About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Deploying RAG Solutions with ElasticSearch Platinum and OpenShift
Deploy a retrieval-augmented generation solution using ElasticSearch Platinum and Red Hat OpenShift on IBM Cloud
On this page
The RAG Deployable Architecture (DA), available on the IBM Cloud catalog, accelerates generative AI (GenAI) solutions that are based on watsonx on IBM Cloud. Key benefits include:
- Rapid deployment: Reduces setup time from weeks to hours.
- Cost efficiency: Minimizes costs and mitigates risks of misconfiguration.
- Enhanced security: Accelerates identification of vulnerabilities.
With RAG DA, enterprises can utilize their data for improved productivity in tasks such as:
- Question-answer conversations
- Content search and summarization
- Generative AI-based content creation
The architecture supports multiple configurations and is applicable across diverse industries and use cases.
Deploying RAG DA on IBM Cloud
Using the RAG DA, organizations can quickly set up a watsonx-powered solution on IBM Cloud. This setup provides a secure, scalable, and trusted environment to deploy and manage GenAI applications throughout their lifecycle.
Deployment variations
This tutorial focuses on deploying the GenAI application in the IBM Cloud Red Hat OpenShift (ROKS) environment using Elasticsearch Platinum with ELSER2 (Elastic Learned Sparse EncodeR). Key variations of deployment, include:
Basic (deploy on Code Engine)
- Platform: Serverless workloads using Code Engine.
- Features: Elasticsearch Enterprise for dense vector and keyword indexing.
- Use case: Suitable for lightweight applications requiring agility and scalability.
Standard (deploy on Red Hat OpenShift)
- Platform: Kubernetes-based deployment on Red Hat OpenShift (ROKS).
- Features: Supports microservices architecture. Includes Elasticsearch Platinum with advanced features such as ELSER2 vector indexing for RAG.
- Use case: Designed for complex, high-performance workloads needing robust orchestration and advanced search capabilities.
Comparison:
- ROKS: Ideal for enterprise-level applications with persistent workloads.
- Code Engine: Optimized for lightweight, serverless applications.
Both variations are customizable, allowing organizations to switch services and plans as required.
Additional resources and tutorials
For a detailed tutorial on the basic variation (deploying on Code Engine), see Accelerating Gen AI on IBM Cloud: Deployable Architectures. This tutorial provides insights into the key components of the RAG DA, including toolchains, security and compliance center (SCC), and an overview of the sample banking application deployed with the pattern.
While core components are shared across both variations, this document emphasizes the ROKS environment and the integration of Elasticsearch Platinum.
Additional future tutorials will explore configurations involving Knowledge Base/Vector DB setups with Watson Discovery and watsonx.data Milvus.
Red Hat OpenShift Deployable Architecture (DA)
The Red Hat OpenShift (ROKS) Deployable Architecture (DA) is designed for security and scalability, offering a pre-configured setup to ensure secure operations by default.
Key features of the ROKS cluster DA
Cluster configuration: By default, the cluster includes 2 worker nodes, each with 4vCPUs and 16 GB of memory. The cluster size can be customized to meet specific requirements.
Private endpoint: The OpenShift console is accessible only through a private endpoint. A VPN connection is required to access the Virtual Private Cloud (VPC) hosting the cluster. For this setup, a client-to-site VPN was used. A VPN service is available in the IBM Cloud catalog.
Note: Direct console access is not required for testing the sample application deployment. The deployed chatbot application URL is included in the output of the Sample RAG App Configuration DA deployment, enabling access without the OpenShift console.
Public ingress and load balancer provisioning
As part of the RAG stack deployment, the Workload - Sample RAG App Configuration DA component includes an option (enabled by default) to:
- Provision a public load balancer.
- Configure a public ingress within the OpenShift cluster.
Resources for public access
The following resources are automatically provisioned to enable public access to the sample application:
NLB DNS entry: A public DNS entry is created for the cluster. A new certificate is automatically requested for the DNS name.
Ingress controller resource: An OpenShift ingress controller references the new NLB DNS entry. OpenShift provisions a new load balancer for the DNS entry.
Network ACL rules: Rules allow TCP traffic from any IP address to port 443 on the new load balancer.
Load balancer configuration: The NLB DNS entry points to the newly provisioned load balancer.
Note: Only the sample app route is configured for public ingress. Other cluster deployments, including the OpenShift console, remain inaccessible via the public load balancer.
Disabling public ingress
If public access is not required, the public ingress option can be turned off:
Navigate to the configurations of the Cloud Project where the RAG stack instance is deployed.
Locate the Workload - Sample RAG App Configuration DA component.
Select Edit from the menu.
Find the “provision_public_ingress” input under Configure -> Optional Section and set it to false.
Save changes, validate, and redeploy the configuration.
Note: This adjustment can also be made before the initial stack deployment.
Private ingress access
Without public ingress, the application will be accessible only via private routes. These routes can be found in the OpenShift console by navigating to routes in the “dev” project.
Impact on CI/CD pipelines
If public ingress is disabled, the dynamic scan step in CI/CD pipelines will fail, as the application will not be publicly accessible for scanning.
This default-secure architecture ensures robust control over application access while supporting flexibility for public or private deployment needs.
Key features of Elasticsearch Platinum
Elasticsearch ELSER2 (Elastic Learned Sparse EncodeR): A retrieval model that supports semantic search, enabling the retrieval of highly relevant search results by understanding the contextual meaning of queries.
Sparse and Dense vector indexes:
Sparse vectors: Store non-zero values only where needed, optimizing memory usage. Ideal for keyword-based search indexes, providing precise matches.
Dense vectors: Perform searches based on contextual meaning rather than specific keywords. Commonly used to enhance chatbot responses by identifying patterns in large datasets and better understanding user intent for more accurate replies.
Keyword search indexes: Allow for precise searching using specific terms or phrases, ensuring quick and accurate results for structured queries.
With these advanced indexing capabilities, Elasticsearch Platinum enables chatbots to:
- Respond efficiently and contextually to user inquiries.
- Seamlessly handle complex queries, ensuring a superior user experience.
Deployment of the Deployable Architecture
Before you begin
Ensure that you complete all prerequisite configuration steps detailed in the GitHub repository.
Step 1. Navigating to the RAG pattern tile
Log in to your Cloud account and navigate to the Catalog.
