

What is a vector database?
Vector database definition
A vector database is a database that stores information as vectors, which are numerical representations of data objects, also known as vector embeddings. It leverages the power of these vector embeddings to index and search across a massive dataset of unstructured data and semi-structured data, such as images, text, or sensor data. Vector databases are built to manage vector embeddings, and therefore offer a complete solution for the management of unstructured and semi-structured data.
A vector database is different from a vector search library or vector index: it is a data management solution that enables metadata storage and filtering, is scalable, allows for dynamic data changes, performs backups, and offers security features.
A vector database organizes data through high-dimensional vectors. High-dimensional vectors contain hundreds of dimensions, and each dimension corresponds to a specific feature or property of the data object it represents.
What are vector embeddings?
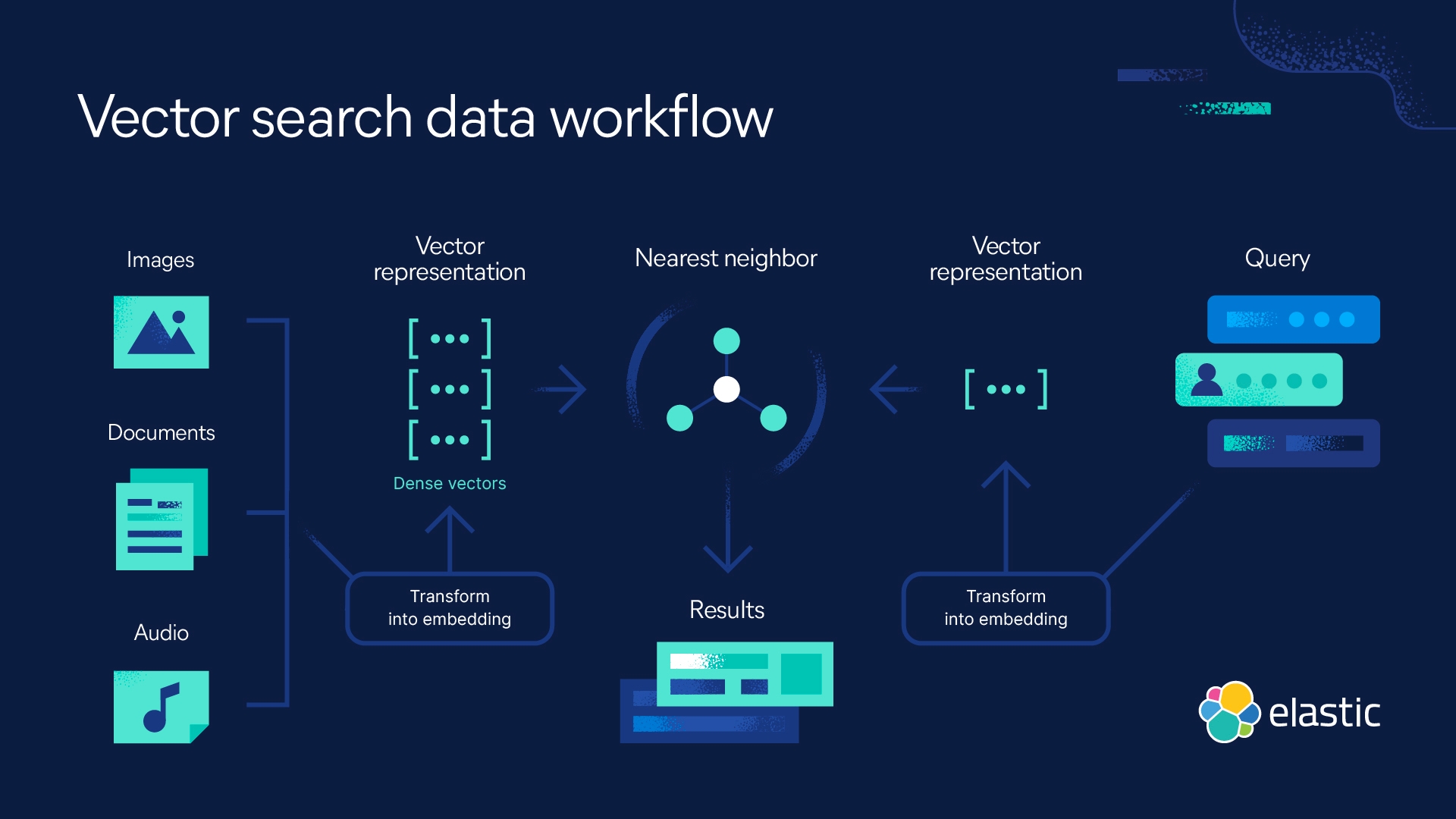
Vector embeddings are a numerical representation of a subject, word, image, or any other piece of data. Vector embeddings — also known as embeddings — are generated by large language models and other AI models.
