About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Extracting, classifying, and summarizing documents using LLMs
Building a generative AI form filling tool
On this page
To build a generative AI form filling tool, you can use a large language model (LLM) to extract, classify and summarize documents. In this tutorial, we walk you through a sample application that applies these techniques to a recipe website.
For this example, we used three main AI tools to perform the tasks: Docling, watsonx.ai, and Langchain.
- Docling: An IBM open source tool that is used to parse any form of document. In our case, we used it to convert HTML and PDF documents to a more LLM-friendly format like Markdown.
- Watsonx.ai: An enterprise-grade studio for developing AI services and deploying them into your applications. Many developers also use Ollama to run and serve models locally for testing until the application is production ready.
- Langchain: A software framework that helps facilitate the integration of LLMs into applications. Some other examples of generative AI frameworks include BeeAI and Llamaindex.
Document processing techniques
In this section, we explore some of the techniques and other concepts to keep in mind when building a generative AI form filling tool. We will also provide some prompts and code that we used in our sample application that demonstrates these techniques.
Context documents
The goal of a form application is to allow users to input information they possess, into a set of fields that map to the structure of a data schema. The source of this data is usually an unstructured document, or set of documents, that contain all the information needed to fill out the form fields. These documents can come in the form of:
- PDFs
- Microsoft Word documents
- Microsoft Excel spreadsheets
- Web pages
- And many more
Throughout this tutorial, we refer to these documents as our context documents. If the users of your application have these documents, then your application is likely a good candidate for AI form filling.
File Parsing
In our sample application, we use Docling to parse user uploaded documents or web pages into Markdown. Converting these documents into Markdown makes it easier for the LLM to understand the content. The following code is used to perform the file parsing in our app:
# create document converter
converter = DocumentConverter()
# get file from document stream
recipe = DocumentStream(name=upload_file.filename, stream=bytes_file)
# convert document
result = converter.convert(recipe)
...
# export to markdown
markdown_recipe = result.document.export_to_markdown()
You can also use Docling to to parse web pages as well:
# create document converter
converter = DocumentConverter()
# convert web page
result = converter.convert(body.url)
...
# export to markdown
markdown_recipe = result.document.export_to_markdown()
Constrained generation
Since FastAPI needs to return the response from our LLM to the client in a structured format, we need to constrain the LLM's output to a JSON schema. To do this, we use Pydantic for schema generation and Langchain's JsonOutputParser to create the format instructions for our prompt.
# create schema
class Recipe(BaseModel):
author: str = Field(description="primary author of the recipe")
title: str = Field(description="exact title of the document")
publicationDate: str = Field(
description="Date of recipe publication in the format mm/dd/yyyy"
)
ingredients: list[str] = Field(
description="The ingrediants found in the recipe document needed to cook the meal"
)
steps: list[str] = Field(
description="The steps found in the recipe document you need to follow in order to cook the meal"
)
...
# generate format instructions
def get_format_instructions(self, pydantic_object):
parser = JsonOutputParser(pydantic_object=pydantic_object)
return parser.get_format_instructions()
We will use the output of parser.get_format_instructions() in each of our prompts that require the output of the LLM to be constrained to JSON.
Extraction
The first type of prompt we will use to generate data that populates our form is an extraction prompt. The goal of this prompt is to instruct the LLM to extract information from the context we provide it. The following prompt is the one we used to extract recipe info from our context document:
You are culinary expert, extract the following details from the provided recipe text and present them in the specified structured json output format below.
You should only extract the title, primary author, steps, and the ingredients from the provided recipe.
Include only the information explicitly stated in the recipe, and leave fields blank if the information is not provided.
Do not infer or add details beyond what is given. Only return the final json output.
Json Output Format
----------------------
{}
----------------------
Recipe Info:
------------
{}
------------
RECIPE JSON:
Notice the two {} in our prompt. The first will be replaced by our formatting instructions from the previous section and the second will be replaced by the documents we parsed using Docling.
To call the model using this prompt, we have defined the following inference method in our LLM service:
def inference(self, human_prompt):
messages = [HumanMessage(human_prompt)]
return self.llm.invoke(messages).content
This simply takes the human prompt we defined above and calls the invoke method on the Langachain chat model abstraction for watsonx.ai.