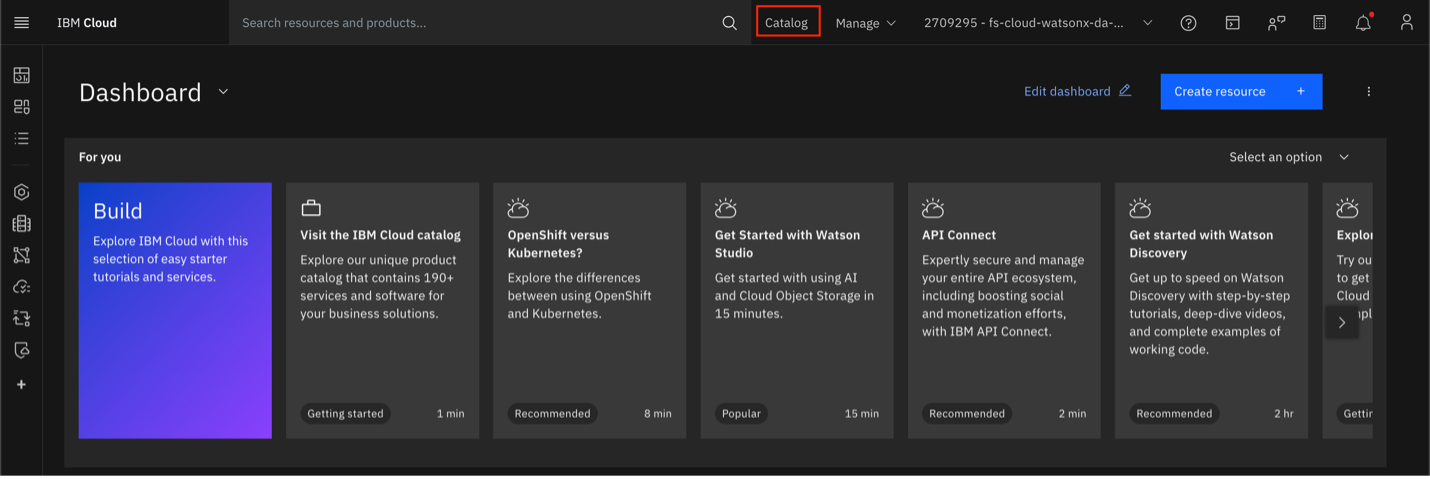
Change the catalog to Community Registry. Use the filter on the left-hand side under Type to select Deployable Architecture.
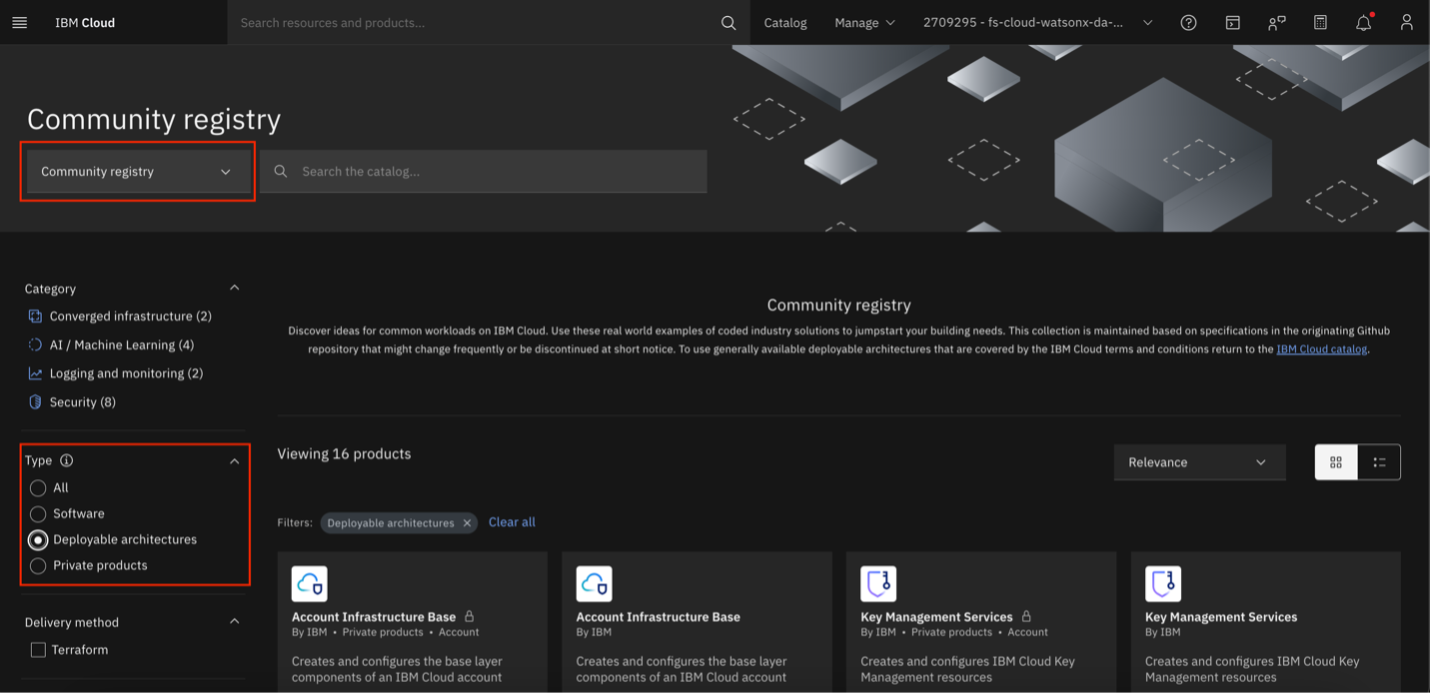
Select Retrieval Augmented Generation (RAG) Pattern. Alternatively, you can directly access the RAG DA Tile in the IBM Cloud Catalog.
