About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Data privacy using watsonx.data with IBM Knowledge Catalog
Integrate on-premises watsonx.data with the IBM Knowledge Catalog, a crucial step that lets you test data protection rules and governance policies on your own
On this page
IBM Cloud Pak for Data provides a data fabric solution for faster, trusted AI outcomes by connecting the right data, at the right time, to the right people, from anywhere it’s needed.
It's a single, unified platform that spans hybrid and multicloud environments to ingest, explore, prepare, manage, govern, and serve petabyte-scale data for business-ready AI.
IBM watsonx.data is an open, hybrid, and governed data store that enables you to scale analytics and AI with all of your data, wherever it resides, through:
- Open formats to access all of your data through a single point of entry and share a single copy of data across your organization and workloads, without needing to migrate or re-catalog, reducing the extract, transform, and load (ETL) process and data duplication
- Integrated vectorized embedding capabilities to prepare your data for retrieval-augmented generation (RAG) or other machine learning and generative AI use cases (in tech preview)
- Generative AI-powered conversational interfaces to easily find, augment, and visualize data and unlock new data insights, with no SQL required (in tech preview)
- Integration with existing databases, tools, and modern data stacks
- Hybrid deployment options as fully managed SaaS on IBM Cloud and Amazon Web Services (AWS) or self-managed containerized software on premises
IBM Knowledge Catalog is a data governance software that provides a data catalog to automate data discovery, data quality management, data lineage, and data protection. The cloud-based enterprise metadata repository activates information for AI, machine learning, and deep learning supported by active metadata. Access, curate, categorize, and share data, knowledge assets, and their relationships wherever they reside. You can use IBM Knowledge Catalog for IBM Cloud Pak for Data to deliver business-ready data to feed AI and analytics projects.
This tutorial explains how you can integrate on-premises IBM Cloud Pak for Data with on-premises IBM watsonx.data to demonstrate data protection and data governance on personal identification information (PII).
Prerequisites
To follow this tutorial, you need:
- An on-premises instance of IBM watsonx.data.
- An on-premises instance of IBM Cloud Pak for Data.
- An on-premises instance of IBM Knowledge Catalog.
- A catalog with an IBM Cloud Object Storage bucket.
- Any object storage like IBM Cloud Object Storage or AWS S3 Object Storage. This tutorial uses an AWS S3 bucket.
- An IBM Knowledge Catalog admin Zen API key.
Estimated time
It should take you approximately 60 minutes to complete this tutorial.
Solution architecture
The following image shows an example of the solution architecture.

Steps
Step 1. Create catalog, business terms, categories, and rules
To begin:
Log in to IBM Cloud Pak for Data homepage with the
admin_id/xxxxcredentials.
Navigate to Catalogs > All catalogs while remaining in the admin role.
Click Create Catalog.
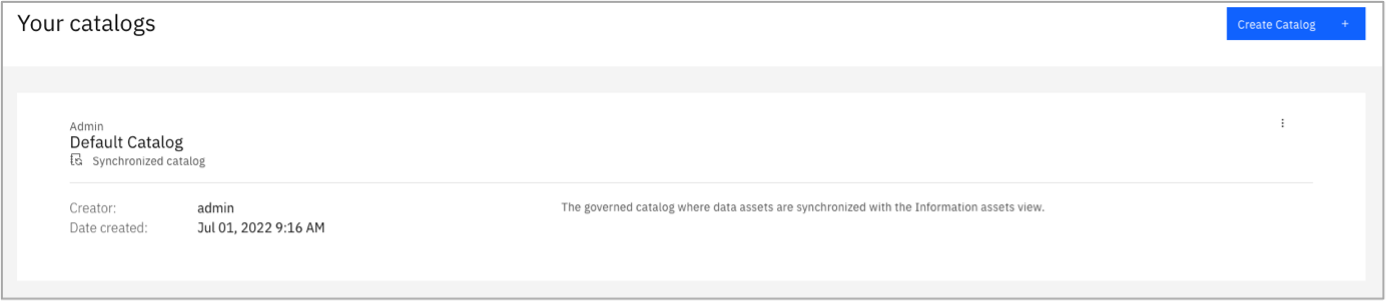
Enter a name for your catalog (for example, IKC – WXD Integration).
- Select Enforce data protection and data location rules.
Select Update original assets.
After the catalog is created, proceed to the next steps. You will reference the same catalog when publishing the data assets.
For the business glossary for the financial domain, you use the IBM Knowledge Accelerator for Financial Services, which is a comprehensive resource that encompasses a rich array of terms and concepts. It provides a nuanced understanding of the intricate nature of the business information tha tis handled by financial institutions in their daily operations. You can create additional categories when required based on your data platform
Navigate to Governance > Categories.
You can view the populated business glossary for all of the required categories.

Navigate to Governance > Business terms.
Navigate to Governance > Classifications
Navigate to Governance > Rules.
Step 2. Connect and import the table metadata from the lakehouse to IBM Knowledge Catalog
Log in to IBM Cloud Pak for Data using the admin user name and password.

Click Catalogs > All catalogs in the left pane.
The screen lists the available catalogs.
Click New catalog in the upper right to create a new catalog.
Enter a catalog name, a catalog description, and select Enforce data protection rules in the New Catalog creation screen. Then, click Create.
