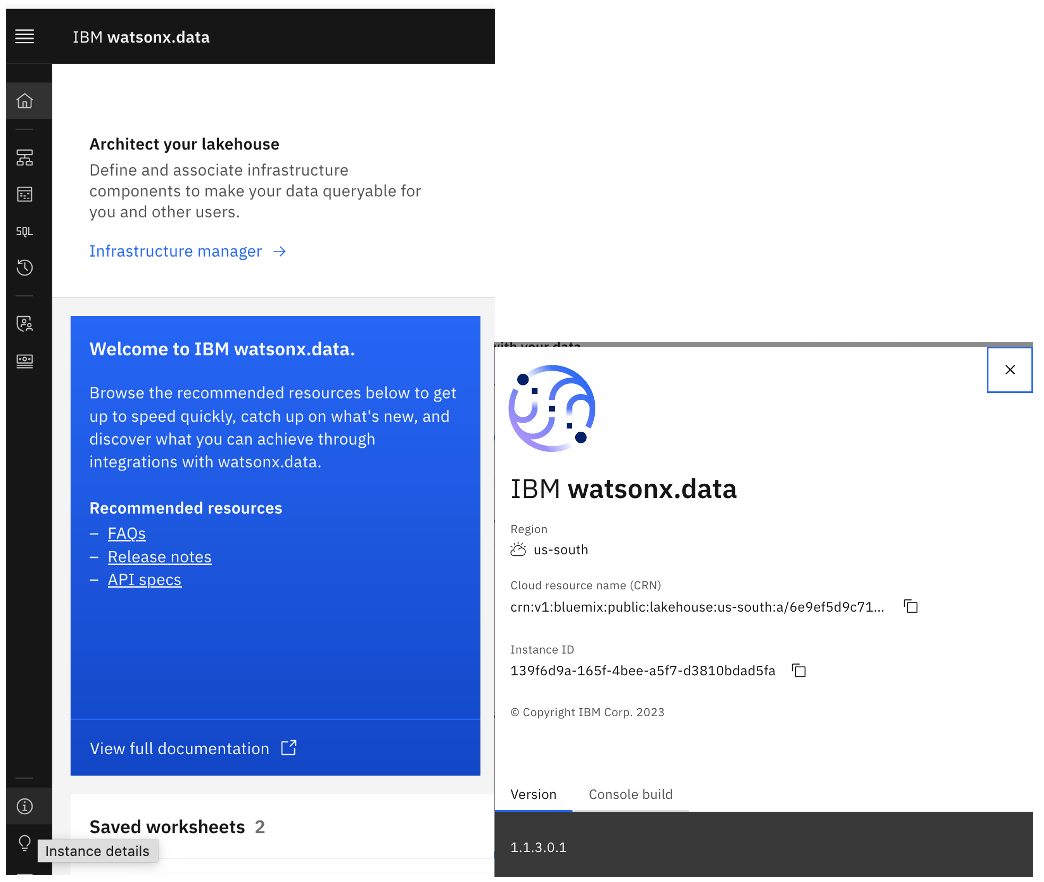
Instance name: For SaaS on IBM Cloud or stand-alone watsonx.data, the default value is lh-default.
CRN (Cloud resource name): This field is needed only for connections to IBM Cloud. You can find this information in the IBM Cloud resource list for the watsonx.data service. It’s also found along with the Instance ID, as shown previously. For example,
crn:v1:bluemix:public:lakehouse:us-south:a/6e9ef5d9c71e47e78d4c75d7bdfdd804:139f6d9a-165f-4bee-a5f7-d2880bdad5fa::.Credentials: For watsonx.data that is deployed on IBM Cloud, the default username is
ibmlhapikey_<cloud-account-email-address>. For example,ibmlhapikey_username@example.com. The password is the user's API key.Credentials: SSL in parallel external memory (PEM) is enabled by default and is recommended for additional security. The certificate can be downloaded from the browser by Credentials going to the certificate section of the respective browser and downloading the
*.cerfile. You would copy and paste the contents to the SSL certificate. The following image shows an example.
Engine's hostname or IP address: This information is found by opening the Infrastructure manager and going to the Details page. Under Engine details, the hostname or IP address is the value in the Host field before the colon (:). For example,
139f6d9a-165f-4bee-a5f7-d3810bdad5fa.cise77rd04nf1e5p5s20.lakehouse.appdomain.cloud:31125.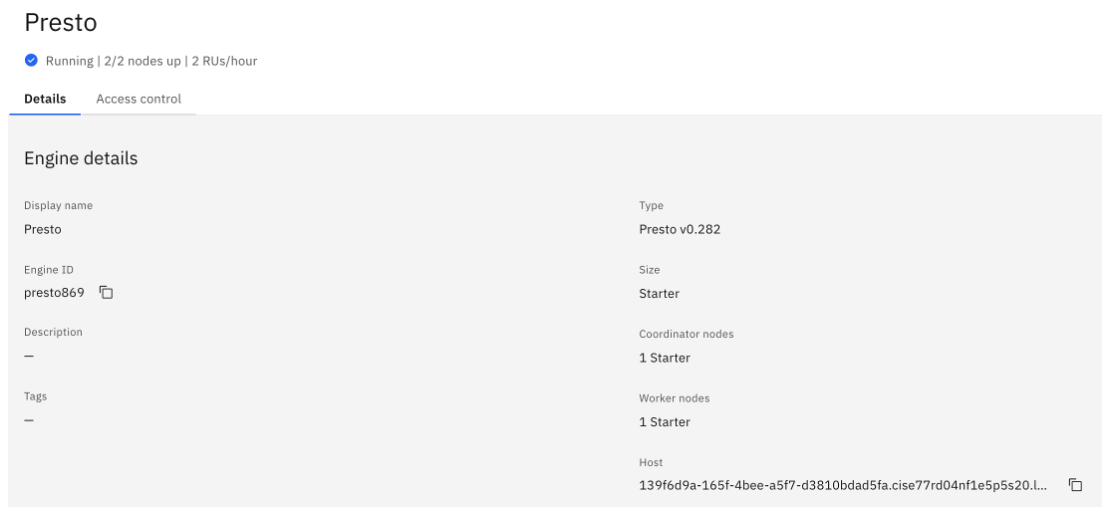
Engine ID: In this example, the Engine ID is the same as the one mentioned previously, presto869.
Engine port: Under the Engine details (shown previously), the port number is the value in the Host field after the colon (:). In the following example, it is 31125.
Host : 139f6d9a-165f-4bee-a5f7-d3810bdad5fa.cise77rd04nf1e5p5s20.lh.appdomain.cloud:31125
The following image shows the DataStage change data capture stage configuration. It shows the key settings that would go into the Change Capture Stage on the Stage tab.
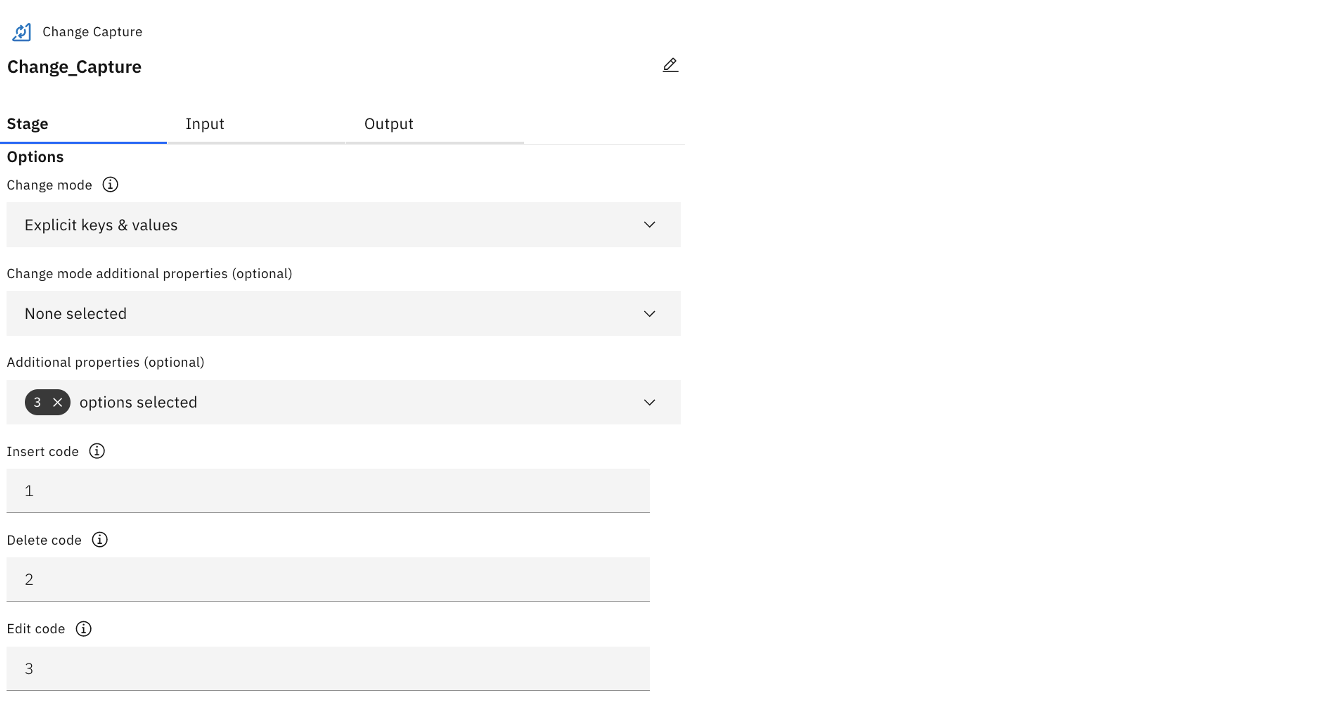
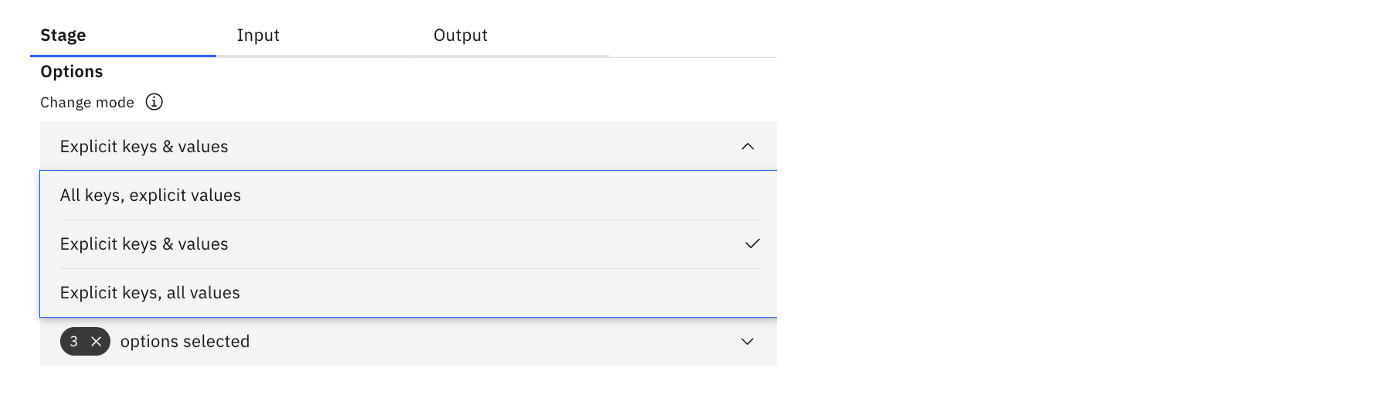
As shown in the following image, for Change mode, select Explicit keys & values.
Similarly, the following image shows three options selected.
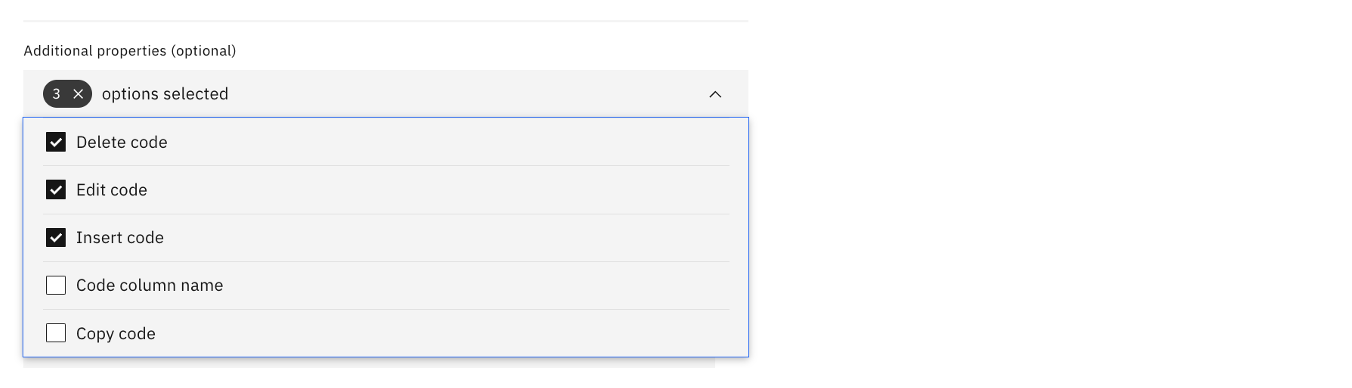
The key choice depends on whether there is a single primary key, for example, Customer ID in this case. In an example of where the unique record is determined by a large composite key or number of fields, other options can be chosen. It also depends on the number of fields that need to be compared. Edit deltas are the most compute-intensive processing, especially when data volumes are high and there is a large number of fields for comparison. It can be avoided if not required.
The Change mode determines how keys and values are specified. For example:
- Explicit keys & values means that the keys and values must be explicitly defined.
- All keys, explicit values means that the value columns must be defined, but all other columns are key columns unless they are excluded.
- Explicit keys, all values means that the key columns must be defined, but all other columns are value columns unless they are excluded.
The insert, delete, and edit rows are marked as 1, 2 and 3, respectively, for identification and processing. The Filter stage is used to split the three types of records and send them to the respective buckets for insert, delete, or edit in a parquet format that can be read by watsonx.data.
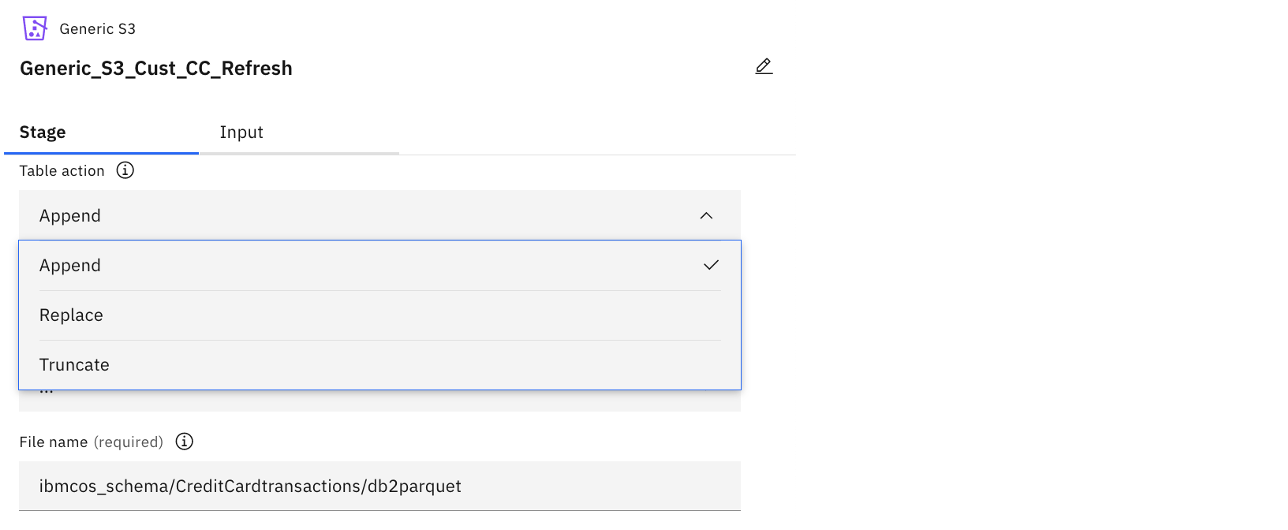
DataStage offers different modes to load to provide flexibility depending on the load methodology, as shown in the following image.