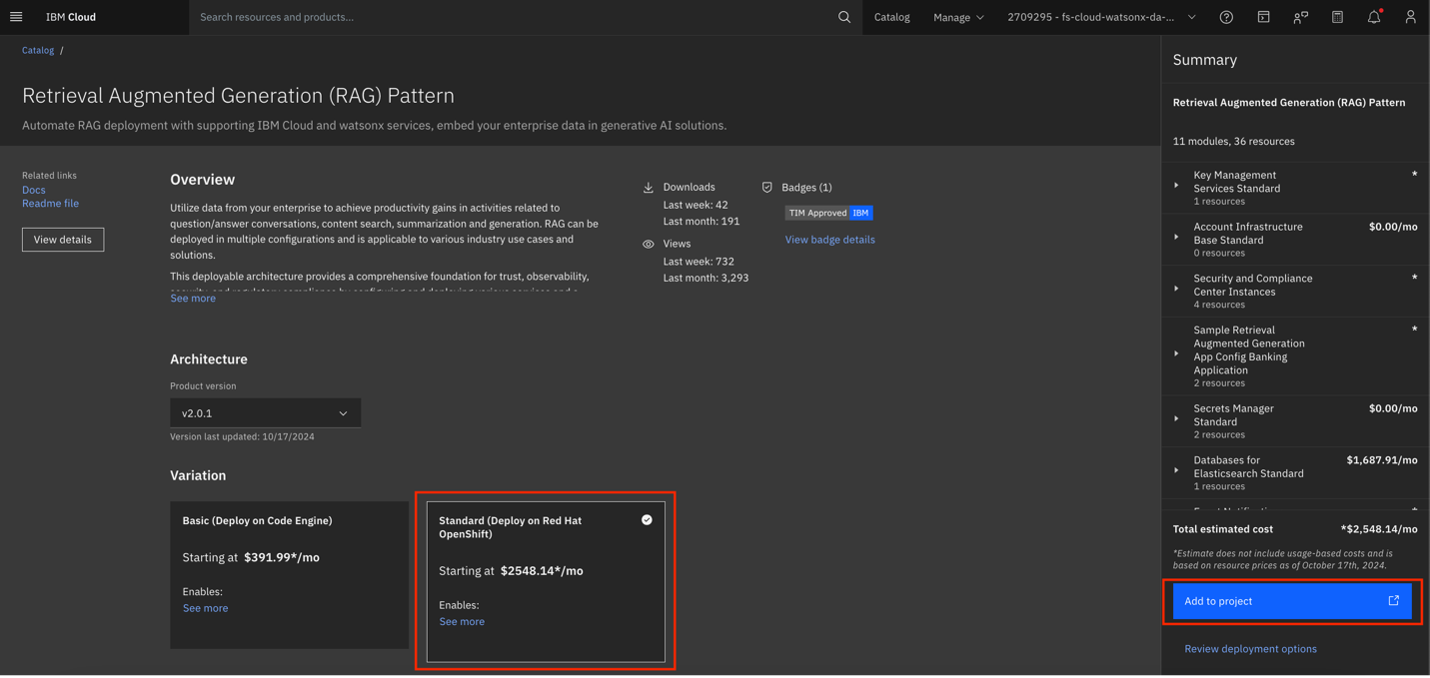
Select Standard (Deploy on Red Hat OpenShift) and then Click Add to Project to proceed.
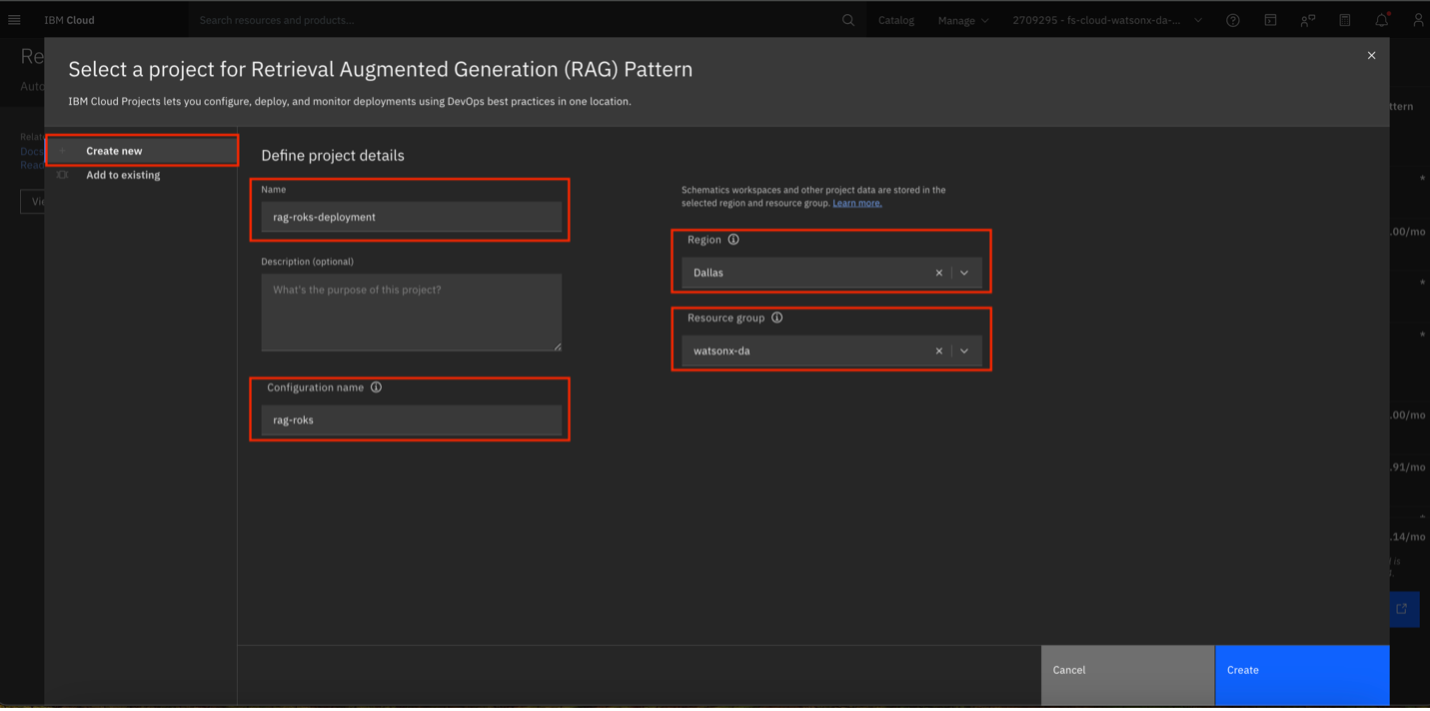
On the Create New tab, provide a Name for the project, a Configuration Name, a Region, and a Resource Group. You can create a new resource group or use an existing one, but note that this group is specific to the Cloud project itself and not the stack resources being deployed. It is recommended to designate a separate resource group for your Cloud projects. If you already have a project, select Add to Existing.
Under the Configuration tab, select Security and provide an API key. Ensure that the API key belongs to a user account with Administrator permissions for all deployed services, as well as for IAM and account management (including roles for creating service IDs and API keys). Avoid using a service ID or trusted profile, as this can cause deployment errors and require additional steps to resolve issues with the OpenShift cluster and Watson services.