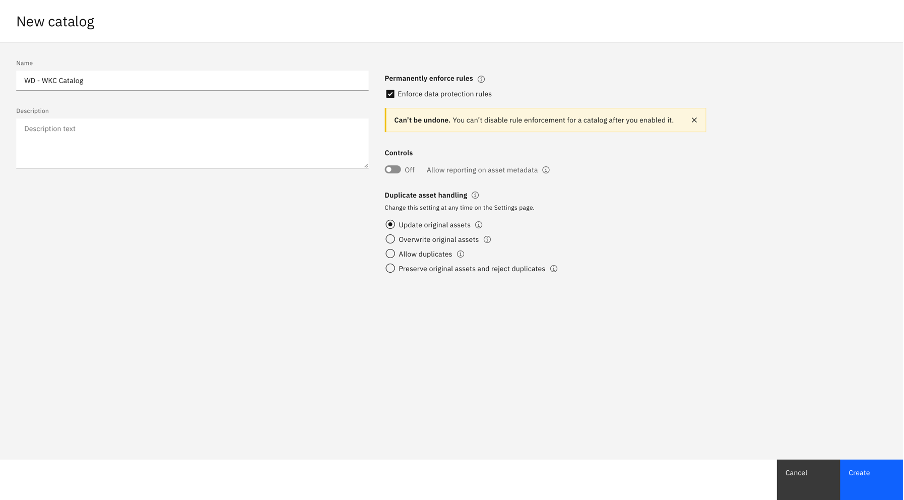
The catalog is created, and you are taken to the catalog page.
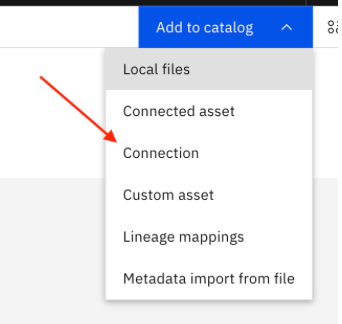
Add a new Presto connection to the catalog by clicking Add to catalog, then selecting Connection.
Search for and select the watsonx.data connection type from the options.
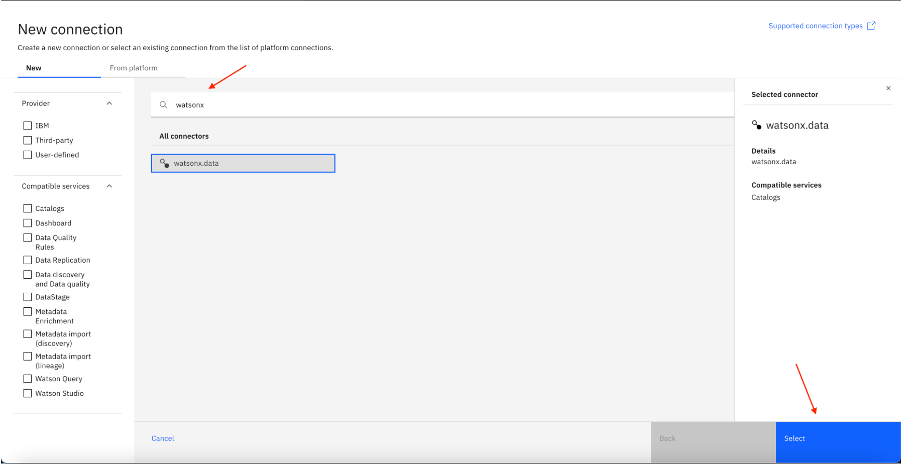
Enter the required details for the Presto connection (shown in Step 3), then test the connection.
Step 3. Get the connection parameters for the IBM Knowledge Catalog watsonx.data connector
This section describes how to get the connection parameters for the IBM Knowledge Catalog watsonx.data connector to connect to an on-premises lakehouse instance. You'll enter the following parameters:
- Hostname: URL of IBM Cloud Pak for Data
- Port number: 443
- instance_id: You can take the instance ID for the on-premises watsonx.data lakehouse console
- instance_name: lakehouse
- CRN: Same values as the instance ID for the on-premises
- Check connect to watsonx cpd checkbox
- Username: Lakehouse user name
- Password: Password
- Uncheck validate SSL cert checkbox
- Check engine is SSL enabled checkbox
- Engine hostname: Get the value from the lh-console UI
- Engine id: Get the value from the lh-console UI
- Engine Port: 443
Get the hostname from the on-premises lakehouse URL.
Use 443 for the port number.
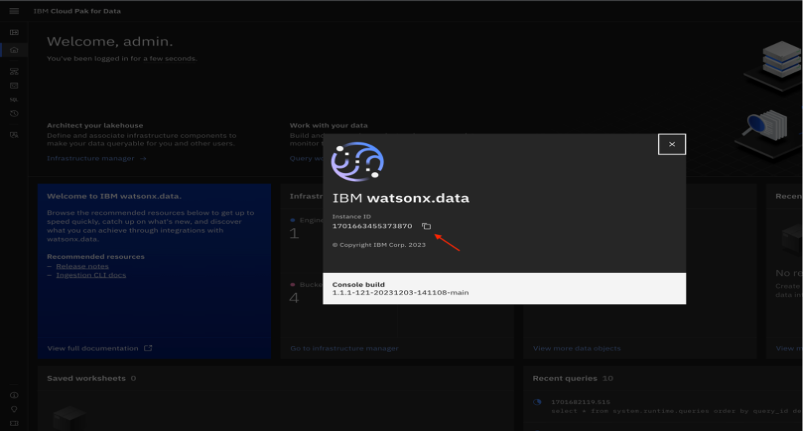
Get the Instance ID from the on-premises lakehouse URL. Click the Instance ID icon.
