About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Build a scalable analytics pipeline with IBM watsonx.data, Apache Spark, and open table formats
Complete an e-commerce conceptual use case to leverage your data and make better business decisions
On this page
Note: This tutorial uses an e-commerce scenario as a conceptual model to help illustrate how to design an analytics architecture using watsonx.data, Apache Spark, and open table formats. It does not represent a full e-commerce platform implementation.
In today’s digital economy, e-commerce platforms must continuously evolve to meet the growing demands of both customers and businesses. To stay competitive, companies need to optimize their platforms for efficiency, scalability, and performance. Advanced data solutions are key to achieving these objectives.
In this tutorial, you’ll walk through an e-commerce scenario using IBM watsonx.data and Apache Spark within the medallion architecture. Spark ensures scalable data processing with open table formats (OTF) for flexibility, while watsonx.data provides a robust data foundation. Additionally, we will touch on how IBM Cognos Analytics can be leveraged to create reports and dashboards using Gold layer data.
A setup such as this can empower your business to leverage data for better decision-making and enhanced customer experiences.
IBM watsonx.data architecture
The IBM watsonx.data architecture is purpose-built to enable scalable, efficient, and cost-effective data management for modern workloads. It comprises three key layers.
- Storage layer: The storage layer leverages low-cost object storage solutions, offering flexibility and scalability for storing large volumes of data. watsonx.data supports any S3-compatible storage, ensuring compatibility with popular cloud and on-premise solutions.
- Engines layer: watsonx.data integrates powerful compute engines, such as Apache Spark and Presto, which come native to the platform. Additionally, it supports Spark IAE (Integrated Analytics Engine) for enhanced processing. Beyond native engines, the architecture also supports other engines that can access the open storage buckets, providing flexibility for running diverse analytics workloads.
- Metadata layer: Moving further up the stack, the metadata store plays a critical role in the watsonx.data lakehouse architecture. It ensures that all query engines have a consistent view of the data being managed in the lakehouse storage. The metadata layer enables the implementation of open table formats that drive transactional consistency, schema evolution, and data versioning.
Open table formats as catalogs
IBM watsonx.data supports three widely adopted open table formats to enhance flexibility and interoperability across analytics engines:
- Delta Lake: Offering ACID transactions, schema enforcement, and the ability to handle both batch and streaming data seamlessly.
- Apache Hudi: Focused on managing large-scale data, Hudi enables incremental updates and supports data mutation capabilities, making it ideal for e-commerce scenarios.
- Apache Iceberg: Designed for handling petabyte-scale datasets, Iceberg provides advanced schema evolution, time travel, and partitioning flexibility.
These open table formats act as catalogs within the metadata layer, enabling robust management and efficient query execution across diverse engines and workloads.
Medallion architecture
The medallion architecture is a data design pattern used in lakehouse environments to progressively refine raw data through multiple layers, ensuring better quality and usability. The layers include:
- Bronze: Raw data storage
- Silver: Cleaned and enriched data
- Gold: Aggregated, analytics-ready data
Why integrate in a unified platform?
The watsonx.data lakehouse takes advantage of the combined strengths of Delta Lake, Apache Hudi, and Apache Iceberg to address diverse business needs efficiently. For example:
- In e-commerce, Delta Lake enables real-time inventory updates, Hudi supports efficient customer behaviour tracking, and Iceberg powers sales trend analysis and forecasting for deeper insights.
- In financial services, Delta Lake ensures real-time fraud detection, Hudi manages incremental portfolio updates, and Iceberg secures compliance reporting with scalable governance.
- In healthcare, Delta Lake facilitates timely predictive analytics, Hudi synchronizes patient records, and Iceberg handles long-term storage for audits.
By combining these open table formats, businesses can seamlessly manage real-time operations, process incremental updates, and ensure scalable, compliant analytics—all within a single, unified lakehouse platform.