The distance between each vector embedding is what enables a vector database, or a vector search engine, to determine the similarity between vectors. Distances may represent several dimensions of data objects, enabling machine learning and AI's understanding of patterns, relationships, and underlying structures.
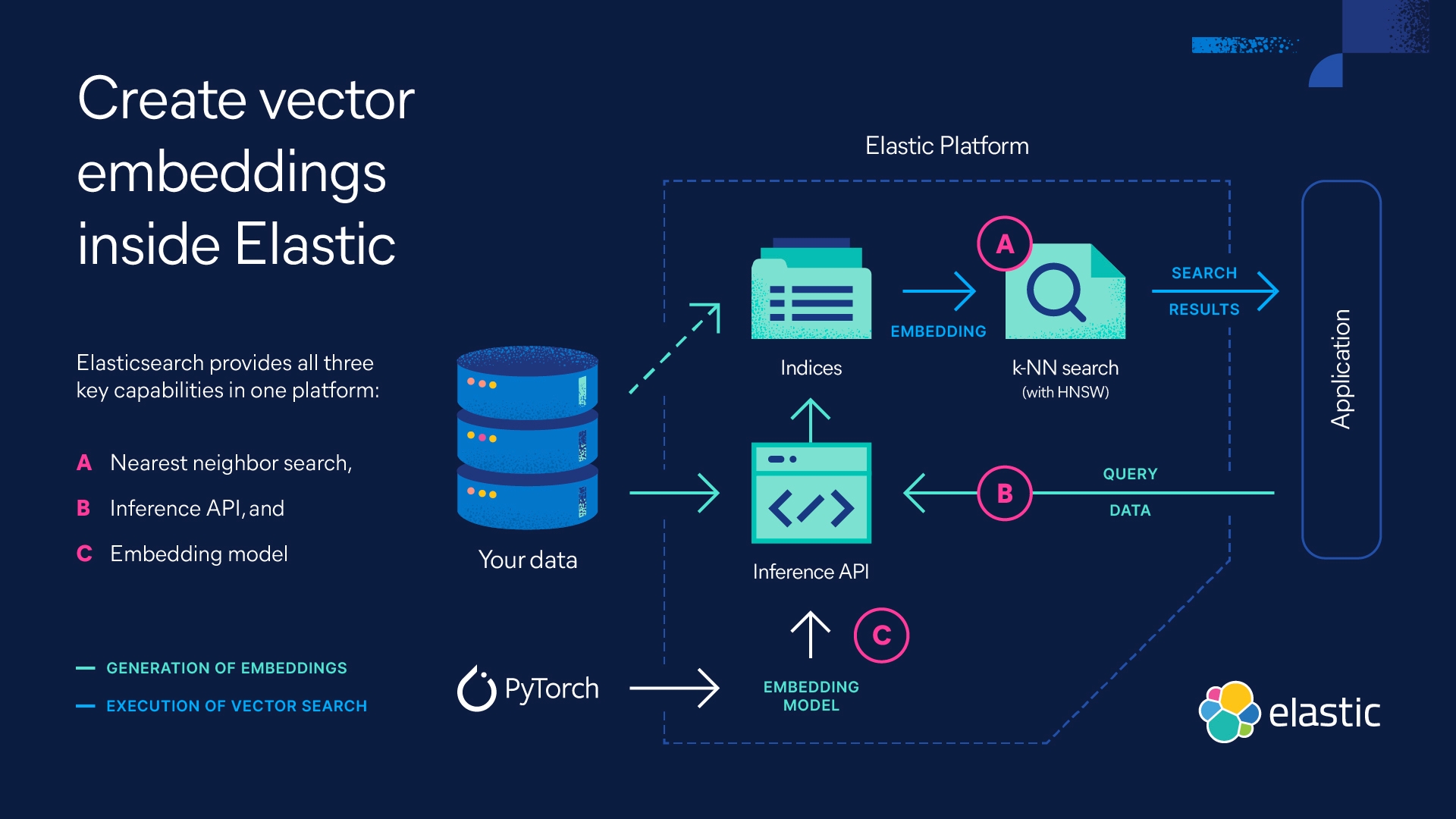
How does a vector database work?