Copy the Instance ID.
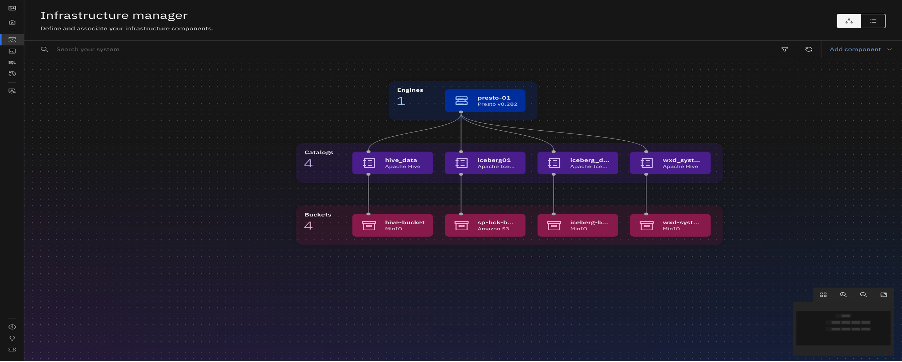
Get engine details.
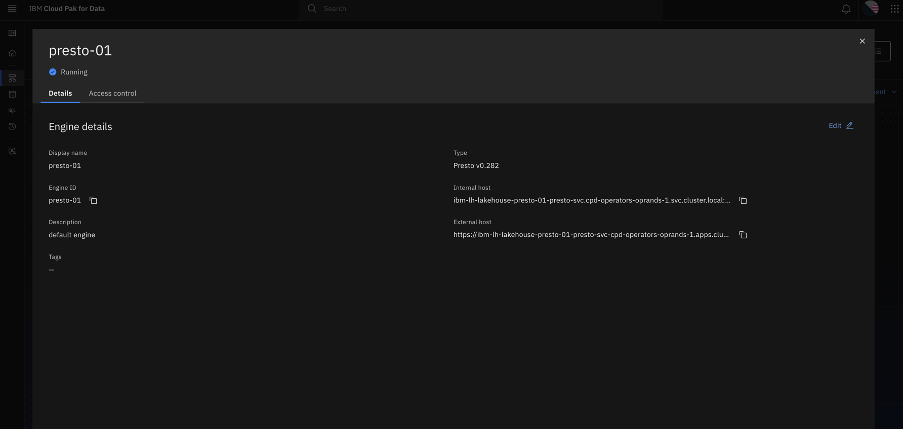
Get engine ID and URL.
Download the certificate from the lakehouse console using a web browser, and enter it in the Engine SSL Certificate field.
Return to the Catalog, and create connection with all the details that were gathered in previous steps
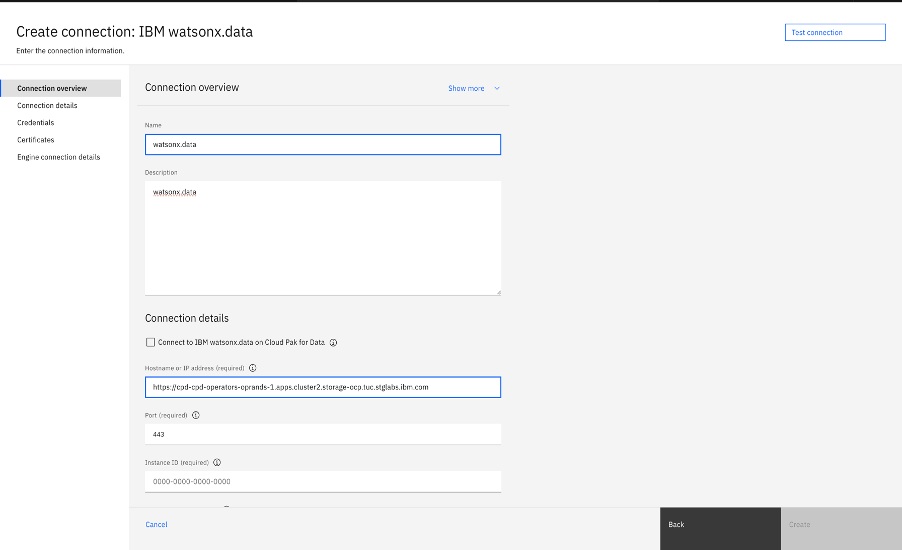
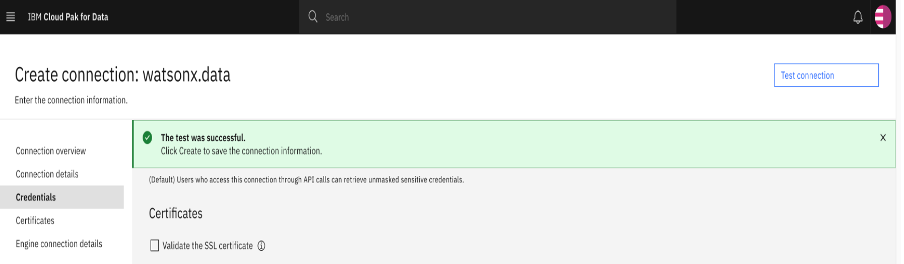
Test the connection by using Test Connection button, and clicking Create in the lower-right corner.
