About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Event-driven architecture usage patterns for the Kafka era
Event-driven solutions for hybrid cloud architectures
In this article, we will explore the typical high-level event driven architecture (EDA) usage patterns for Apache Kafka. We will also look at how these usage patterns typically mature over time to handle issues such as topic governance, stream processing, and AI.
This article complements and extends my webinar at the 2023 Cloud Architecture Virtual Summit on EDA patterns in a hybrid cloud landscape:

Video will open in new tab or window.
A few years ago I wrote about how event driven architecture was back in the news. At the time, the most common question seemed to be around how Apache Kafka was different from the messaging technologies that came before it. What’s interesting is that the more you delve into the differences, the more it becomes clear that the two technologies were designed for very different use cases. Furthermore (spoiler alert), they are more likely to end up being complementary to one another than competing.
However, we could spend all day listing the differences between technologies and it wouldn’t necessarily help us make solutioning decisions. It’s often better to start from the other end and ask, “what is Kafka most often used for?”
The three primary usage patterns for Apache Kafka
I speak with many companies each year, and I’m starting to see some commonality in the reasons they deploy Apache Kafka. I’m going to call these “usage patterns” rather than use cases, because as you’ll see, each one has a natural evolution from basic to advanced. Knowing how the pattern will evolve is key when it comes to knowing which aspects of your design are worth future-proofing.
Let’s quickly summarise these key patterns, then we will add a little detail:
Event notifications. This pattern begins simplistically with the idea that you want to be notified immediately when something happens. Over time, the definition of “something happens” becomes more sophisticated, perhaps requiring a deeper situational awareness, perhaps building up a context across multiple streams of events.
Event analytics. This pattern typically stems from use of an event stream to populate an analytics engine. However, we soon see that some of the analytical queries could be answered more quickly by directly analysing the event stream, opening the door for efficiencies and innovations.
Event projections. Exposing data via APIs often results in long invocation chains and puts pressure on creaking back-end systems. A common pattern is to use an event stream that contains changes in state to surface the back-end data in a “projection” that is local to the front end. This becomes increasingly more relevant when considering ingress/egress costs across a hybrid cloud architecture.
Why are these usage patterns so well suited to Apache Kafka? Primarily because these patterns can benefit from Kafka’s implicit event history. As such, while these patterns have always been possible, they are a more natural fit than they have been in the past. From these short descriptions, the various uses of the event history may not be immediately obvious, but we’ll bring that to life as we go into more detail.
Notation and core components
Throughout this article we’ll be using a common architectural notation to summarise the architecture as the patterns evolve. Here’s a basic example containing all the primary components.
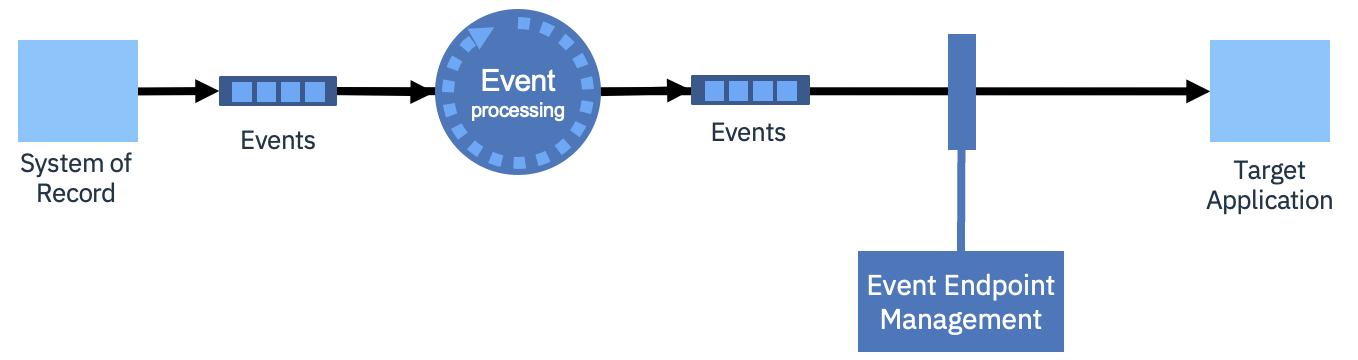
Let's review the core components shown in the diagram:
System of record is an existing application from which events are produced, although the source of events could equally be sensors or devices and so on.