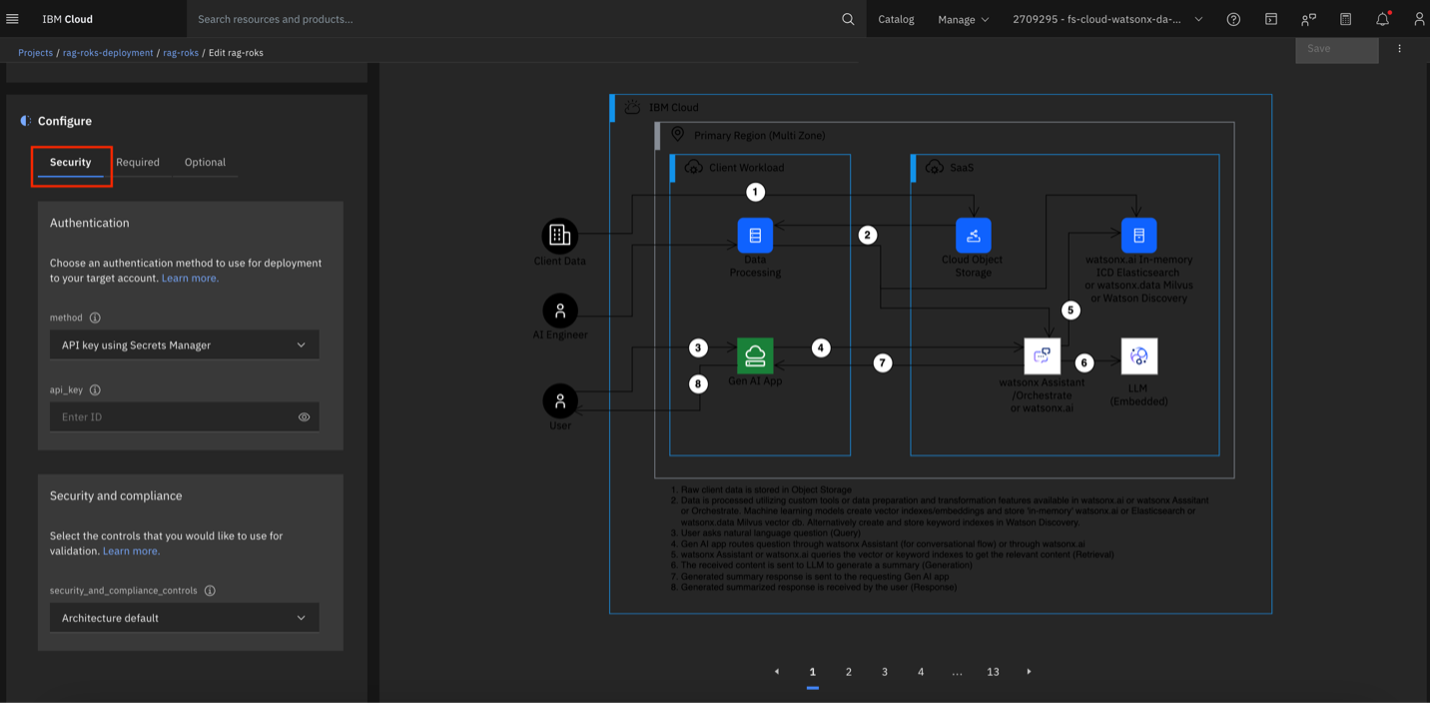
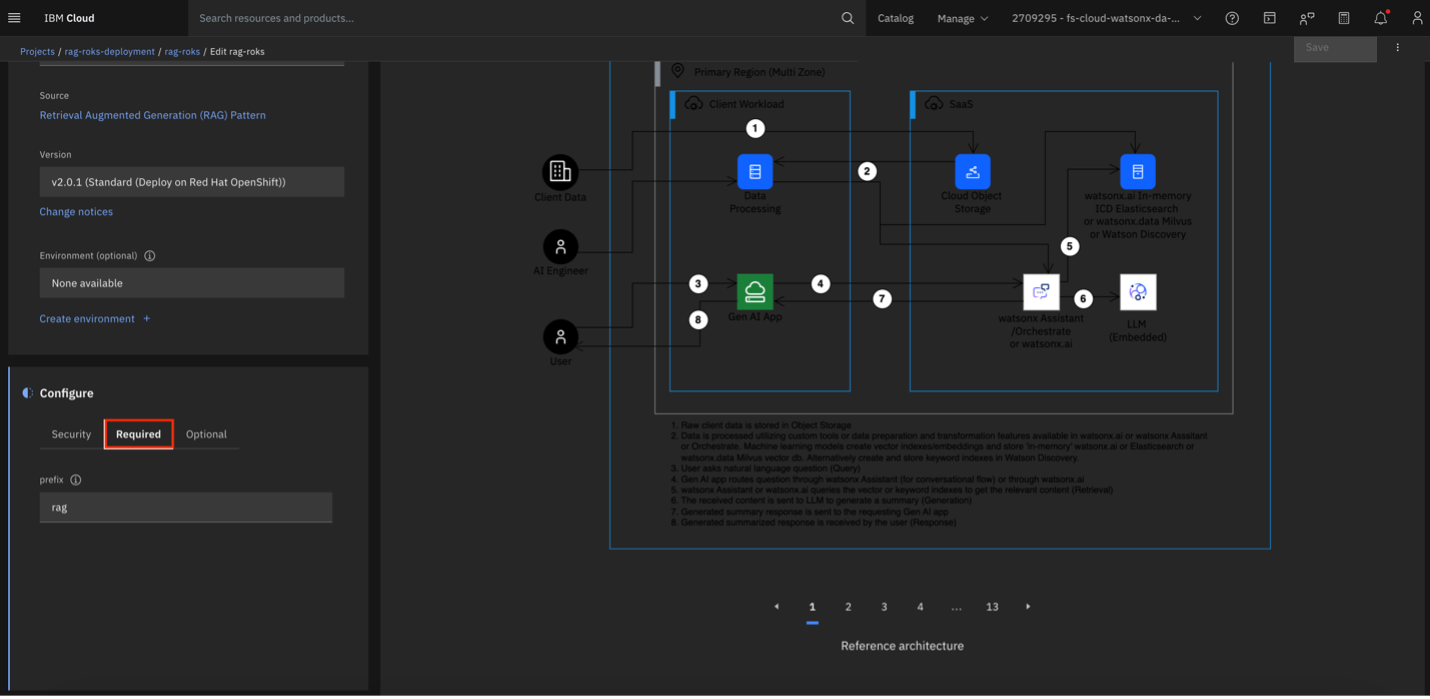
Under the Configuration tab, select Required and provide a prefix that is all lowercase, no longer than 10 characters, and contains no special characters except dashes. This prefix will be added to the names of all resources deployed by the stack, including resource groups.