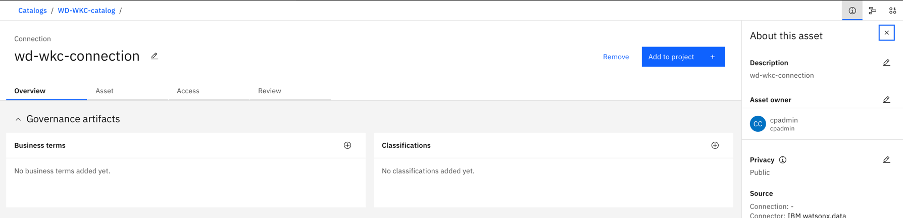
The connection is successfully added to the Catalog. For simplicity. it's renamed connection to wd-wKC-connection.
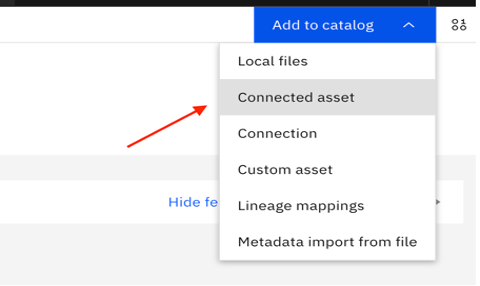
Click Add to Catalog in the upper right, and select Connected asset.
In the connected asset, click Select source.
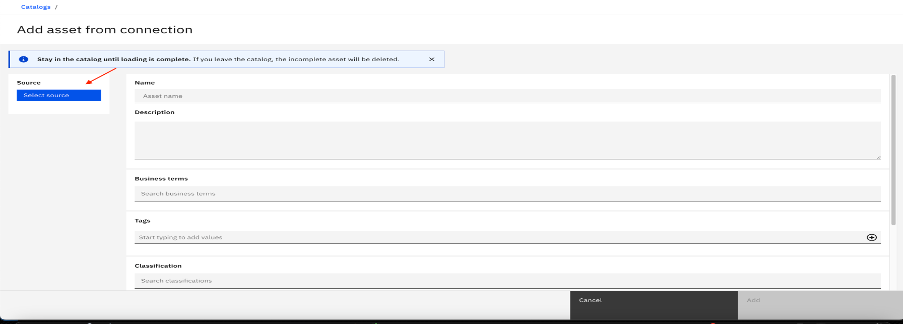
Navigate to the table that you want to import in the flow Catalog --> schema --> table. Select the table, and click Add.
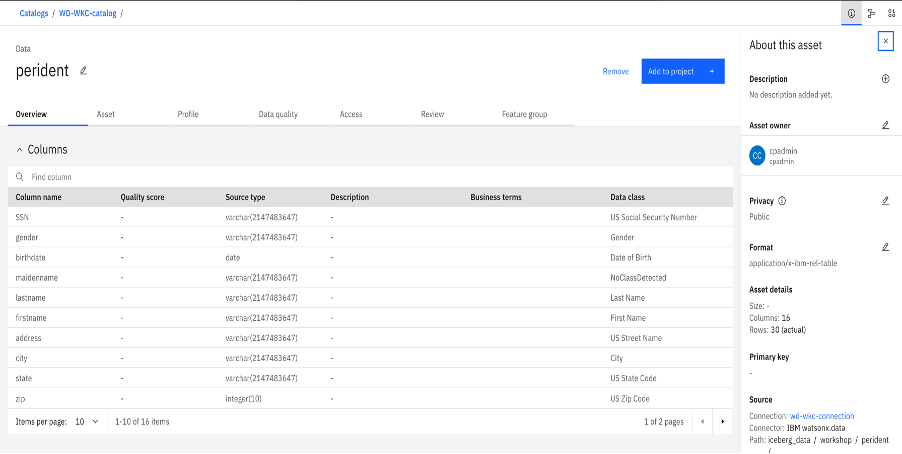
On the asset page, verify the Data Class against each column assigned during the metadata import. Note that you can define rules in IBM Knowledge Catalog based on these data classes.
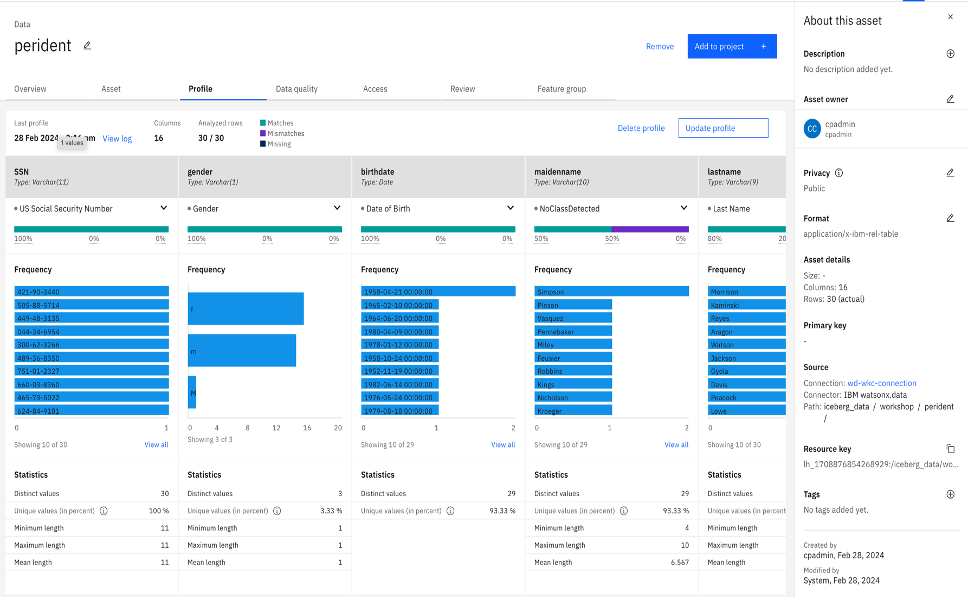
Click the profile tab, and you can change any Data Class as per the requirement. Note that changing the data class is not mandatory. Do it only if the Data Class populated is wrong or needs to be changed.