Events represent topics in an event streaming technology such as IBM’s Event Streams capability (a productized version of open-source Apache Kafka).
Event processing refers to a component such as IBM’s Event Processing capability (our Apache Flink implementation) that allows you to work with the events in the stream to transform, enrich, or aggregate them.
Event endpoint management is a component that makes it easier to share topics with consumers. Potential consumers can discover what topics are available, what data they contain, and perform self-service onboarding to use the topics in their applications. This is a new concept in the field of event driven architecture, and IBM are leading the field through their creation of IBM’s Event Endpoint Management capability.
Target application represents the system that will make use of the event data. Although in the above diagram it is simply a subscriber to the events, in some of the more advanced patterns it might have a more complex relationship with the event data.
You might notice that there is no reference to “connectivity” on the diagrams. Mechanisms to extract events from the systems of record, and to push events into target systems, will be equally required in all the patterns so it is non-differentiating. The same is true for other components such as schema registries and topic mirroring. Since these are not differentiating features of the patterns, they are generally omitted for clarity, but that does not mean they are not important to an event driven architecture. Such capacities are often embedded in the other components. IBM’s Event Streams, for example, comes with a catalog of connectors, an integrated Apicurio schema registry, and topic mirroring with MirrorMaker 2.
Let’s understand each pattern in a little more depth. However, because there is much more to be said on each pattern, we’ll treat each one to a full article later in this series.
Pattern 1. Event Notifications
“I want to be informed immediately when something happens.”
The event notification pattern is what people most often think of when talking about the publish-subscribe messaging pattern. In its simplest form, the event notification pattern provides a way for applications to be "informed immediately when something happens”. Events are placed onto a topic, and they will be delivered immediately and continuously to any number of consumers subscribing to that topic. Those consuming applications can then choose whether to take immediate action.
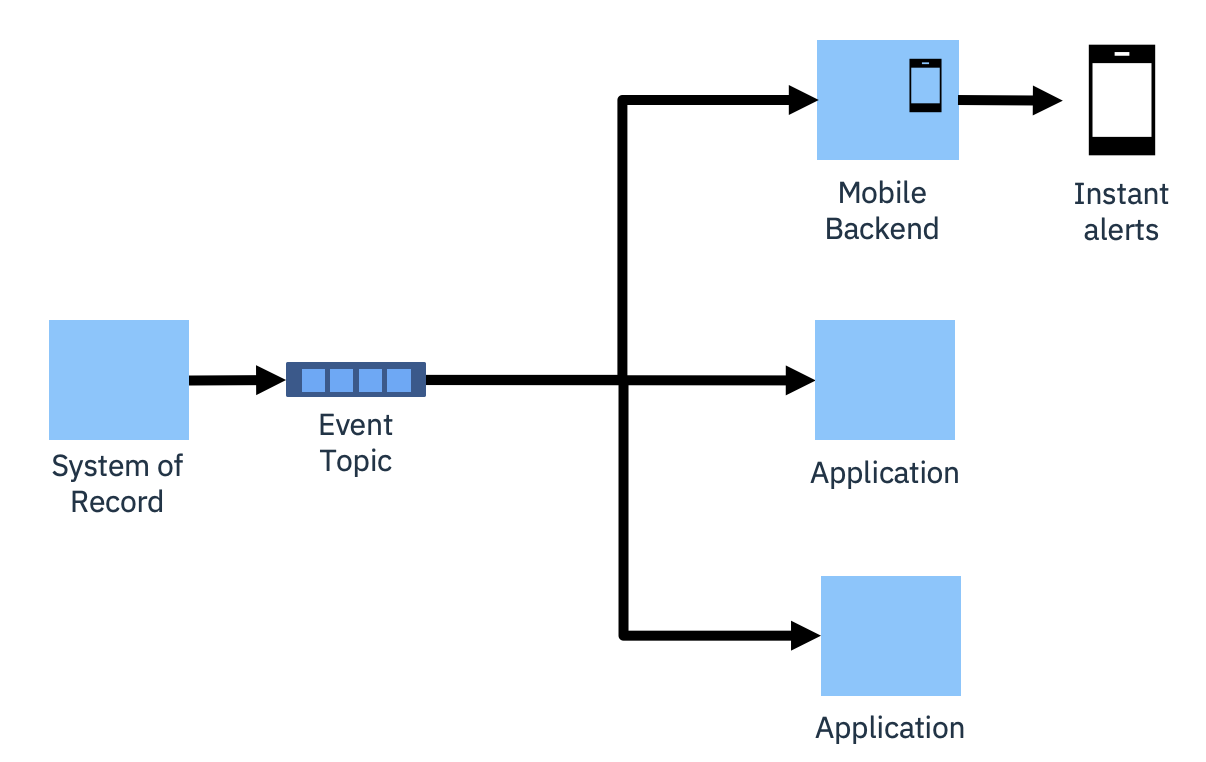
This pattern enables subscription to events of business importance to provide instant alerting, and the opportunity to take timely action.
To make it easier for consumers to locate the topics of interest, event endpoint management is often introduced. This enables easy discovery and self-subscription to the event topics, and provides an enforcement point for policies and topic lifecycle.
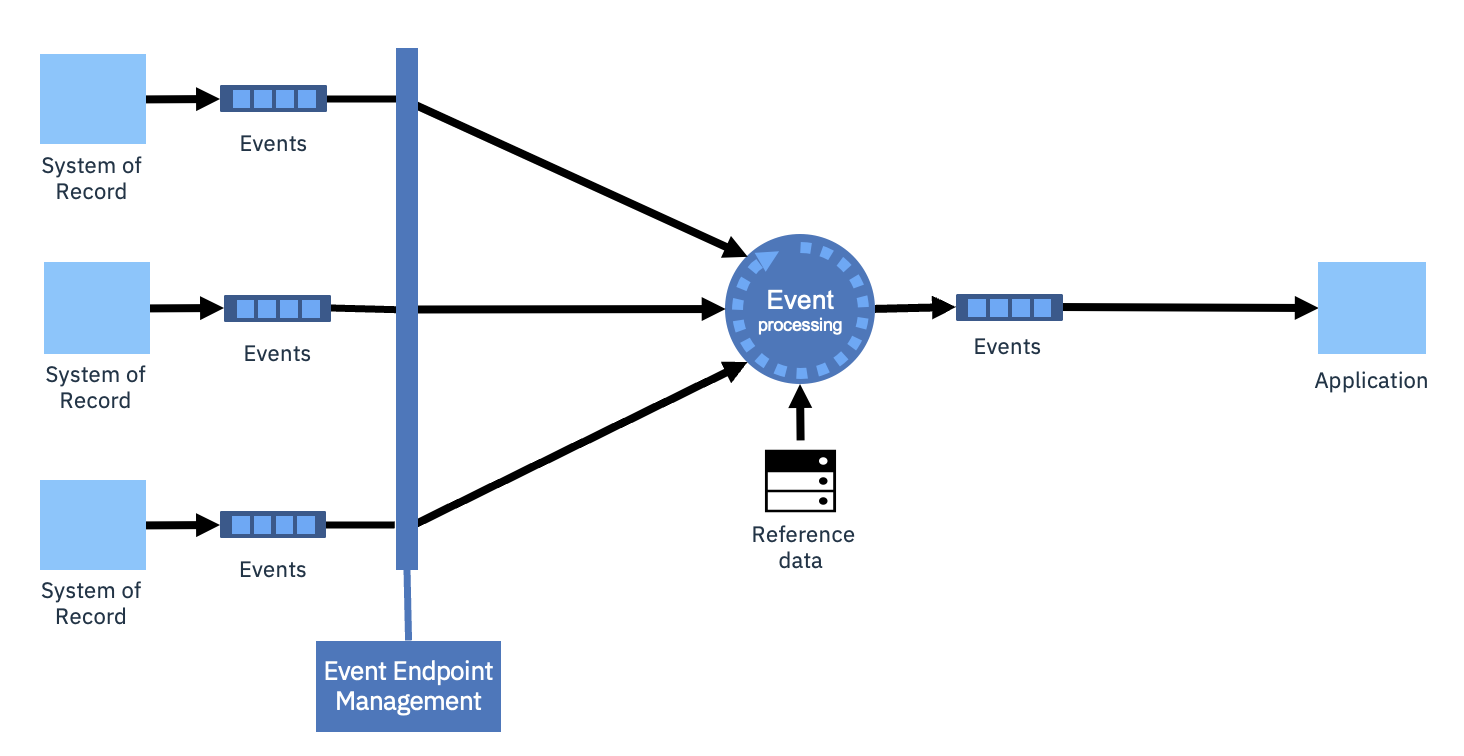
Event processing is often introduced to improve the value of the events for a specific consuming application. This might just involve stateless processing such as converting them to standard data models, filtering events, and enrichment. More advanced processing can perform aggregations or pattern match across the stream history. Multiple topics can even be compared or collated in order to detect context-based situations.
