About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Key scenarios and components of RAG Deployable Architecture
Explore IBM RAG DA capabilities for deploying secure, customizable RAG solutions tailored to enterprise needs
On this page
Retrieval Augmented Generation (RAG) combines the generative AI capabilities of large language models with enterprise-specific data sources, utilizing proprietary knowledge bases instead of relying on general-purpose public data. To build and implement RAG solutions successfully, enterprises must understand the core concepts and underlying technologies.
The RAG Deployable Architecture (RAG DA) simplifies this process by providing pre-configured solutions for multiple RAG scenarios. It automatically sets up relevant watsonx services and supporting components on IBM Cloud, saving significant time and effort in planning, deploying, and configuring secure RAG solutions.
The RAG DA is readily available in the IBM Cloud catalog, with detailed deployment and configuration steps. You can refer to the deployment steps for making configuration changes based on the configurations options that you choose.
This article explores the primary scenarios supported by the RAG DA, including:
- Choice of technologies: Understanding available options.
- Integrations and capabilities: Leveraging built-in features.
- Use case alignment: Selecting the best-fit configuration.
The guide article enterprises evaluate and decide on the RAG DA pattern most suited for their specific needs.
Key components of a production-grade RAG solution
A robust RAG solution typically includes:
- Application runtime: Hosting platform for user interfaces and APIs.
- Generative AI platform: Foundation models and machine learning capabilities.
- Natural language conversation engine: Tools for user interaction and dialogue.
- Data repository and indexing: Mechanisms for content storage, search, and retrieval.
- Summary generation: Tools for summarizing enterprise data.
- Security, observability, and continuous compliance: Ensuring data integrity, transparency, and adherence to regulations.
Flexibility and customization
RAG DA provides multiple configuration options for each component. While some options are selected by default based on the chosen variation (Basic or Standard) when adding the architecture to a project, these configurations can be customized or modified at the project level before deployment.
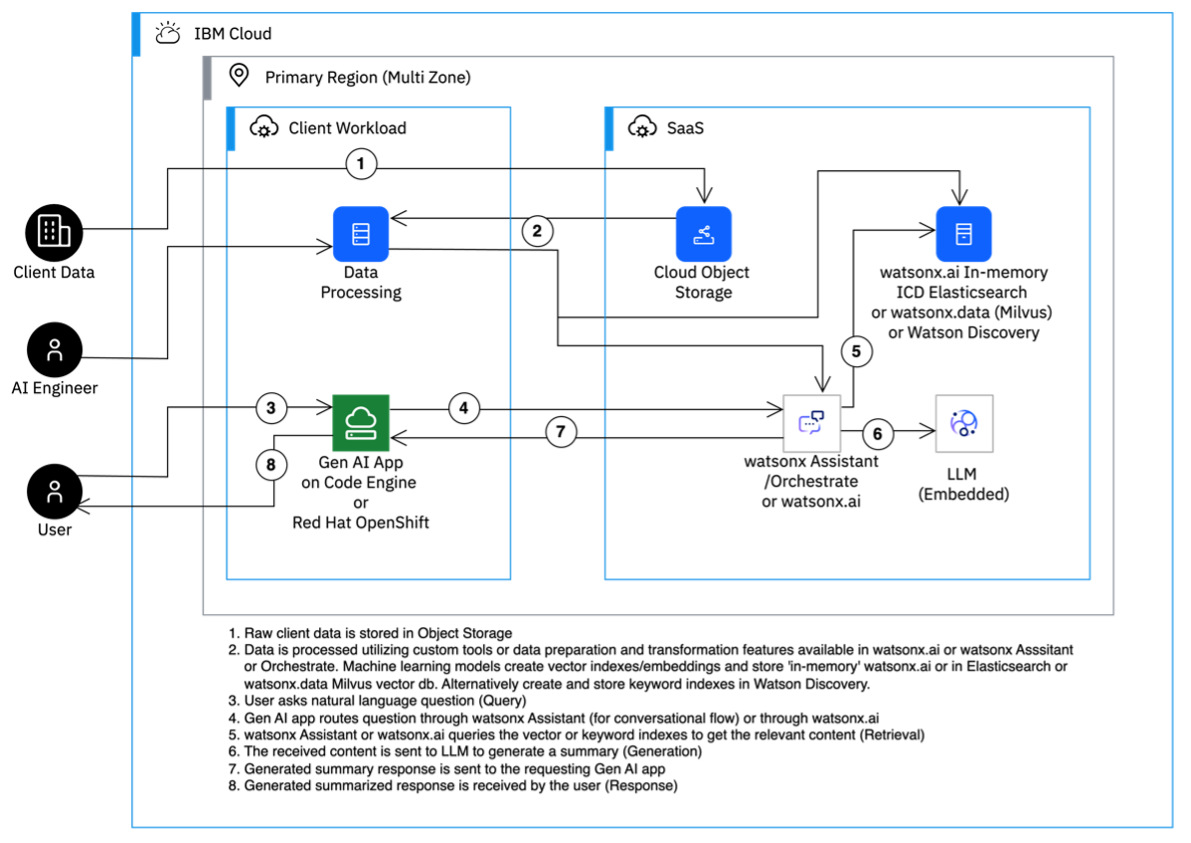
The following sections explores the components and their deployment options, enabling informed decision-making for your RAG solution.
1. Selecting the application runtime
The application runtime is a critical component of RAG solutions, as it hosts the interface through which users interact with the system. For most RAG use cases, this interface is a web application that allows users to engage with a virtual chat agent in natural language.
Basic Variation - Code Engine:
The Basic variation of the RAG DA uses IBM Code Engine to deploy a containerized, serverless web application. This is a cost-effective option suitable for simpler applications that require minimal infrastructure.
Standard variation - Red Hat OpenShift: The Standard variation uses Red Hat OpenShift, a platform for deploying more complex containerized web applications. It supports business processes that require microservices and API endpoints.
| Application runtime options | Description | RAG DA deployment |
|---|---|---|
| Code Engine | For containerized serverless web applications | Default in RAG DA Basic variation with a sample application |
| Red Hat OpenShift | For applications with microservices and API endpoints | Default in RAG DA Standard variation with a sample application |
The default RAG DA configuration deploys a sample application on either Code Engine or Red Hat OpenShift, depending on the selected variation, providing a quick-start environment tailored to the specific runtime.
2. Generative AI platform options
The RAG Deployable Architecture (RAG DA) integrates watsonx.ai, watsonx.data, and watsonx.governance to provide a secure, responsible, and comprehensive generative AI platform on IBM Cloud. These components enable flexibility in deploying, managing, and optimizing AI-driven solutions tailored to enterprise needs.
| Generative AI platform options | Description | RAG DA deployment |
|---|---|---|
| watsonx.ai | Brings together new generative AI capabilities powered by foundation models and traditional machine learning (ML) | Default for RAG DA Basic and Standard variation |
| watsonx.data | Enables data for analytics and AI. Provides Milvus vector database. | Optional |
| watsonx.governance | Manage, test and monitor AI/gen AI lifecycle | Optional |
Default deployment: watsonx.ai
- Capabilities:
- Includes Prompt Lab for prompt development, fine tuning, and endpoint deployment that can be used by RAG applications.
- Offers a range of foundation models, including customizable options, for creating data vectorization/embedding and indexing, and inferencing for various types of generative AI tasks such as content question/answer, summarization, classification, and extraction.
- Features the granite family of models, which are enterprise-ready, open-source, and optimized for safety and diverse tasks.
- Benefits:
- Flexibility to create data embeddings and indexes tailored to enterprise-specific RAG tasks.
Optional deployment: watsonx.data
- Capabilities:
- Provides the Milvus vector database for storing vectorized content.
- Enables seamless integration with watsonx.ai for creating vector embeddings.
- Supports open lakehouse architecture for analytics and AI data needs.
Optional deployment: watsonx.governance
- Capabilities:
- Integrates with watsonx.ai for comprehensive governance workflows.
- Supports management of use case assets, quality testing, evaluation, and production monitoring.
- Ensures compliance with AI lifecycle standards for robust and secure deployments.
3. The need for a natural language conversation engine
The complexity and scope of natural language conversations in RAG solutions can vary based on the generative AI tasks involved. Conversations may range from straightforward question answering or summarizing enterprise content to more complex, multi-turn dialogues supporting tasks such as self-service operations. To ensure effective interaction, the RAG solution must maintain context throughout the conversation and take appropriate actions or provide accurate responses.
| Natural language conversation options | Description | RAG DA deployment |
|---|---|---|
| watsonx Assistant | Natural language conversation platform | Default for RAG DA Basic and Standard variation |
| watsonx Orchestrate | Natural language conversation and process automation platform | Optional |
Simple conversations
- Use case: Single-turn interactions such as question answering or summarization.