Step 4. Create a new user in IBM Knowledge Catalog and assign the user as the owner of the asset or table
For data that's available in an asset or table in which the data protection or data governance rules are defined or applied, the Unmasked data is available for the owner alone. The data is masked for rest of the users. You can create a user in IBM Knowledge Catalog and assign the ownership of the asset to that user by using the following steps.
Open the IBM Cloud Pak for Data URL.
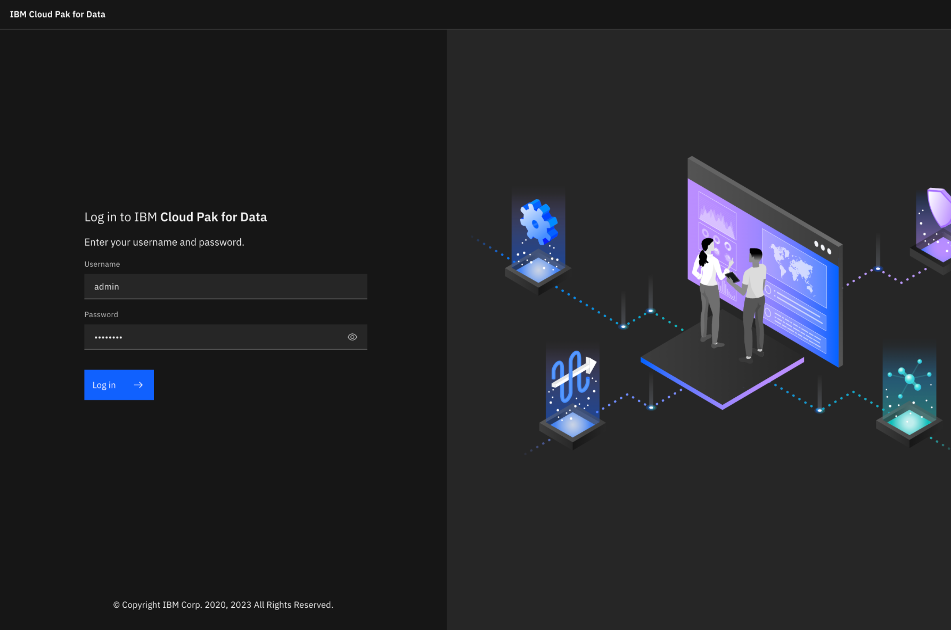
From the homepage, click the Access control option under Administration in the left menu.
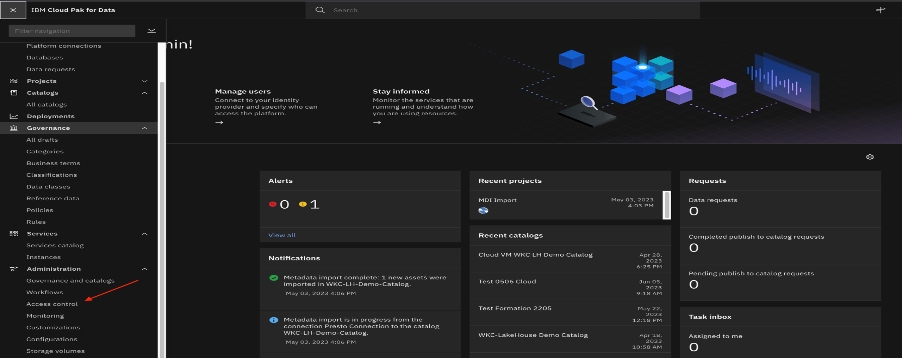
Add the user and provide all the details.
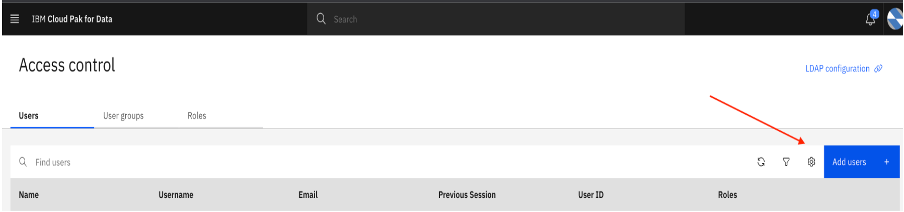
Add the user in in the Catalog.
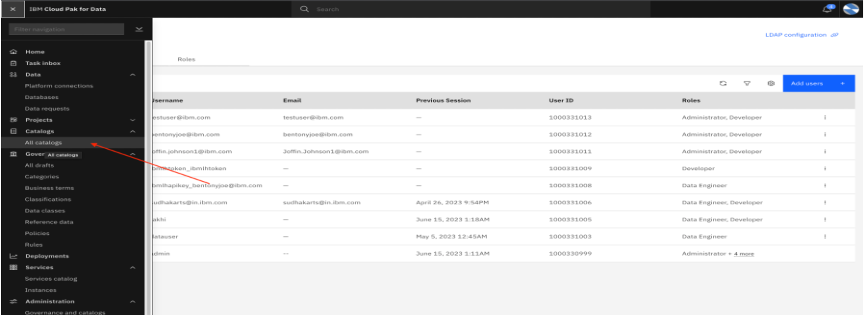
Go to the Catalog, and select Add user.

Step 5. Configure IBM Knowledge Catalog in watsonx.data UI
Log in to IBM Cloud Pak for Data by using the admin user name and password.
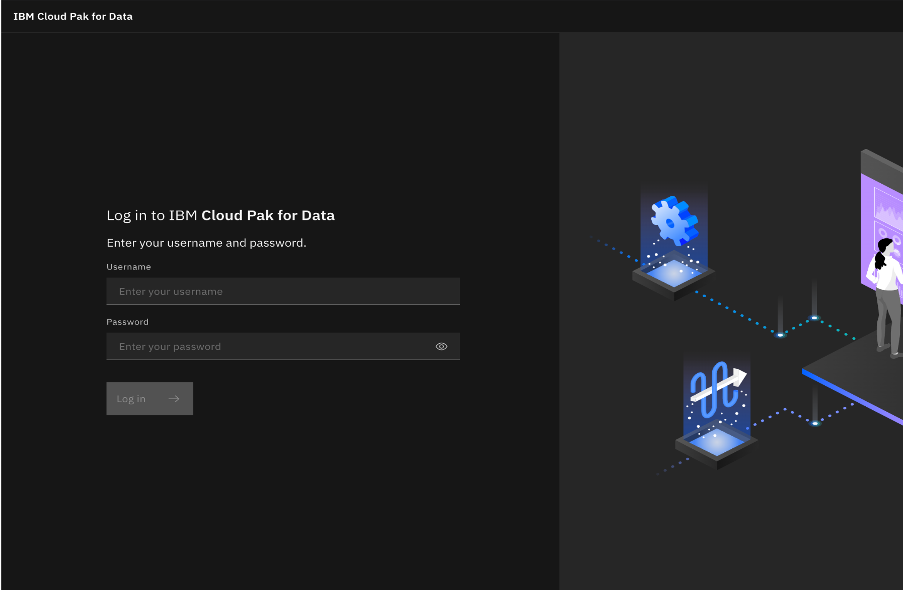
From the service instances, open the instance for the lakehouse.
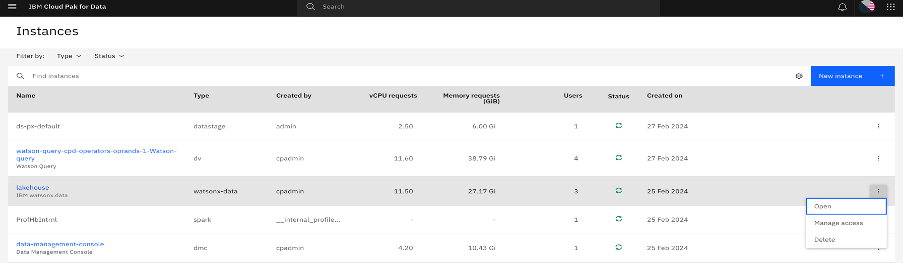
Open the lakehouse console UI, and select Access control in the left pane.
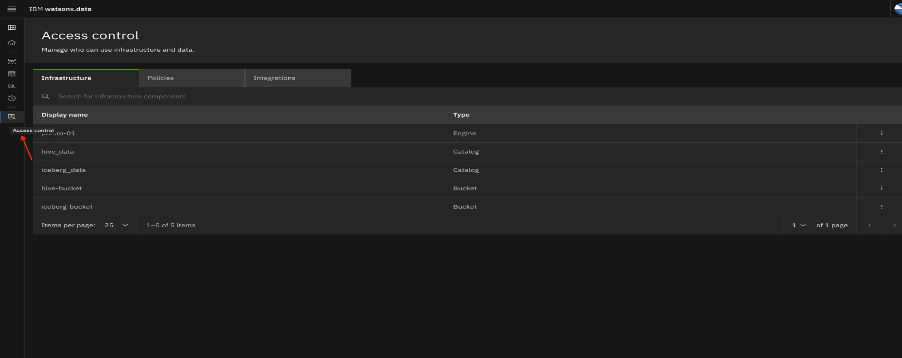
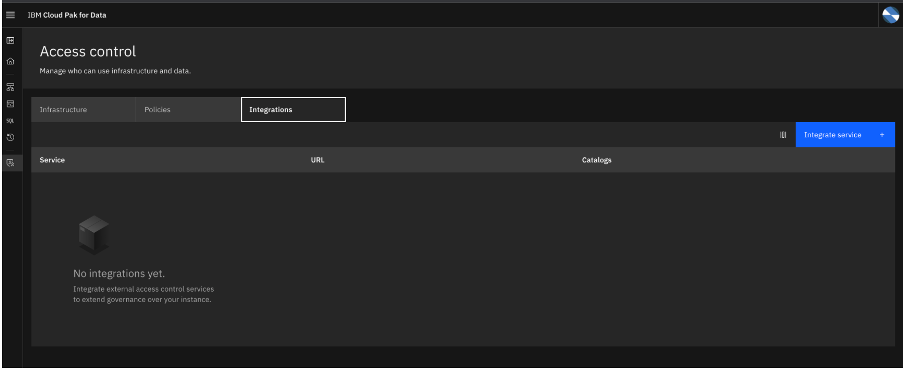
Click the Integration tab, then click Integrate service.