There is also an opportunity in the event notifications pattern to enrich the notifications based on interactions with AI models. AI could evaluate the context and help to classify which segments of the customer base that would be most likely to be interested in a particular notification. This might help the consuming applications to prioritize which notifications to show to users and avoid notification fatigue.
Ultimately, the notification topics become so valuable that they are seen as a key interface to the “data products” of the enterprise, complementing the API economy that is essential to rapidly exploring new innovations.
This pattern is at its most powerful when used to provide near real-time contextual awareness, such as to provide a more personalized and responsive experience to users of an application. For example, capturing a user’s attention during a shopping experience in or near a store in order to provide them with relevant personalized offers.
Pattern 2. Event Analytics
"I want to perform continuous analysis as changes occur."
The event analytics pattern focuses on the desire by most organizations to be able to perform increasingly more real-time analytics on enterprise data.
Traditional extract/transform/load (ETL) pipelines have been optimized over time but remain periodic and batch based. This means your analytics are limited by the batch timing, which could be hours or even days in length.
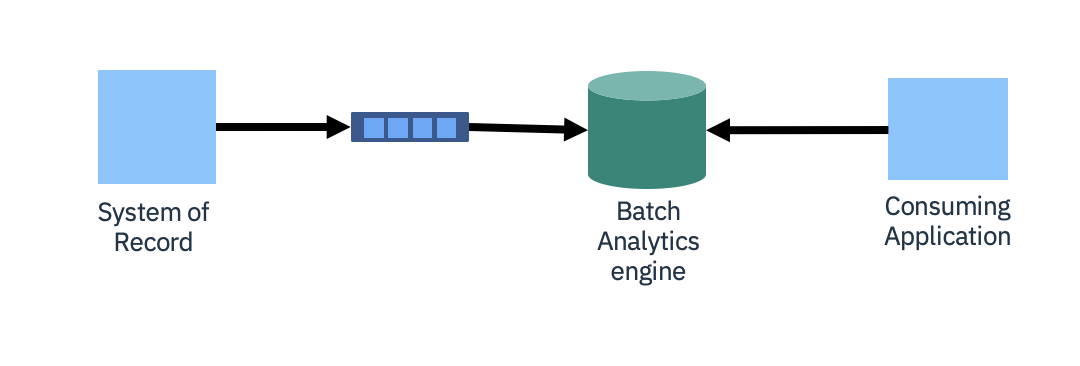
Shifting the extraction process to be event based, continuously sending changes into an event stream, removes the batch periodicity. Data is continuously delivered to the analytics engine.
However, you are still potentially at the mercy of the batch-based nature of the analytics engine. It might need to bring in events periodically to create self-consistent indexes for the more complex queries. So, there might still be some significant latency before the analytical results are made available.
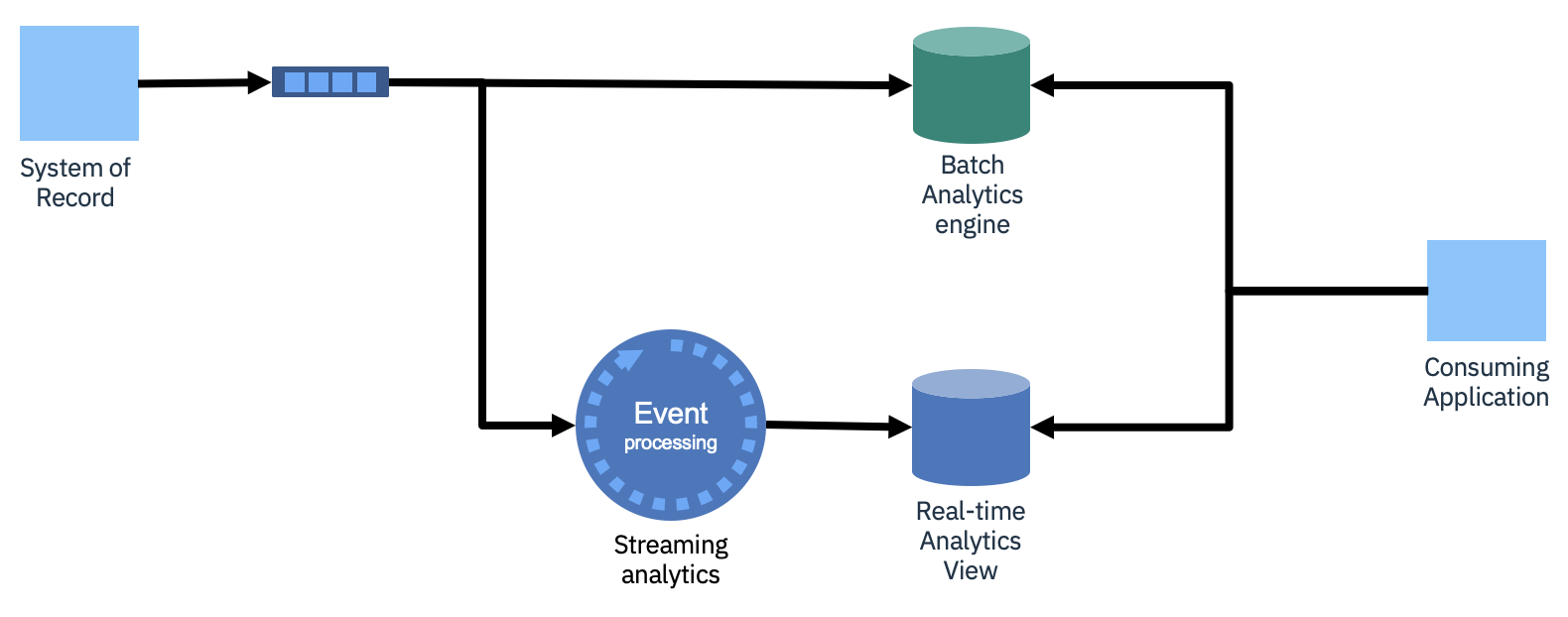
The next logical step is to see if some of the analytics can be performed directly on the event stream itself using streaming analytics. This would then enable you to create near real-time analytics views for some of the queries.
There is significant similarity between this pattern, loading an analytics engine, and the need to train AI models. Event streams provide a rich source of data for training machine-learning-based AI models. Furthermore, because they contain a full event history, you could train a machine learning model on one segment of the event history, then test the quality of your model on other segments.