Under the Configuration tab, select Optional and update the following input parameters to align with your deployment goals:
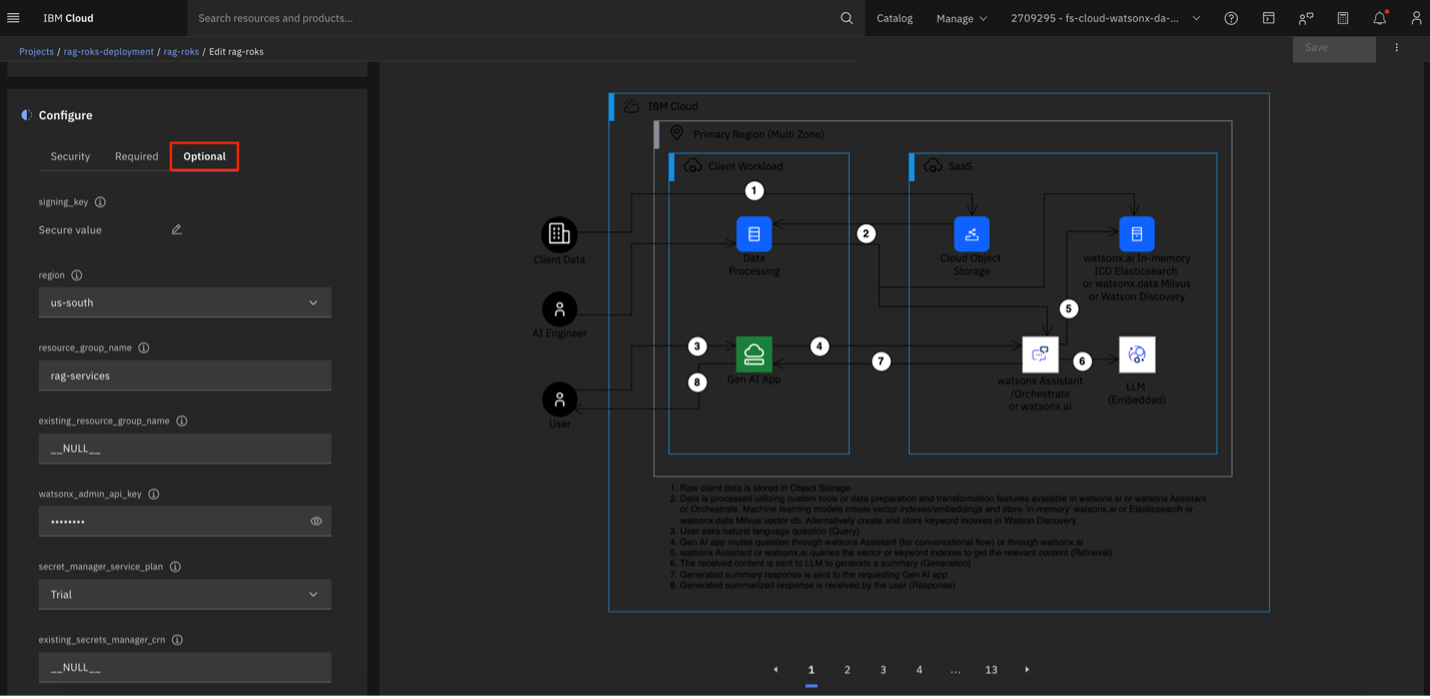
resource_group_name: Combine this with the prefix for a clear naming convention, e.g., "services," resulting in a resource group like "(prefix)-services." To use an existing resource group, set this to
"__NULL__".existing_resource_group_name: Update only if you have already created a resource group and want to use it instead of creating a new one.
secret_manager_service_plan: Set this to Standard if you plan to keep the deployment for more than 30 days. A trial Secrets Manager instance expires after 30 days unless upgraded. Note that only one trial Secrets Manager instance is allowed per account. If you already have a Secrets Manager instance, reference it in existing_secrets_manager_crn, and the secret_manager_service_plan value will be ignored.
existing AI services: If Watson or Elastic services are already deployed in your account, reference them in the existing_... input fields to avoid additional costs. Ensure these instances are in the same account as the other resources being deployed.
Click View Stack Configurations.
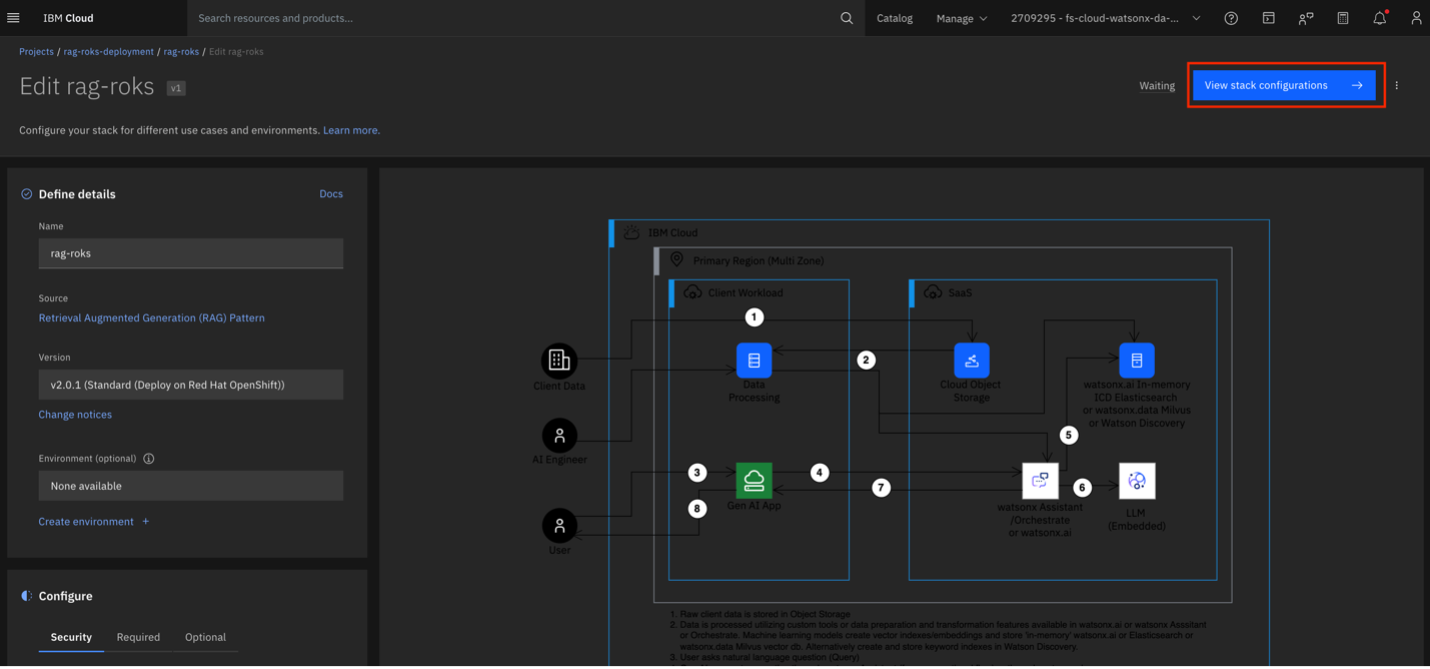
Click Validate to start the deployment of the Deployable Architecture (DA). If Auto-deploy is enabled in the project settings, all DA components will be validated, auto-approved, and deployed sequentially once the first component is triggered. Otherwise, you will need to manually validate and deploy each component as it becomes available for these operations.