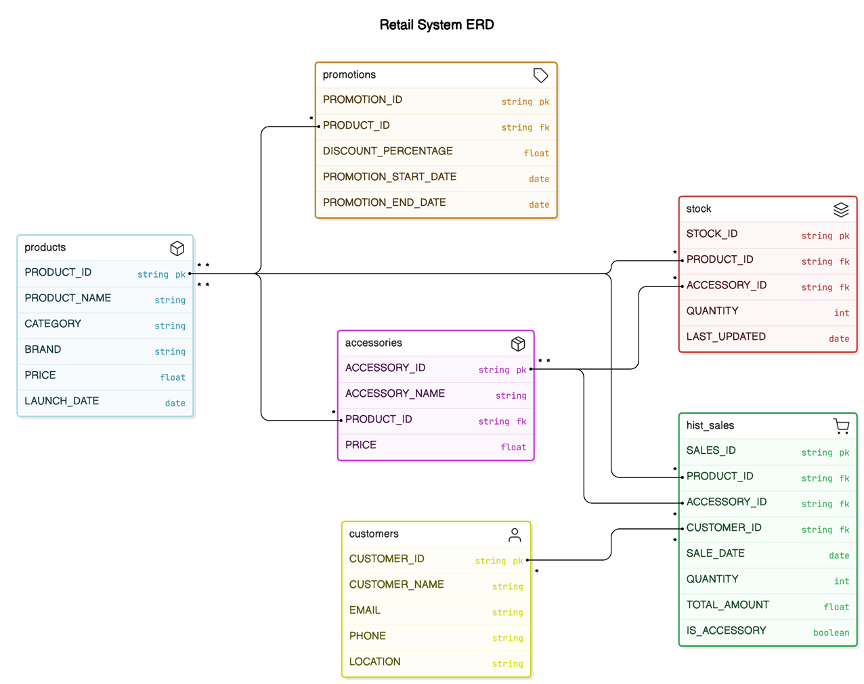
Entity relationship diagram
This entity relationship diagram illustrates the retail system's data structure, showing key entities and their relationships for better data organization.
Reference architecture
The following diagram shows the architecture for the e-commerce use case that we will implement:
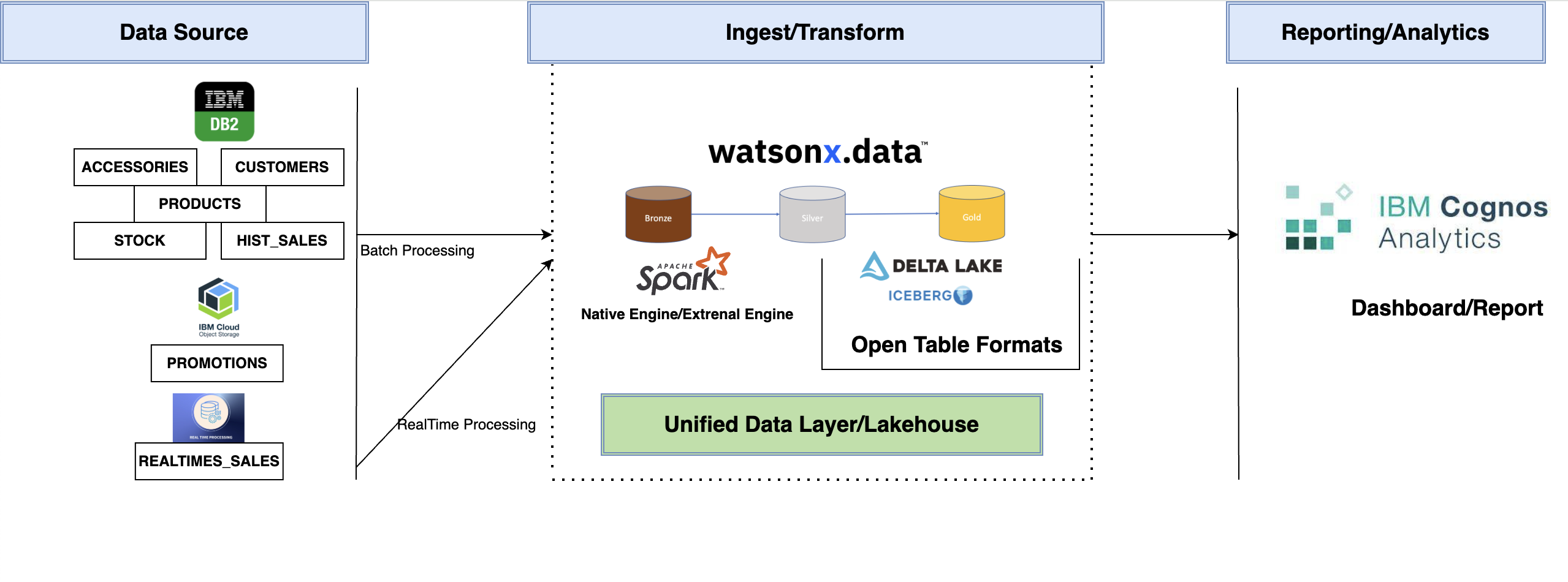
The ingestion, transformation, and processing activities shown here occur within the central data layer, where watsonx.data and open table formats like Delta Lake and Iceberg facilitate data management.
- Data ingestion
- Real-time: Ingest web and app interactions into Delta Lake using watsonx.data.
- Batch: Import historical data periodically into Iceberg.
- Real-time processing:
- Apache Spark on watsonx.data joins Product, Sales, and Customer tables for real-time queries like product recommendations and marketing.
- Federated queries:
- Combines real-time sales data from Delta Lake with historical data from Iceberg to provide insights on trends and customer behavior.