This pattern enables near real-time trend analysis in order to react in the moment. For example, reacting to traffic conditions for deliveries immediately during the working day, rather than having them impact the next day’s schedule.
Pattern 3. Event Projections
"I want a local copy of backend data that is kept current."
User interfaces, now more than ever, require extremely low latency access to data. However, often that data actually lives in a remote back-end system. That system might not have the performance or availability characteristics, nor might the network always be accessible or have suitable bandwidth.
A simple solution to this is to use data change events to re-create a local copy of the data in the back-end system, and to then keep it current. This local copy is known as a projection.
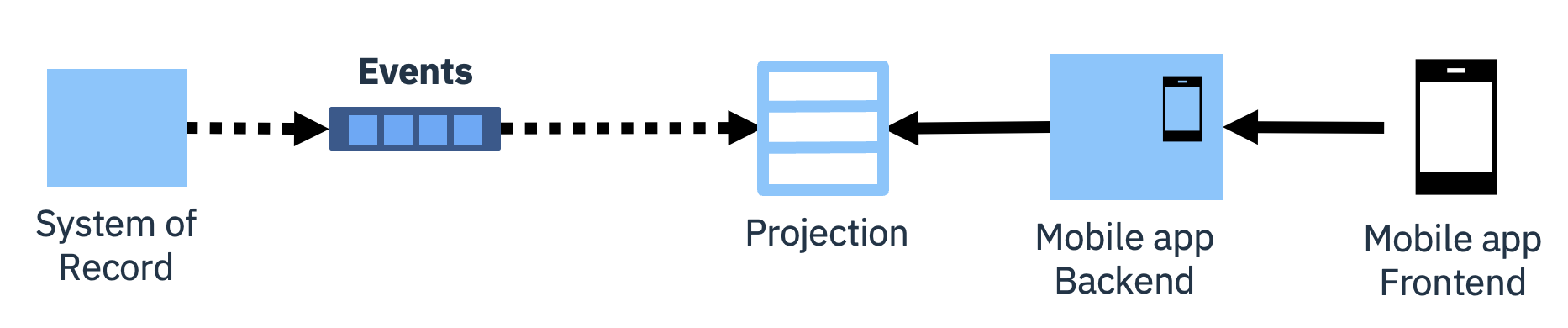
If the creation of the projection is owned by the front-end application, it can re-create the projection at any time, simplifying data model changes or even switching to a different type of data store.