A vector database works by using algorithms to index and query vector embeddings. The algorithms enable approximate nearest neighbor (ANN) search through hashing, quantization, or graph-based search.
To retrieve information, an ANN search finds a query’s nearest vector neighbor. Less computationally intensive than a kNN search (known nearest neighbor, or true k nearest neighbor algorithm), an approximate nearest neighbor search is also less accurate. However, it works efficiently and at scale for large datasets of high-dimensional vectors.
A vector database pipeline looks like this:
Indexing: Using hashing, quantization, or graph-based techniques, a vector database indexes vectors by mapping them to a given data structure. This enables a faster search.
- Hashing: A hashing algorithm, such as the locality-sensitive hashing (LSH) algorithm, is best suited to an approximate nearest neighbor search because it enables speedy results, and generates approximate results. LSH uses hash tables — think of a Sudoku puzzle — to map nearest neighbors. A query will be hashed into a table and then compared to a set of vectors in the same table to determine similarity.
- Quantization: A quantization technique, such as product quantization (PQ), will break up vectors into smaller parts and represent those parts with code, and then put the parts back together. The result is a code representation of a vector and its components. The ensemble of these codes is referred to as a codebook. When queried, a vector database that uses quantization will break the query down into code, and then match it against the codebook to find the most similar code to generate results.
- Graph-based: A graph algorithm, such as the Hierarchical Navigable Small World (HNSW) algorithm uses nodes to represent vectors. It clusters the nodes and draws lines or edges between similar nodes, creating hierarchical graphs. When a query is launched, the algorithm will navigate the graph hierarchy to find nodes containing the vectors that are most similar to the query vector.
A vector database will also index a data object's metadata. For this reason, a vector database will contain two indexes: a vector index and a metadata index.
Querying: When a vector database receives a query, it compares indexed vectors to the query vector to determine the nearest vector neighbors. To establish nearest neighbors, a vector database relies on mathematical methods known as similarity measures. Different types of similarity measures exist:
- Cosine similarity establishes similarity on a range of -1 to 1. By measuring the cosine of the angle between two vectors in a vector space, it determines vectors that are diametrically opposed (represented by -1), orthogonal (represented by 0), or identical (represented by 1).
- Euclidean distance determines similarity on a range of 0 to infinity by measuring the straight line distance between vectors. Identical vectors are represented by 0, while greater values represent a greater difference between vectors.
- Dot product similarity measures determine vector similarity on a range of minus infinity to infinity. By measuring the product of the magnitude of two vectors and the cosine of the angle between them, dot product assigns negative values to vectors that point away from each other, 0 to orthogonal vectors, and positive values to vectors that point in the same direction.
Post-processing: The final step in a vector database pipeline is sometimes post-processing, or post-filtering, during which the vector database will use a different similarity measure to re-rank the nearest neighbors. At this stage, the database will filter the query's nearest neighbors identified in the search based on their metadata.
Some vector databases may apply filters before running a vector search. In this case, it is referred to as preprocessing or pre-filtering.
Why are vector databases important?
Vector databases are important because they hold vector embeddings and enable a set of capabilities, including indexing, distance metrics, and similarity search. In other words, vector databases are specialized for the management of unstructured data and semi-structured data. As a result, vector databases are a vital tool in the machine learning and AI digital landscape.