Classification
Another technique you can use with LLMs is classification. This approach has the model classify some context into a single class chosen from a discrete set of classes. In our sample application, we attempt to have the model classify the recipe's cuisine.
You are a culinary expert tasked with identifying the cuisine type of a recipe based on its ingredients, preparation methods, and cultural characteristics.
Given the recipe below, classify the cuisine as one of the following (if no clear cuisine can be inferred, default to Other):
ID: 1 Name: American
ID: 2 Name: Italian
ID: 3 Name: Asian
ID: 4 Name: Spanish
ID: 5 Name: Other
Json Output Format
----------------------
{}
----------------------
Recipe Info:
------------
{}
------------
CUISINE:
We again add the context documents and formatting instructions to this prompt and pass it to our inference function which should return a single cuisine.
Summarization
The last LLM specific technique we used in this application is summarization. By default, Langchain provides these techniques for summarization:
- Stuff: Summarizes using the entire context without splitting.
- Map Reduce: Splits the context, performs summarization on the individual splits in parallel, and then summarizes the individual summarizations.
- Refine: Iterates over the split context and sequentially refines the summary.
Since we expect our documents to fit within the effective context length of our model we went with the stuff approach.
Below is the summarization method we used in our LLM service that leverages Langchain's pre-built load_summarize_chain.
def summarization(self, text, type, config):
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=250)
docs_summary = splitter.create_documents([text])
summarize_chain = load_summarize_chain(self.llm, type, verbose=True)
return summarize_chain.invoke(docs_summary, config)["output_text"]
For an extremely large set of context documents it may make sense to first split, embed, and retrieve documents from a vector database before passing them to the LLM. This technique is known as retrieval augmented generation (RAG). You can learn more about this technique in this tutorial.
Evaluation
It's always a good idea to try to evaluate the output of applications that leverage generative AI. For a simple use case like ours, it might be sufficient to check to see if outputs from the model match information stored in the context documents. If you have a set of already filled out forms by your users, you can take the output of the model for some of those and compare the results.
If you are evaluating the effectiveness of summarizations, you could take a set of human-generated summarizations and compare them using cosine similarity, BLEU, or ROUGE score. You can even use another LLM to compare the original summary to the generated summarization.
Walkthrough of our sample application
This walkthrough will demonstrate how to extract, classify, and summarize using the Granite 3.2 model with watsonx.ai.
First clone the project's repo.
In the root directory of the projects repo, you will see the client folder that contains the files for a simple frontend app, and the server folder that contains the files to serve the AI service.
Running the frontend application
Before starting the sample app, make sure you have node v22.14.0 installed and nvm to easily switch node versions.
- To begin, open a new terminal and navigate to the client folder:
cd client. - Install/Use the npm version for the project:
nvm install&nvm use. - Install the packages
npm ci. - Run the frontend
npm run dev. - Visit
http://localhost:5173/to test the web interface.
Running the backend application
First, you need to install Python and create a virtual environment:
- In a separate terminal install pyenv
- Install python 3.12 with pyenv:
pyenv install 3.12 - Create a virtual environment with the newly installed python version:
pyenv virtualenv 3.12 form-ai-test
Then, you need to export the following environment variables:
export WATSONX_PROJECT_ID={YOUR_PROJECT_ID}export WATSONX_APIKEY={YOUR_API_KEY}
Finally, you can run the backend app:
- In a new terminal, change directory to the server
cd server. - Activate the python virtual environment that was just created:
pyenv activate form-ai-test. - Install packages:
pip install -r requirements.txt. - Run the server:
fastapi run main.py.
Form Filling Example
To test the sample app, complete these steps:
- Find a recipe you would like to use. For example,
https://www.delish.com/cooking/recipe-ideas/a51451/easy-chicken-parmesan-recipe/. - Export the recipe as a PDF file.