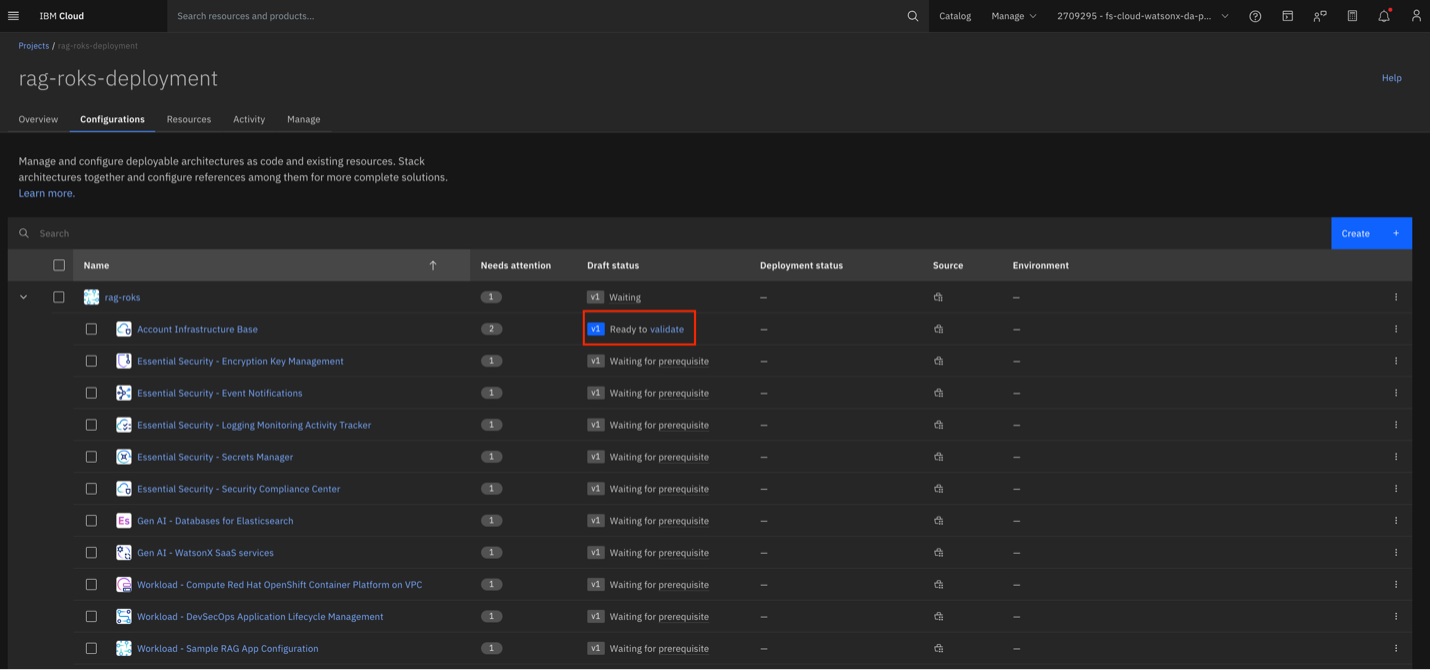
Step 2. Accessing the application through the Project
Open the Navigation menu and select Projects.

Select your project.
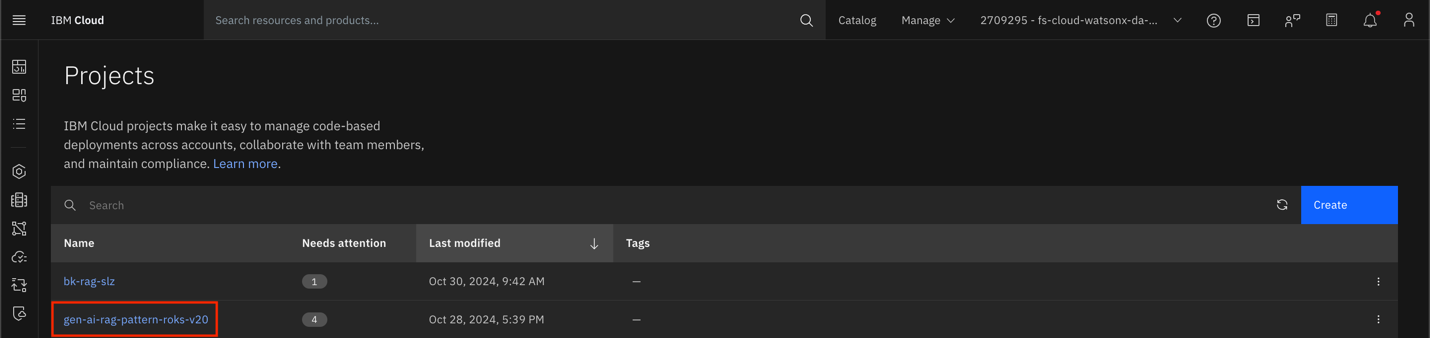
Select the Configuration tab. Expand your project and then select Workload – Sample RAG App Configuration.