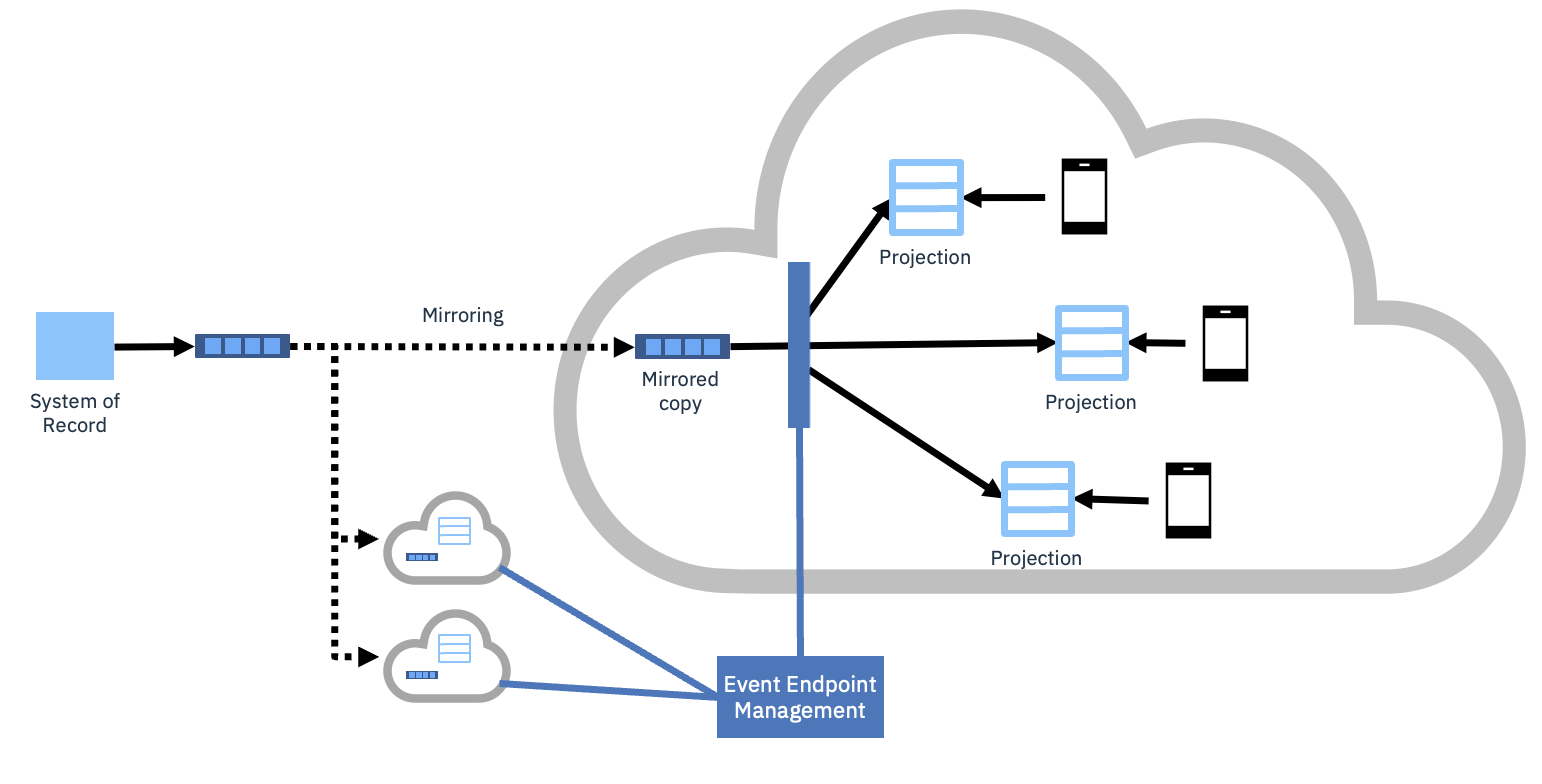
In a hybrid multi-cloud environment, projections have an additional benefit of helping to reduce the ingress/egress costs of data between clouds. A centralized event endpoint management could then ensure that the consuming applications are connected to the mirrored copy in their own cloud.
These days, advances in AI are extremely fast paced. An aspect that is coming to the fore is the need to use retrieval-augmented generation (RAG) to enhance queries to large language models (LLM). RAG adds additional information not originally in the LLM’s training, such that it can provide more informed responses. It is likely that forms of the event projection pattern will be valuable to ensure copies of data injected by RAG can be stored locally and remain current.
This pattern is particularly good at providing performant access to data in legacy systems, such as product catalogs or pricing engines.
Summary and next steps
Here’s a simple infographic that provides a quick reference to the key aspects of each pattern.
