About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Develop Java programs to produce and consume messages to and from Apache Kafka
Use the Producer API and consumer API to interact with Kafka programmatically
On this page
Apache Kafka is an event streaming platform that helps developers implement an event-driven architecture. Rather than the point-to-point communication of REST APIs, Kafka's model is one of applications producing messages (events) to a pipeline and then those messages (events) can be consumed by consumers. Producers are unaware of who is consuming their data and how. Similarly, consumers can consume messages at any point from the queue and are not tied to producers. This architecture leads to the decoupling between producers and consumers that event driven architecture relies on.
The quickstart provided on the Kafka website does an excellent job of explaining how the different components of Kafka work by interacting with it manually by running shell scripts in the command line. In this tutorial, I give an overview of how to interact with Kafka programmatically using the Kafka producer and consumer APIs.
Learning objectives
The objective of this tutorial is to demonstrate how to write Java programs to produce and consume messages to and from Apache Kafka. Because creating and maintaining a Kafka cluster can require quite an investment of time and computational power, I'll demonstrate IBM Event Streams on IBM cloud, which is a fully managed Kafka instance.
After completing this tutorial, you will understand:
- What Apache Kafka is
- How to produce messages to Kafka programmatically
- How to consumer messages from Kafka programmatically
- What IBM Event Streams is
- How to set up a Kafka cluster using IBM Event Streams
Prerequistes
- General knowledge about Apache Kafka
- An IBM cloud account
Key Kafka concepts
Before we begin, let's review some of the key Kafka concepts.
Events are stored in topics, and topics are further broken down into partitions. Although logically speaking a topic can be seen as a stream of records, in practice a topic is composed of a number of partitions. The records in a topic are distributed across its partitions in order to increase throughput, which means that consumers can read from multiple partitions in parallel.
Records in a partition are reference by a unique ID called an offset. A consumer can consume records beginning from any offset. Also, a tuple (topic, partition, offset) can be used to reference any record in the Kafka cluster.
In Kafka, producers are applications that write messages to a topic and consumers are applications that read records from a topic.
Kafka provides 2 APIs to communicate with your Kafka cluster though your code:
- The producer API can produce events.
- The consumer API can consume events.
The producer and consumer APIs were originally written for Java applications, but since then APIs for many more languages have been made available including (but not limited to) c/c++, Go, and Python.
In this tutorial, we cover the simplest case of a Kafka implementation with a single producer and a single consumer writing messages to and reading messages from a single topic. In a production environment, you will likely have multiple Kafka brokers, producers, and consumer groups. This is what makes Kafka a powerful technology for implementing an event-driven architecture.
Steps
This tutorial is broadly segmented into 3 main steps. First, you'll create a Kafka cluster. As mentioned earlier, we will be using the Event Streams service on IBM cloud for this. Next, you'll write a Java program that can produce messages to our Kafka cluster. Finally, you'll write a consumer application that can read those same messages.
Both the producing and consuming applications are written in Java, so they can be run from within an IDE. I will be using Eclipse, but any IDE should be fine.
Step 1: Deploy a basic Kafka instance with IBM Event Streams on IBM cloud
While it is easy to get Kafka running on your machine for experimentation using the Apache Kafka quickstart, managing a Kafka cluster with multiple servers in production can be quite cumbersome. IBM Event Streams on IBM cloud is a managed Kafka service that allows developers to create Kafka clusters without having to worry about provisioning and maintaining a Kafka cluster.
To get started using IBM Event Streams on IBM cloud, you can follow the getting started documentation or you can follow along in this video tutorial on IBM Developer.
To allow your Java applications to access your topic, you'll need the credentials and API key for this service. Make sure to note these values which you use later in this tutorial.
Step 2: creating a producer application using the Kafka Producer API
First, you need to create a Java project in your preferred IDE. Then, download the latest version of the Apache Kafka clients from the Maven repository to add to your maven project.
Start by importing the required packages:
import java.util.Properties;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.*;
Next, create a Java properties object (producerProps in this case) and store all the properties of the producer in that object. These properties include our Kafka brokers, the security parameters to connect to Event Streams, and the key and value serializers for serializing our messages before sending them to Kafka.
A list of Kafka brokers can be found in the service credentials we created while creating our Event Streams cluster.