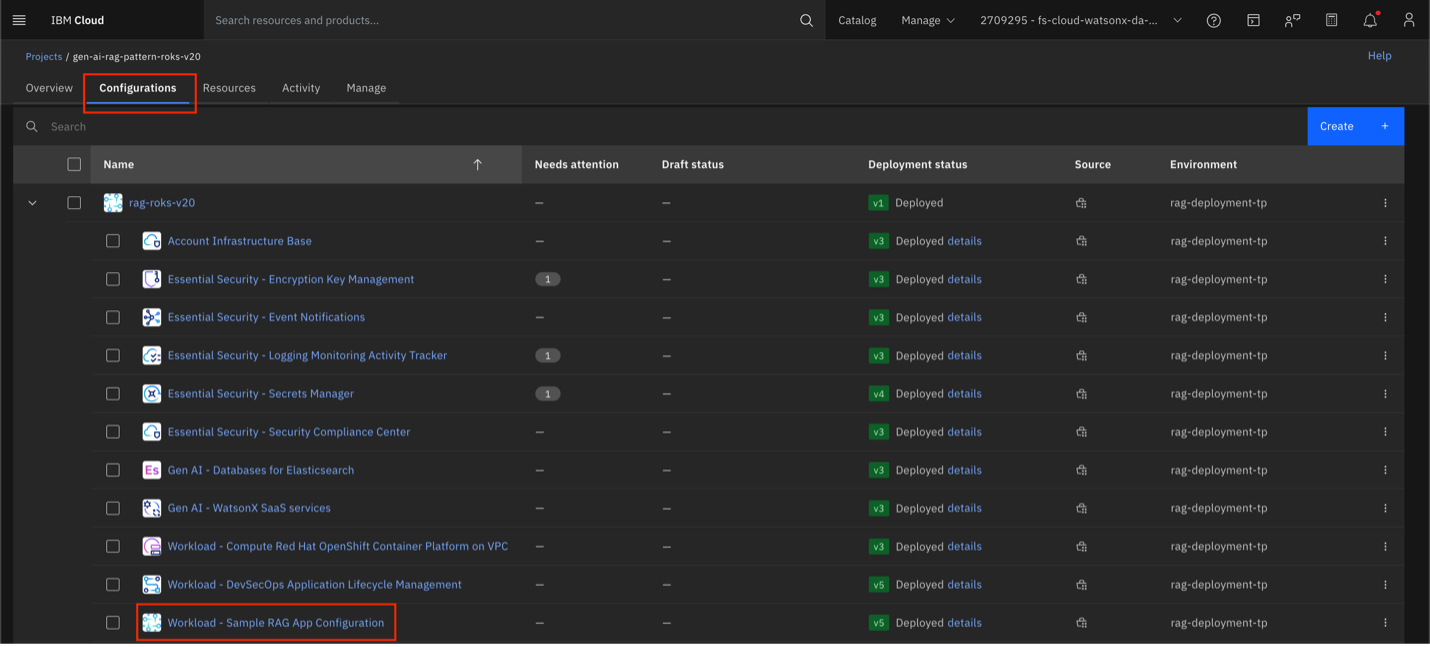
Find the sample_app_public_url and select the URL to open the application.
Step 3. Accessing the application via Cluster Console
To access the ROKS console, a VPN connection is required. For this setup, a client-to-site VPN was used, which is available through the IBM Cloud catalog.
Open the Navigation menu, hover over Containers, and select Clusters.
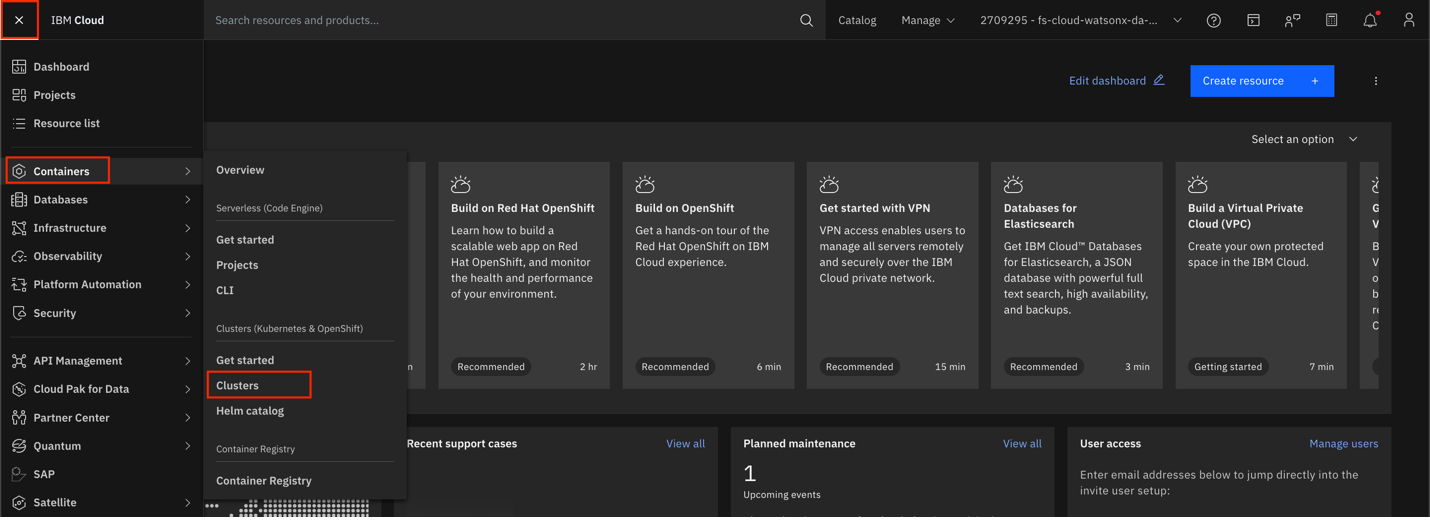
Select your cluster to view its Overview page.
Click OpenShift web console in the top-right corner of the cluster Overview page.