Create a Zen API Key.
The Integration screen opens.
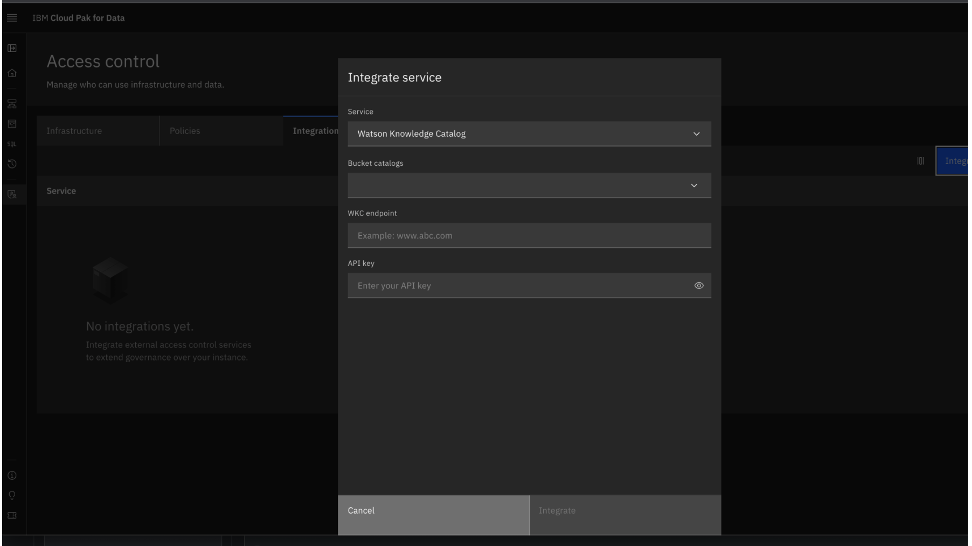
The following image shows a completed integration screen.
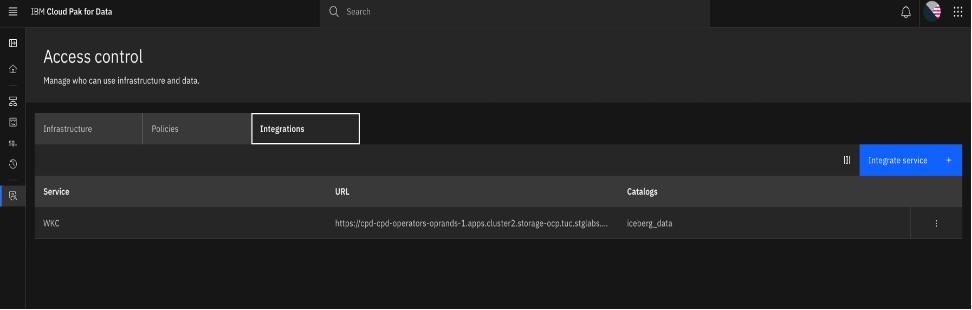
Step 6. Verify the masking functions per the rules in IBM Knowledge Catalog
Log in to IBM Cloud Pak for Data using the admin user name and password.
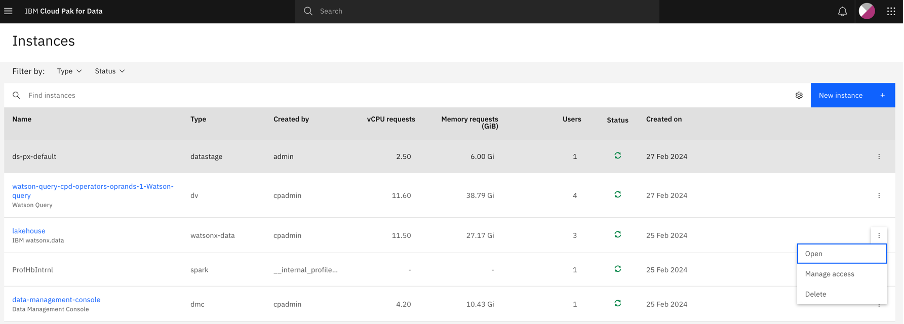
From the homepage, click Rules from the left menu, and cross verify that the rules exist for the fields that you are looking for.
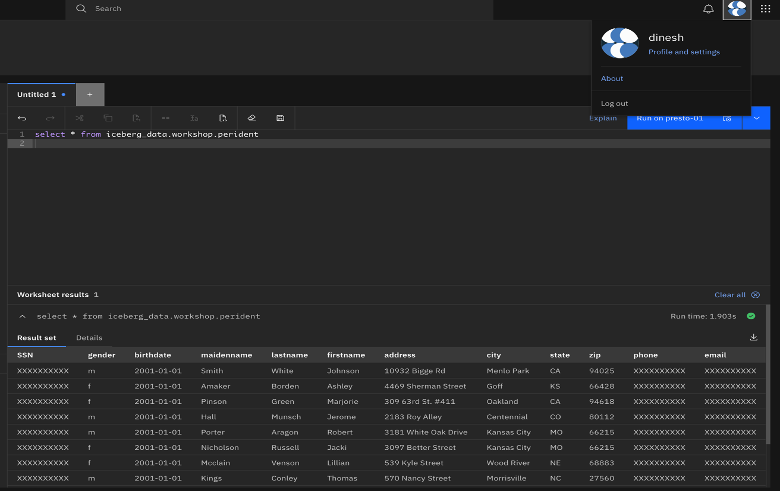
Log in to the Lakehouse Engine SQL Editor as a user who is not the owner of the asset in IBM Knowledge Catalog.