- Recommended approach: Use watsonx.ai directly.
- Deploy prompt templates and indexes from vectorized content stored in Elasticsearch or Milvus.
- Expose these capabilities via API endpoints for integration into an application.
- For basic chat functionality, the chat API can be used to build simple conversational flows within the application.
Complex conversational flows
Virtual agents: For intricate multi-turn conversations, watsonx Assistant is ideal.
- Features:
- Supports Conversational Search by integrating with sources such as Elasticsearch, Watson Discovery, or other content repositories.
- Embeds a choice of foundation models for advanced content summarization and retrieval.
- Use case: Virtual agents facilitating interactive and context-aware discussions.
- Features:
Process-oriented workflows: For conversations that require integration with third-party services to orchestrate business processes, watsonx Orchestrate is recommended.
- Features:
- Builds on watsonx Assistant capabilities.
- Adds process automation for streamlined workflows.
- Integrates with watsonx.ai for advanced tasks like content extraction and leveraging foundation models.
- Features:
Common benefits
Both watsonx Assistant and watsonx Orchestrate provide:
- A pre-built chat widget for seamless web application integration.
- Built-in analytics for monitoring conversation trends and understanding user behavior in production.
Default RAG DA configuration
The default RAG DA setup deploys watsonx Assistant alongside Elasticsearch to facilitate conversational capabilities. A sample application with the Assistant chat widget is included to demonstrate end-user interaction.
Note: Without watsonx Assistant, applications must implement custom code to manage user interaction and API calls to watsonx.ai endpoints.
These options allow enterprises to tailor their conversation engines based on the complexity and requirements of their RAG use cases, ensuring optimal functionality and user engagement.
4. Selecting a data repository for indexing and content search or retrieval
RAG solutions often deal with unstructured data such as documents, webpages, and blogs. This content must be processed and stored in a repository with indexes for effective search and retrieval. The RAG DA offers multiple options, including Elasticsearch, Milvus on watsonx.data, Watson Discovery, and Chroma on watsonx.ai. These repositories vary in their approaches to content processing, indexing, and integration with watsonx Assistant, Orchestrate, and watsonx.ai.
Types of Indexes in RAG Repositories
Keyword Indexes:
- Based on natural language keyword matching.
- Simple to create and supported by most NoSQL databases.
Vector Embeddings/Indexes:
- Enable semantic search, focusing on contextual meaning and user intent.
- Machine learning models generate vectors, grouping data points by semantic meaning.
- Provide more accurate search results than keyword indexes, influenced by factors like embedding models, content segmentation, and chunk parameters.
Semantic search using vector indexes generally delivers better search and retrieval results compared to keyword indexes. The effectiveness of vector indexing depends on several factors, including the embedding model used to generate the embeddings, the segmentation or splitting of content, and the configuration of chunk sizes and overlaps during the vectorization process.
| Data repository for content search and retrieval options | Description | RAG DA deployment |
|---|---|---|
| Elasticsearch Enterprise | Create, store, search/retrieve keyword indexes, dense vector embeddings for e.g., for kNN search | Default for RAG DA Basic variation |
| Elasticsearch Platinum | Create, store, search/retrieve keyword indexes, dense and sparse vector embeddings for semantic search | Default for RAG DA Standard variation |
| Milvus on watsonx.data | store, search/retrieve vector embedding for semantic search | Optional |
| Watson Discovery | Intelligent natural language document processing and indexing for keyword search | Optional |
| Chroma on watsonx.ai | store, search/retrieve vector embedding for semantic search. | Default for RAG DA Basic and Standard variation |
Repository highlights
Elasticsearch Enterprise:
- Default for RAG DA Basic.
- Configured with watsonx Assistant for keyword searches.
- Can also support dense vector indexes for k-nearest neighbor (kNN) searches.
Elasticsearch Platinum:
- Default for RAG DA Standard.
- Features ELSER2 for vector indexing and semantic search (English-only).
- For multilingual use cases, integrates with watsonx Orchestrate and E5 small model vectors.
Milvus on watsonx.data:
- Requires deployment of the watsonx.data service.
- Integrates with watsonx.ai for embedding creation using supported embedding models. For multilingual use case, you can create embeddings with E5-large model using APIs.
- Supports custom configurations for watsonx Assistant and Orchestrate.
Watson Discovery:
- Provides keyword search optimized with features such as AI models for the in content extraction, filters, and relevancy training.