Core components of vector databases
A vector database may have the following core components:
- Performance and fault tolerance: The processes of sharding and replication ensure that a vector database is performant and tolerant of faults. Sharding involves partitioning data across multiple nodes, while replication involves making several copies of data across different nodes. In case a node fails, this enables fault tolerance and continued performance.
- Monitoring capabilities: To ensure performance and fault tolerance, a vector database requires monitoring of resource usage, query performance, and overall system health.
- Access control capabilities: Vector databases also require data security management. Access control regulation ensures compliance, accountability, and the ability to audit database usage. This also means data is protected: It is accessed by those who have the permissions, and a record of user activity is kept.
- Scalability and tunability: Good access control capabilities impact the scalability and tunability of a vector database. As the amount of data stored increases, the ability to scale horizontally becomes mandatory. Different insert and query rates, as well as differences in underlying hardware, impact application needs.
- Multiple users and data isolation: In hand with scalability and access control capabilities, a vector database should accommodate multiple users or multi-tenancy. In concert with this, vector databases should enable data isolation so that any user activity (such as inserts, deletes, or queries) remains private to other users — unless otherwise required.
- Backups: Vector databases create regular data backups. This is a key component of a vector database in the case of a system failure — in the event of data loss or corruption of data, backups can help restore the database to a former state. This minimizes downtime.
- APIs and SDKs: A vector database uses APIs to enable a user-friendly interface. An API is an application programming interface, or a type of software, that enables applications to “talk” to each other via requests and responses. API layers simplify the vector search experience. SDKs, or software development kits, often wrap the APIs. They are the programming languages that the database uses to communicate and administer. SDKs contribute to a developer-friendly use of vector databases because they don’t have to worry about underlying structure when developing specific use cases (semantic search, recommendation systems, etc.).
What is the difference between a vector database and a traditional database?
A traditional database stores information in tabular form, and indexes data by assigning values to data points. When queried, a traditional database will return results that exactly match the query.
A vector database stores vectors in the form of embeddings and enables vector search, which returns query results based on similarity metrics (rather than exact matches). A vector database "steps up" where a traditional database cannot: It is intentionally designed to operate with vector embeddings.
A vector database is also better suited than a traditional database in certain applications, such as similarity search, artificial intelligence, and machine learning applications, because it enables high-dimensional search and customized indexing, and because it is scalable, flexible, and efficient.
Applications of vector databases
Vector databases are used in AI, machine learning (ML), natural language processing (NLP), and image recognition applications.
- AI/ML applications: A vector database can improve AI capabilities with semantic information retrieval and long-term memory.
- NLP applications: Vector similarity search, a key component of vector databases, is useful for natural language processing applications. A vector database can process text embeddings, which enables a computer to "understand" human — or natural — language.
- Image recognition and retrieval applications: Vector databases transform images into image embeddings. With similarity search, they are able to retrieve similar images or identify matching images.
Vector databases can also serve anomaly detection and face detection applications.
Learn how vector databases power AI search. Watch our webinar and discover how to build a modern search experience for your project.
Future trends in vector databases
The future of vector databases is intricately linked with the development of AI and ML, as well as research related to the use of deep learning to generate more powerful embeddings for structured and unstructured data1.
As the ability to create better embeddings improves, the ability of a vector database to better process and manage these embeddings requires new techniques and algorithms. In fact, new such methods are consistently in development.
Additional research is dedicated to the development of hybrid databases. These are intended to combine the power of traditional relational databases and vector databases as an answer to the growing need for efficient and scalable databases.
Vector database for elasticsearch
elasticsearch includes a vector database for vector search. Elastic enables developers to build their own vector search engines with the elasticsearch Relevance Engine (ESRE).
With elasticsearch tools, you can build a vector search engine that can search unstructured and structured data, apply filters and faceting, apply hybrid search over text and vector data, and make use of document and field level security, while running on-prem, in the cloud, or in hybrid environments.
Footnotes
1 Gu, Huaping. "Unleashing the Power of Vectors: Embeddings and Vector Databases - Linkedin." LinkedIn, 2 Apr. 2023, www.linkedin.com/pulse/unleashing-power-vectors-embeddings-vector-databases-huaping-gu