Lakehouse query screenshot:
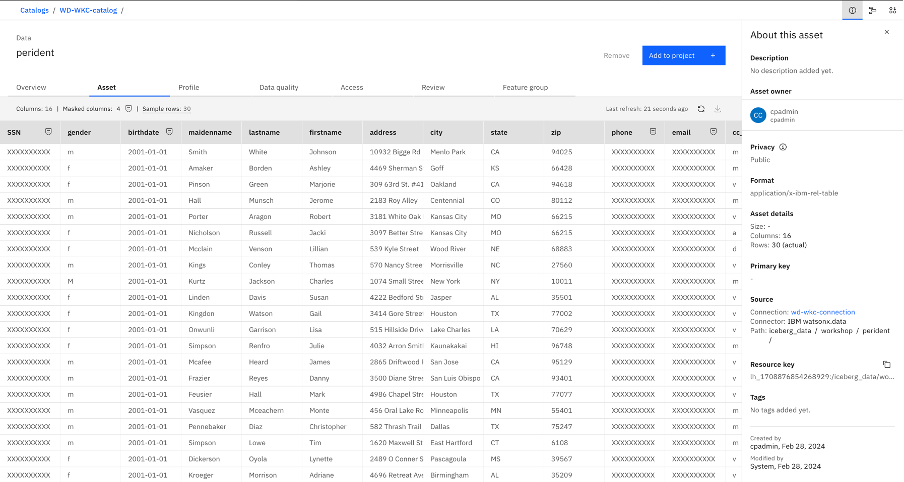
Catalog screenshot as non-admin user:
Validate with admin user.
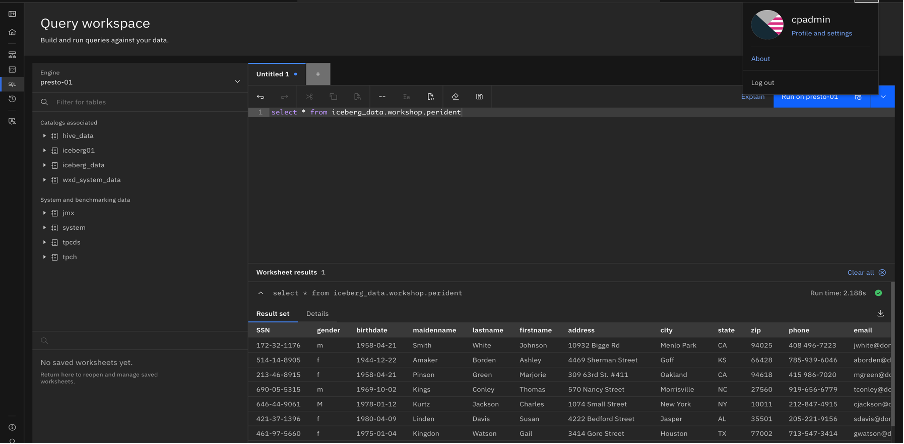
Catalog data using admin:
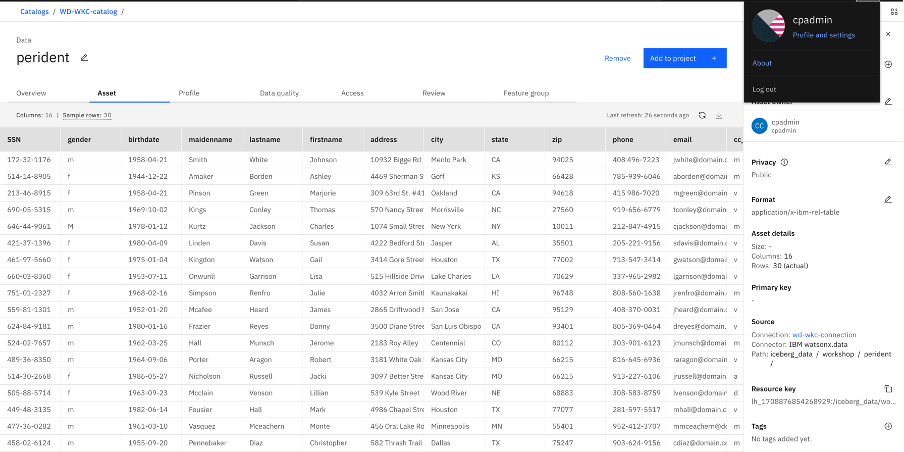
Watsonx.data data using admin for the same table:
Summary
In this tutorial, you learned the process of integrating on-premises watsonx.data with the IBM Knowledge Catalog, a crucial step that lets you test data protection rules and governance policies on your own. The hands-on experience helps you grasp the details of lakehouse technology more effectively and explore its potential applications within your specific context.
Learn more about watsonx.data. You can also start your free watsonx.data trial.