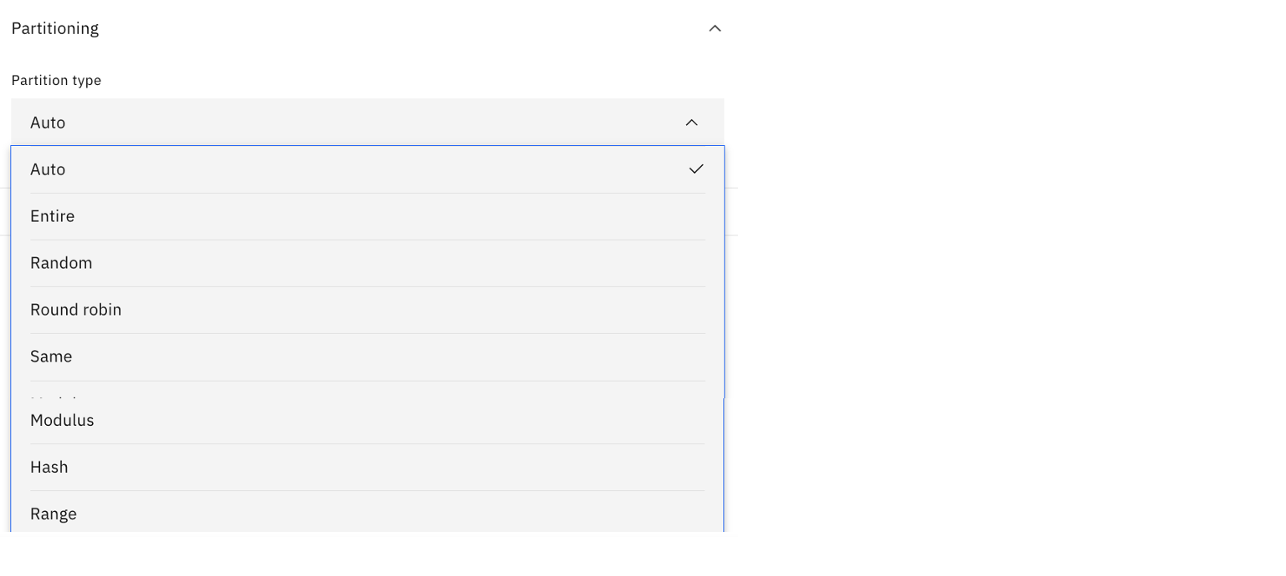
The data can also be partitioned to speed up the processing. Data partitioning is an approach to parallelism that involves breaking the record set into partitions, or subsets of records. The aim of most partitioning operations is to end up with a set of partitions that are as near equal size as possible, ensuring an even load across your processors while handling big data workloads. DataStage automatically partitions data based on the type of partition that the stage requires. The following image shows the various options.
Parquet files processing in IBM Cloud Object Storage
DataStage connects the different sources, extracts and performs the transformations, and creates a parquet file that can be written to any S3-compatible object storage. In this case, the files arrive on IBM Cloud Object Storage, as shown in the following image.