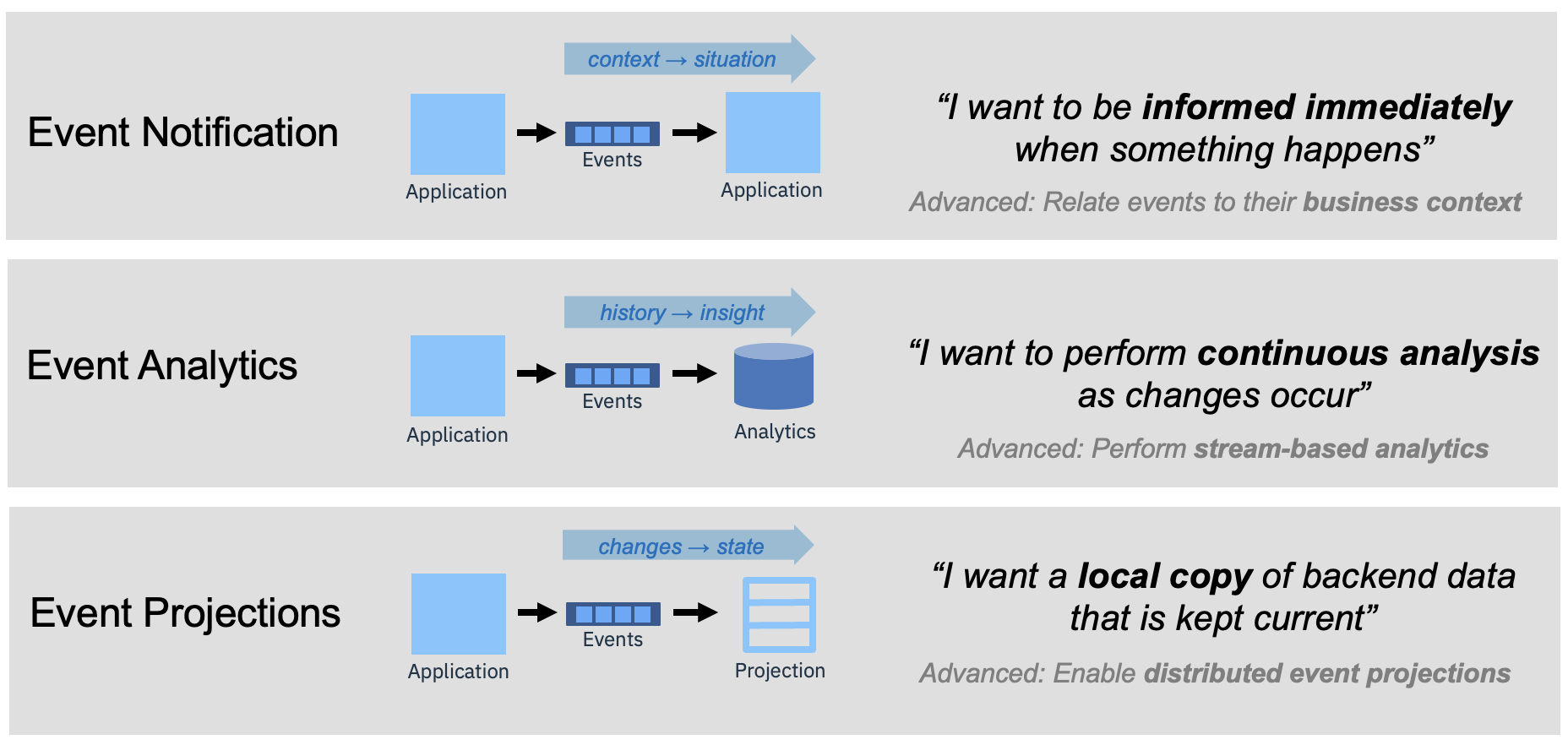
We’ve found it really valuable to have these three core patterns in mind at various stages in the lifecycle of a solution:
Familiarization. Use the concepts to explore our understanding of the breadth of EDA usage patterns. Provide a vocabulary to guide conversations about EDA.
Innovation. Surface potential new use cases by exploring each pattern in turn and relating it to areas of the business. Explore use cases in depth using the patterns as the basis of a whiteboard session. Inspire business innovation by exploring the evolution from “basic to advanced” in each pattern.
Enterprise architecture. Help categorize and organize EDA intentions and understand the skills and technology required.
Design and implementation. Ensure you’re driving towards a well understood goal, or indeed spot if you’re pivoting. Get a head start on key design decisions, from topic characteristics, to architectural layouts and infrastructure requirements.
We use the EDA usage patterns regularly in innovation workshops to explore how the evolution of event driven architecture could best be used in an enterprise.
In future articles in this series, we’ll take each pattern in turn and provide details to help you really understand how they work and the benefits they bring.
For more information on IBM’s event related products, explore IBM Event Automation.