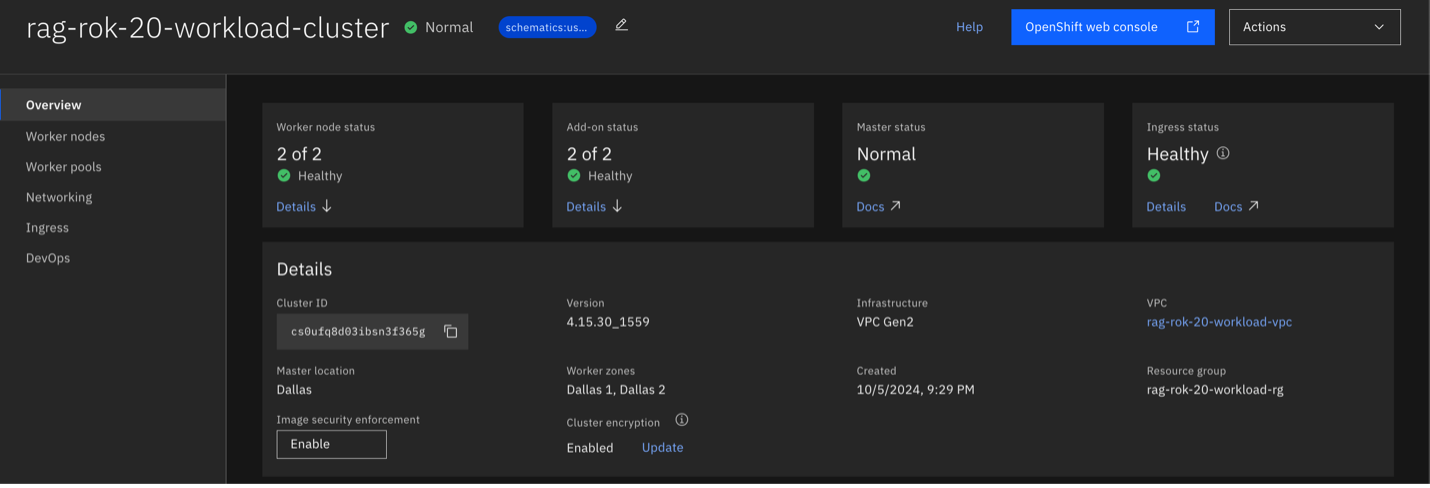
In the OpenShift console:
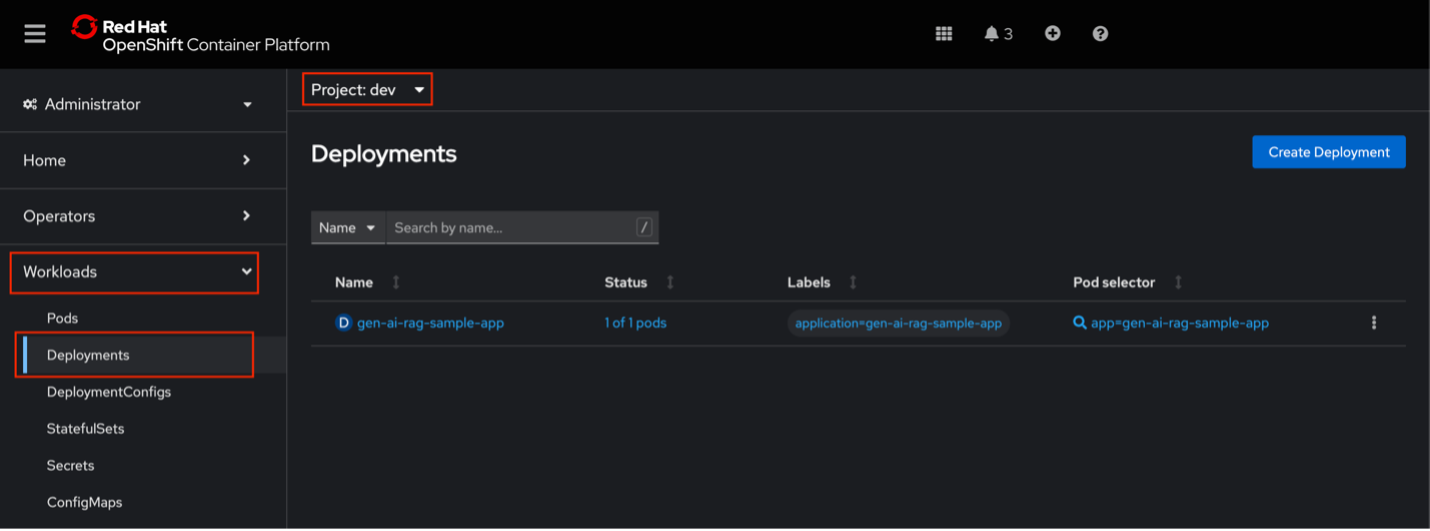
- Expand the Workloads section and select Deployments.
- Ensure that you are working within the Project: dev namespace.
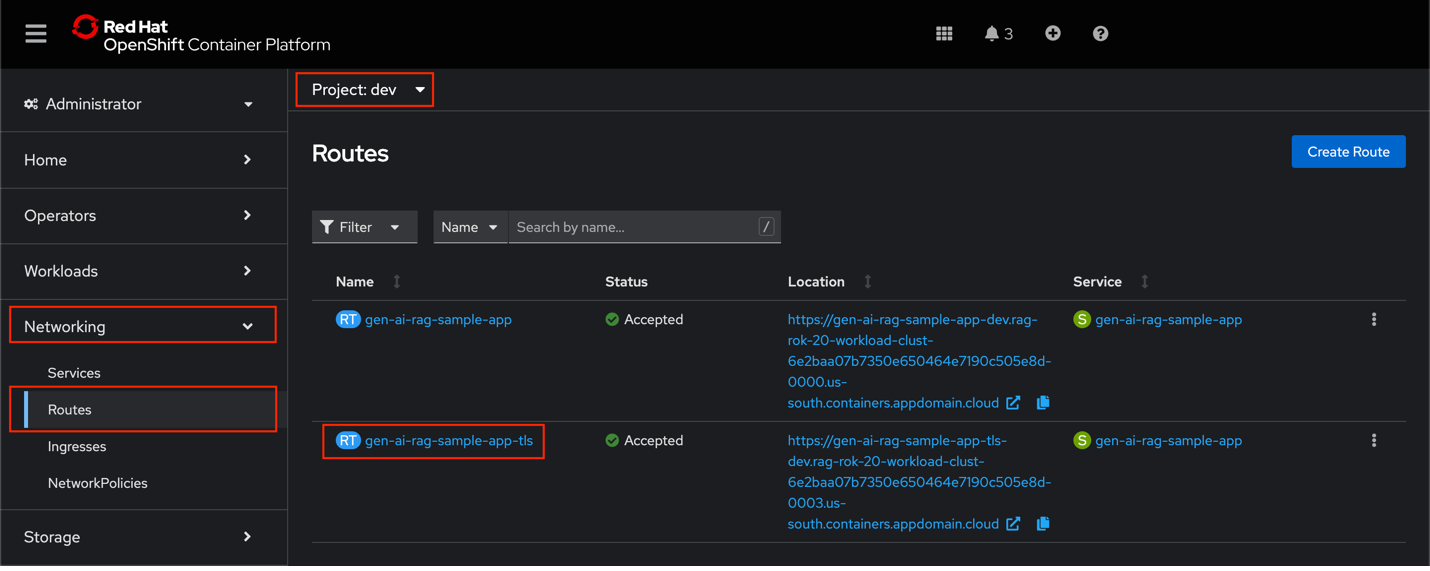
Expand the Networking section and select Routes. Ensure the Project: dev namespace is selected.
Locate the routes:
- The gen_ai-rag-sample-app route is accessible only via private ingress and requires a VPN connection.
The gen_ai-rag-sample-app-tls route is linked to public ingress and can be accessed with or without a VPN connection.
Summary
The Retrieval-Augmented Generation (RAG) DA Standard Variation combines Elasticsearch Platinum with ELSER2 (Elastic Learned Sparse EncodeR) and Red Hat OpenShift on IBM Cloud (ROKS) to provide a robust and scalable foundation for RAG solutions. OpenShift ensures efficient container orchestration and scalability for consistent application performance, while ELSER2 within Elasticsearch Platinum enables fast, context-aware data retrieval. Together, these technologies deliver secure, enterprise-grade capabilities, ideal for large-scale, data-driven applications, and seamless, real-time user interactions.