In a separate tab navigate to
http://localhost:5173/.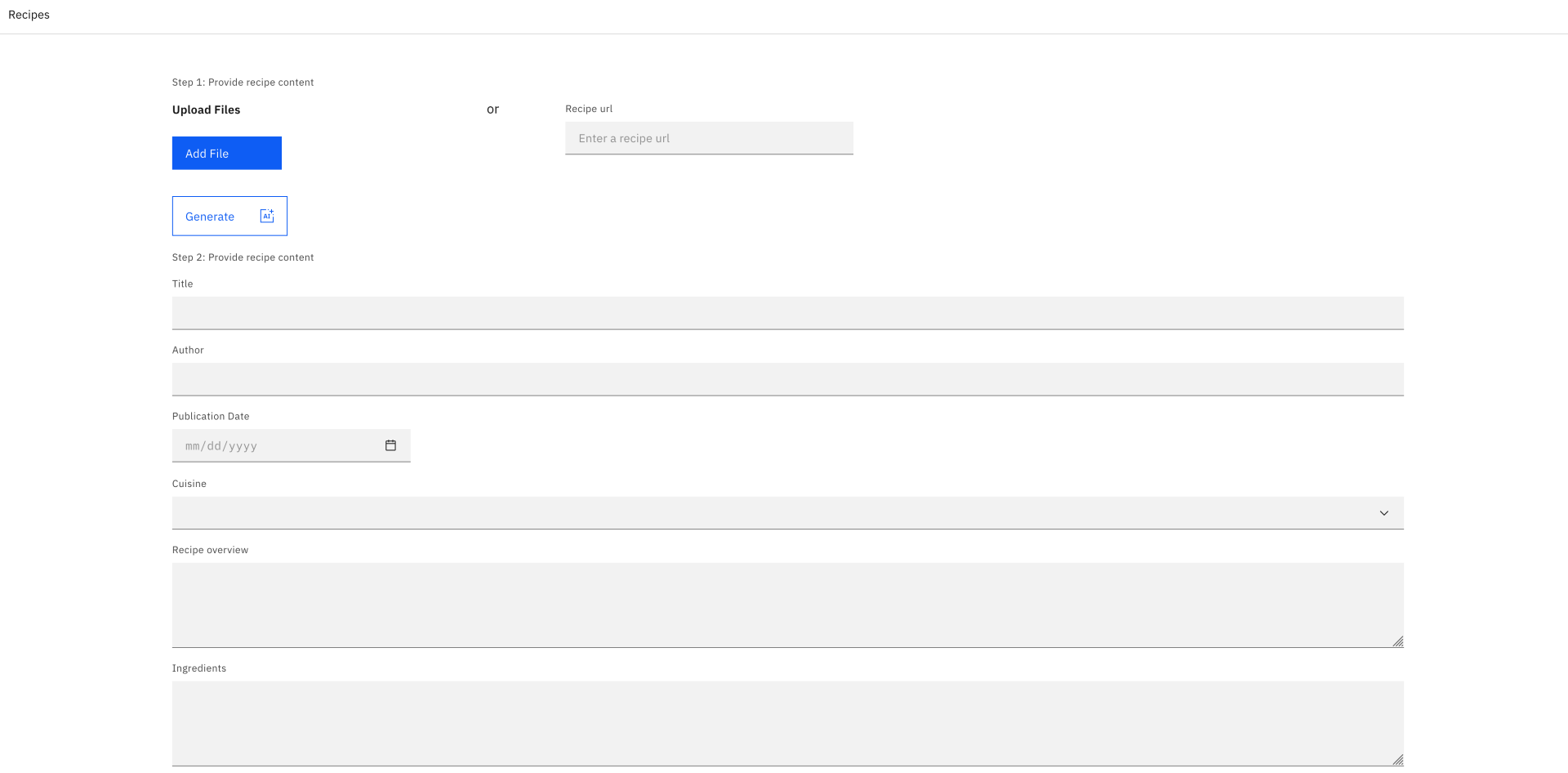
Select Add File, and then select the PDF version of the recipe you just saved.
- Once added, select Generate, and wait for the LLM to return your request. In the background, the server is converting the PDF to Markdown and sending the prompt (shown earlier in the "Techniques" section) to the LLM service. This load time can vary based on the PDF you added.
- When the result has been returned and all the fields have been filled out, you can try again using the URL to see if you get similar results. Either remove the file or refresh the page, then insert the URL of the recipe and select Generate. Wait to see what the LLM returns.
Summary and next steps
In this tutorial, we showed you the tools and techniques needed to build an AI-powered form filling tool for your applications. We also showed a working example of a form filling tool that extracts recipe information from a webpage or a PDF file.
With an understanding of these concepts, you should now be able to create your own generative AI tools for your applications which can be used to increase the productivity of your users.
Explore more articles and tutorials on generative AI tools and techniques on IBM Developer.