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", "broker-5-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093, "
+ "broker-2-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093, "
+ "broker-4-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093, "
+ "broker-1-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093, "
+ "broker-0-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093, "
+ "broker-3-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093");
Next, provide the SASL credentials to be able to connect to Event Streams. Make sure to replace USERNAME and PASSWORD with the values you noted for your service credentials in step 1.
producerProps.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"USERNAME\" password=\"PASSWORD\";");
producerProps.put("security.protocol", "SASL_SSL");
producerProps.put("sasl.mechanism", "PLAIN");
producerProps.put("ssl.protocol", "TLSv1.2");
producerProps.put("ssl.enabled.protocols", "TLSv1.2");
producerProps.put("ssl.endpoint.identification.algorithm", "HTTPS");
Finally, specify a key and value serializer for serializing the messages before sending them to Kafka. The "acks" parameter specifies when a request is considered complete. Setting it to "all" results in blocking on the full commit of a record.
producerProps.put("acks", "all");
producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Once we've set all our properties, we can begin producing events. I'll run a loop for 1000 iterations, producing the iteration number every 5 seconds.
Producer<String, String> producer = new KafkaProducer<>(producerProps);
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<String, String>("getting-started", Integer.toString(i), Integer.toString(i)));
Thread.sleep(5000);
}
producer.close();
When we are done producing messages, we can close our producer by calling producer.close().
We can simply run the code from within our IDE.
Running this code should start writing events to Kafka. You might get an error that looks like this:
Error! Filename not specified.
You can ignore this message for now.
We now have a producer that's writing messages to a Kafka topic. Now, let's create a consumer that can read those messages.
Step 3: creating a consumer application using the Kafka consumer API
Similar to the producer, to create a consumer, we first have to specify its properties.
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "broker-5-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093,"
+ "broker-2-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093,"
+ "broker-4-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093,"
+ "broker-1-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093,"
+ "broker-0-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093,"
+ "broker-3-rgtvthnhvdqfxgjw.kafka.svc06.us-south.eventstreams.cloud.ibm.com:9093");
consumerProps.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"token\" password=\"oZ17lr1q6tH52OrnJ913uU_XGhSn0MAMpHj5nOEqgFaN\";");
consumerProps.put("security.protocol", "SASL_SSL");
consumerProps.put("sasl.mechanism", "PLAIN");
consumerProps.put("ssl.protocol", "TLSv1.2");
consumerProps.put("ssl.enabled.protocols", "TLSv1.2");
consumerProps.put("ssl.endpoint.identification.algorithm", "HTTPS");
consumerProps.put("group.id", "KafkaExampleconsumer");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
We will use a Kafkaconsumer to consume messages, where each message is represented by a consumerRecord. Every consumer belongs to a consumer group. We will place our consumer in a group called G1. Once that is done, we can subscribe to a list of topics. Next, call poll() in a loop, receiving a batch of messages to process, where each message is represented by a consumerRecord.
consumerProps.put("group.id", "G1");
consumer<String, String> consumer = new Kafkaconsumer<>(consumerProps);
consumer.subscribe(Arrays.asList("getting-started"));
while (true) {
consumerRecords<String, String> records = consumer.poll(100);
for (consumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
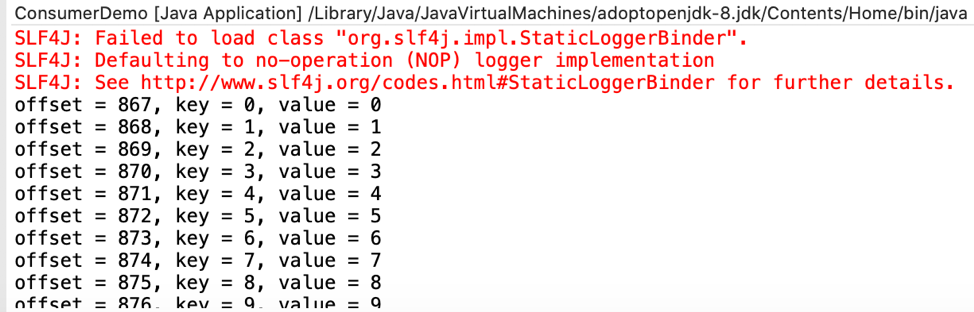
This consumer gets messages from the “getting-started” topic in our Kafka cluster and prints them to the console. You can run this code from within the IDE similar to how we ran the producer code. When it is run, it should display an output like this:
Summary and next steps
In this tutorial, you provisioned a managed Kafka cluster using IBM Event Streams on IBM cloud. Then, you used that cluster to produce and consume records using the Java producer and consumer APIs.
Besides the producer and consumer APIs, you might find these two Kafka APIs useful:
When the input and output data sources for your application are Kafka clusters, consider using the Kafka Streams API. Try this tutorial, "Developing a stream processor with Apache Kafka."
If you want to connect to an external data source, consider using the Kafka connect API.