- Automates initial data ingestion and integrates with watsonx Assistant and Orchestrate.
Chroma on watsonx.ai:
- Built into watsonx.ai for in-memory vectorization.
- Best suited for temporary or exploratory tasks without additional provisioning.
Key factors for selecting a RAG repository
- Content source and format: Ensure compatibility with the repository's indexing capabilities.
- Indexing frequency: Assess the need for bulk, routine, or on-demand indexing.
- Automation: Look for pipeline features to streamline data processing and index creation.
- Embedding model: Consider the purpose, parameters, dimensions, token limits, pricing, and supported languages.
- Integration: Evaluate compatibility with your conversational engine and generative AI platform.
5. Content summary generation options
The RAG DA offers multiple foundation model options for content summarization. By default, the sample application in the RAG DA configuration uses watsonx Assistant's Conversational Search with an embedded Granite model for English-language summary generation. For multilingual requirements, additional custom configurations are needed.
Using the watsonx Orchestrate option provides access to a range of foundation models, enhancing summary generation and conversational interactions. Alternatively, directly using watsonx.ai APIs offers an extensive collection of foundation models, making it a more versatile choice for multilingual and advanced use cases.
| Content summary generation options | Description | RAG DA deployment |
|---|---|---|
| watsonx Assistant | Embedded watsonx Granite LLM for summary generation task | Default for RAG DA Basic and Standard variation |
| watsonx Orchestrate | Choose from a collection of LLMs | Optional |
| watsonx.ai | Collection of foundation models for generative AI tasks using APIs | Default for RAG DA Basic and Standard variation |
The quality of summary generation largely depends on the chosen model. Consider the following when selecting a model: its purpose and parameters, token limits, pricing tier, language support, and performance on critical safety benchmarks, such as protecting personally identifiable information (PII) and adhering to harmful or abusive policy (HAP) standards.
6. Build an Enterprise-grade solution with embedded security, observability, and continuous compliance
RAG DA includes built-in security, observability, and continuous compliance services, essential for production-grade deployments. These services include identity and access management, data and key encryption, event notifications, secure application delivery pipelines, monitoring, logging, and account activity tracking.
Additionally, the RAG DA integrates the Security and Compliance Center, enabling continuous monitoring of infrastructure for data security, privacy, encryption, and AI compliance controls. This ensures that enterprise solutions meet stringent security and regulatory requirements.
For more details on these services, refer to What is cloud security?.
| Security, observability and continuous compliance options | Description | RAG DA deployment |
|---|---|---|
| IBM Identify and Access Management | Account management and infrastructure administration | Default for Basic and Standard variation |
| Key Protect | Full-service encryption solution that allows data to be secured and stored in IBM Cloud | Default for Basic and Standard variation |
| Secrets Manager | Certificate and secrets management for the deployment | Default for Basic and Standard variation |
| Event Notifications | Notification about critical events that occur in your IBM Cloud account. | Default for Basic and Standard variation |
| Continuous Compliance, Integration and Delivery | Pipelines that securely test, scan, build and deploy the artifacts from the application repositories | Default for Basic and Standard variation |
| Cloud Logs and Monitoring | Operational logging and monitoring for applications, and account activity | Default for Basic and Standard variation |
| Security and Compliance Center | Controls for secure data and AI workload deployments, and assessing security and compliance posture | Default for Basic and Standard variation |
Summary and next steps
RAG solutions offer flexibility to address a variety of enterprise use cases. The RAG Deployable Architecture (RAG DA) simplifies the process by providing the essential technologies and integrations required to plan, deploy, and configure secure RAG solutions efficiently. Deployment configurations are highly customizable, allowing you to enable or disable specific services and reuse existing ones as needed.
This article provided insights to help you evaluate and choose the most suitable patterns and technologies for your specific use case.
Note: Technologies are continuously evolving with ongoing enhancements and improvements. Always refer to the latest product, service, and offering documentation for up-to-date supported features and integrations deployed by the RAG DA.
Next, explore the following tutorials to gain hands-on experience with deploying, optimizing, and maximizing RAG solutions and generative AI capabilities on IBM Cloud.
- Deploy RAG Solutions with Elasticsearch and OpenShift - Learn to implement RAG solutions using Elasticsearch and OpenShift.
- Enhance Chatbot Performance with RAG - Discover ways to boost chatbot efficiency through RAG integration.
- Maximize Generative AI with IBM Cloud Deployable Architectures - Explore advanced generative AI use cases with IBM Cloud solutions.