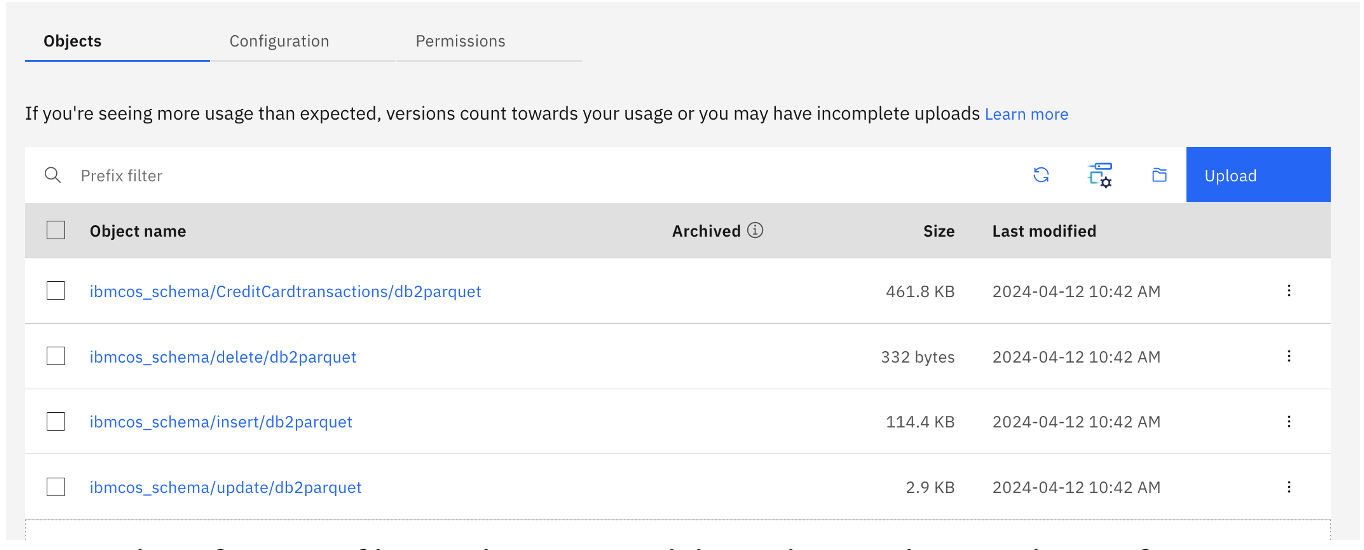
Any number of parquet files can be generated depending on the complexity of processing. The following image shows a sample parquet file.
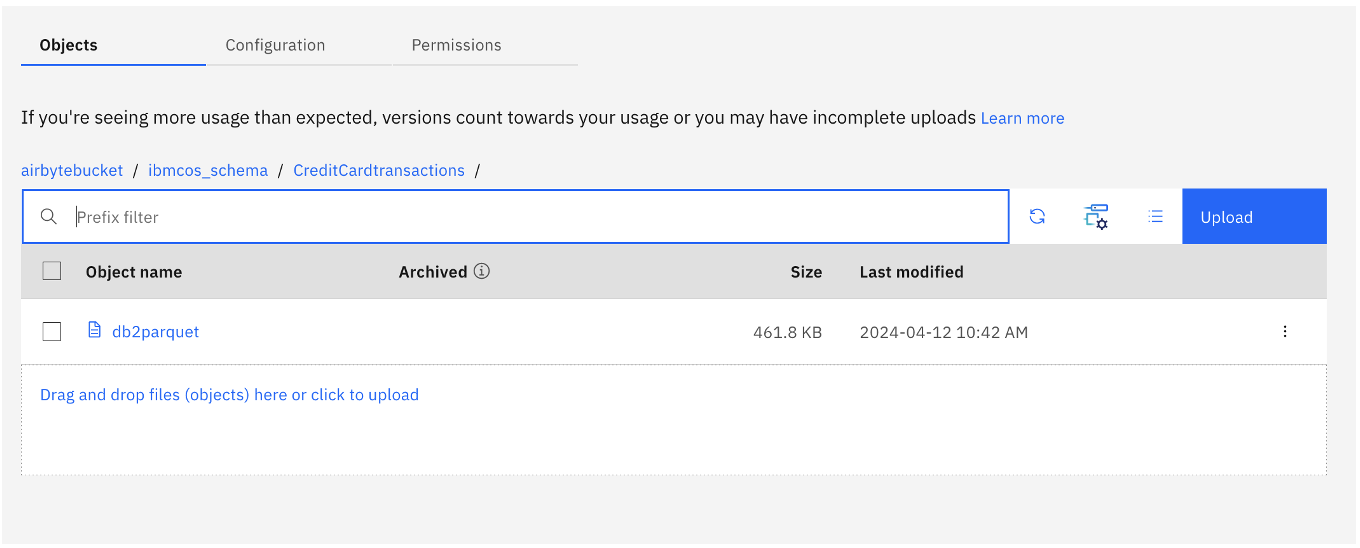
Parquet files ingestion into watsonx.data
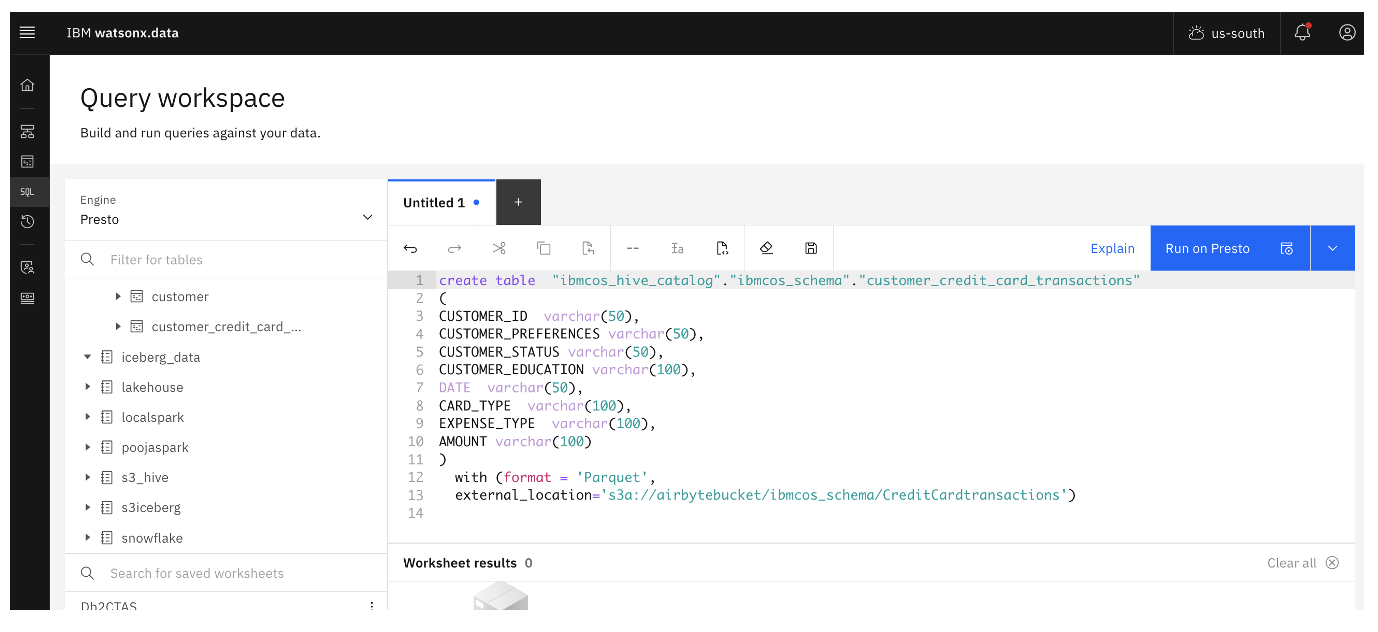
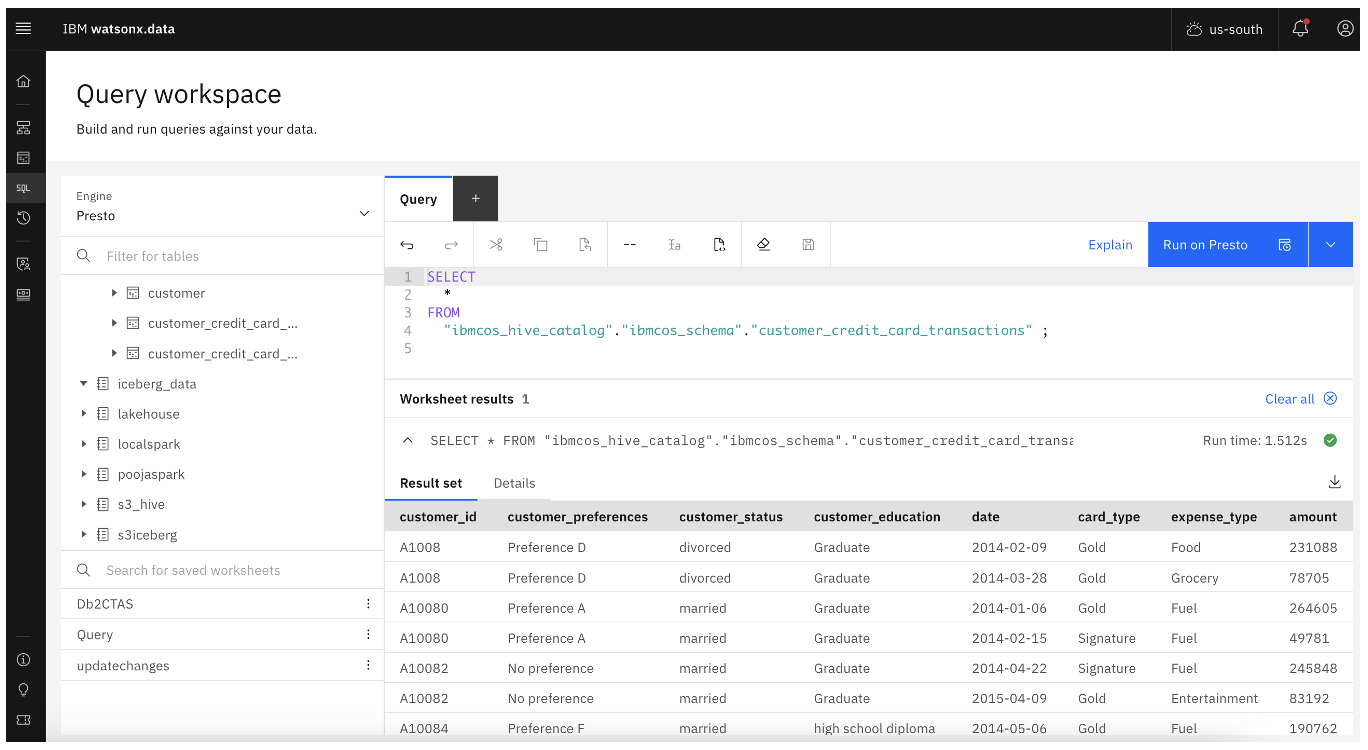
This last stage is where the parquet file on an S3-compatible storage is ingested into watsonx.data. Data can be ingested using the Query workspace in watsonx.data or the CLI. The following images show the Query workspace.
Conclusion
This article explained the key features, best practices, and benefits of ingesting data from IBM Db2 on Cloud into watsonx.data with DataStage on IBM Cloud Pak for Data and IBM Cloud Object Storage. You can extend this concept further to meet real-world enterprise implementations where large data volumes need data to be transformed and moved to the lakehouse for processing and require good performance and acceptable SLAs for production-grade workloads. The features and key technical configurations have been elaborated so that any experienced architect or developer can implement a similar design pattern.
Learn more about watsonx.data. You can also start your free watsonx.data trial.