Prerequisites
Before completing the steps to implement the use case, be sure that you have:
- IBM Db2
- IBM watsonx.data
- Two catalogs with an IBM Cloud Object Storage bucket
- Any s3 compatible object storage, such as IBM Cloud Object Storage or AWS S3 Object Storage (this tutorial uses IBM Cloud Object Storage)
- Apache Spark set up with watsonx.data
- IBM Cognos Analytics (not required, but useful)
Steps
Step 1: Set up the database instance
You require an active IBM Db2 instance to complete this tutorial. Download the source files from this GitHub repository to create the required Db2 tables. Be sure to check that you maintain the proper table structures and data integrity when importing the source data.
Step 2: Set up IBM Cloud Object Storage
You'll need IBM Cloud Object Storage for this workflow.
- Create two folders in your Cloud Object Storage bucket:
sparkdb2-target: Stores Apache Iceberg data and the required promotions_sale.csv file.spark-dl: Stores Delta Lake data.
- Optional: If you use different folder names, remember to update the names in the code.
- After uploading
promotions_sale.csvtosparkdb2-target, verify its file path for reference in the code.
Step 3: Configure watsonx.data storage integration
You now need to set up a watsonx.data instance that uses your IBM Cloud Object Storage bucket.
- Create two storage-catalog pairs in watsonx.data:
a. Iceberg catalog: Link to
sparkdb2-target. b. Delta Lake Catalog: Link tospark-dl. - To integrate with Cloud Object Storage, ensure the Cloud Object Storage bucket and folders are correctly configured. Update catalog configurations if you used different folder names.
For detailed steps on setting up storage-catalog pairs, refer to the watsonx.data documentation. This setup ensures seamless integration for managing Iceberg and Delta Lake datasets.
To run Spark workloads in watsonx.data, set up one of the following:
- Native Spark engine: Provisioned within watsonx.data for high-performance processing.
- IBM Analytics engine: A serverless Spark environment for lightweight jobs.
- Watson Studio notebooks: Interactive Python/Scala notebooks for development.
- Command-line execution: Run Spark scripts externally and submit using an API.
Note: Watson Studio notebooks simplifies Spark integration with watsonx.data and open table formats and can be the easiest option. Ensure source file paths and storage locations are correctly configured.
Step 4: Run data processing workflows (Iceberg and Delta Lake federation)
Now that you’ve configured IBM Cloud Object Storage and watsonx.data, you can run the data processing workflows. You will first download and then run the following set of scripts.
You can run these scripts sequentially in a Jupyter Notebook or as standalone .py scripts using CURL and Spark submit options. The scripts can be stored in Cloud Object Storage and run using their respective URLs, depending on the engine that you have used.
Note that the medallion architecture structures your data pipeline.
You will run the following scripts sequentially from a Jupyter Notebook using Watson Studio or, alternatively, you can submit the .py scripts using Spark in two ways:
- For a watsonx.data native Spark engine
- For an external Spark engine (for example, IBM Analytics Engine, Watson Studio, or a self-managed Spark cluster)
Complete the following steps:
- Load data into Iceberg using the following script: Iceberg Data Load file. Note: This script loads data into Iceberg tables across the medallion architecture's Bronze, Silver, and Gold layers.
- Ingest data into Delta Lake using the following script: Real-time Delta Load file. Note: This script handles real-time ingestion of sales data into the Bronze layer of Delta Lake.
- Federate Delta Lake and Iceberg using the following script: Delta-Iceberg Federation file.
When you have run the scripts, you can validate the data in watsonx.data to ensure successful ingestion and transformation. For complete scripts, check the GitHub repository.
Step 5: Optional: Integrate IBM Cognos Analytics and watsonx.data to perform analysis
To perform analysis on your data, you can integrate IBM Cognos Analytics with watsonx.data. Although the integration steps are beyond the scope of this tutorial, you can see the Cognos Analytics documentation for details. Following are the high-level steps:
- Configure Cognos to access Gold layer tables in watsonx.data for analysis.
- Once connected, pull data (sales, inventory, customer behaviour) directly from watsonx.data.
- Build dashboards in Cognos using Gold layer data to track business performance.
Summary
In this tutorial, you’ve learned how to design a scalable data architecture by integrating IBM watsonx.data and open data formats, with Apache Spark enabling efficient, large-scale data processing. You’ve seen how open table formats like Iceberg and Delta Lake provide flexibility for managing and querying vast datasets.
Although IBM Cognos Analytics is used in this tutorial to generate reports and dashboards from the Gold layer data in watsonx.data, it is just one example of how the architecture can be extended. You can integrate other front-end solutions, such as custom applications or APIs, to meet your specific business needs.
This setup empowers businesses to leverage their data for enhanced decision-making and improved customer experiences while remaining adaptable to future integrations.
Now that you understand how to set up your e-commerce platform with IBM watsonx.data and open data formats, you can continue to build your knowledge and skills with these additional resources: