About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Fine-tune a Granite model using InstructLab
Create a specialized LLM using InstructLab
On this page
To adapt pre-trained LLMs to align with specific business objectives or to comprehend specialized knowledge domains and skills, organizations must fine-tune the LLMs. The fine-tuning process involves creating a derivative version of an existing open huge model, which requires significant computational resources (GPU-based hardware) and extensive training efforts.
Modifying LLMs has inherent limitations. Once a derivative model is created through fine-tuning, there is no straightforward mechanism to integrate these improvements back into the original open-source model repository. Consequently, this lack of integration prevents ongoing community-driven enhancements, limiting the potential for collective advancements in LLM capabilities. Moreover, refining LLMs traditionally relies heavily on large volumes of human-generated accurate data, a process that is both time-consuming and costly to acquire, further constraining widespread accessibility and adoption.
Earlier this year, IBM and RedHat introduced InstructLab, which eliminates the dependency on GPUs by enabling localized training. InstructLab significantly reduces the reliance on human-generated data and computational resources compared to conventional model retraining approaches. Furthermore, InstructLab facilitates continuous enhancement of the model through upstream contributions, ensuring ongoing refinement and optimization over time.
The key processes of InstructLab include taxonomy-driven data curation, large-scale synthetic data generation, and large-scale alignment tuning. The fine-tuned LLM results in a deflated quantized model that can be trained on synthetic data on a local machine. To learn more about InstructLab, read the article, “What is InstructLab and why do developers need it?” and watch some of the great videos from the InstructLab community.
In this tutorial, you’ll learn how to fine tune the IBM Granite LLM to create a specialized LLM.
Prerequisites
- Apple Mac M1/M2/M3 processors or Linux systems
- C++ compiler
- Python 3.10 or Python 3.11
- Approximately 60GB disk space
Steps
Step 1. Install and set up InstructLab
Create a directory and change to that directory:
mkdir instructlab cd instructlabInstall InstructLab using these commands:
python3 -m venv --upgrade-deps venv source venv/bin/activate pip cache remove llama_cpp_python pip install instructlabInitialize the InstructLab CLI:
ilab config initWhen prompted by the interface, press Enter to add a new default config.yaml file.
When prompted, clone the
https://github.com/instructlab/taxonomy.gitrepository into the current directory by typing “y”.
Step 2. Download the Granite model
By default, the “ilab model download” command downloads a compact pre-trained version of the merlinite-7b-lab model from HuggingFace and stores it in a “models” directory.
Follow these steps to download the granite-7b-lab model:
Download the IBM Granite model from the instructlab repository:
ilab model download --repository=instructlab/granite-7b-labDownload the granite-7b-lab-Q4_K_M.gguf model file:
ilab model download --repository=instructlab/granite-7b-lab-GGUF --filename=granite-7b-lab-Q4_K_M.gguf
Step 3. Serve and test the granite model
To test the model, you need to serve it and then chat with the model.
Serve the granite model by using this command:
ilab model serve --model-path models/granite-7b-lab-Q4_K_M.gguf `
Open a new terminal window, and then activate the python virtual environment using this command.
cd instructlab source venv/bin/activate `Chat with the granite model by using this command:
ilab model chat --model models/granite-7b-lab-Q4_K_M.gguf
Try asking a question, such as one of the following:
- What is PCI DSS?
- What are the recommended practices for securing payment systems against common security threats?
Step 4. Creating new knowledge
Create the qna.yaml file, MD files in a GitHub repo, and an attribution.txt file for your knowledge submission. Learn more in the InstructLab taxonomy documentation.
See this sample qna.yaml in our GitHub repo that we created for this tutorial.
List and validate the new data:
ilab taxonomy diff

Step 5.Generate synthetic data
Before generating the synthetic data, you need to download the merlinite model:
ilab model downloadThen, serve the merlinite model:
ilab serve --model-path models/merlinite-7b-lab-Q4_K_M.ggufFinally, generate synthetic data:
ilab data generate
Step 6. Train the model
Train the granite model:
ilab model train --model-dir instructlab/granite-7b-lab --tokenizer-dir instructlab/granite-7b-lab --model-name instructlab/granite-7b-lab
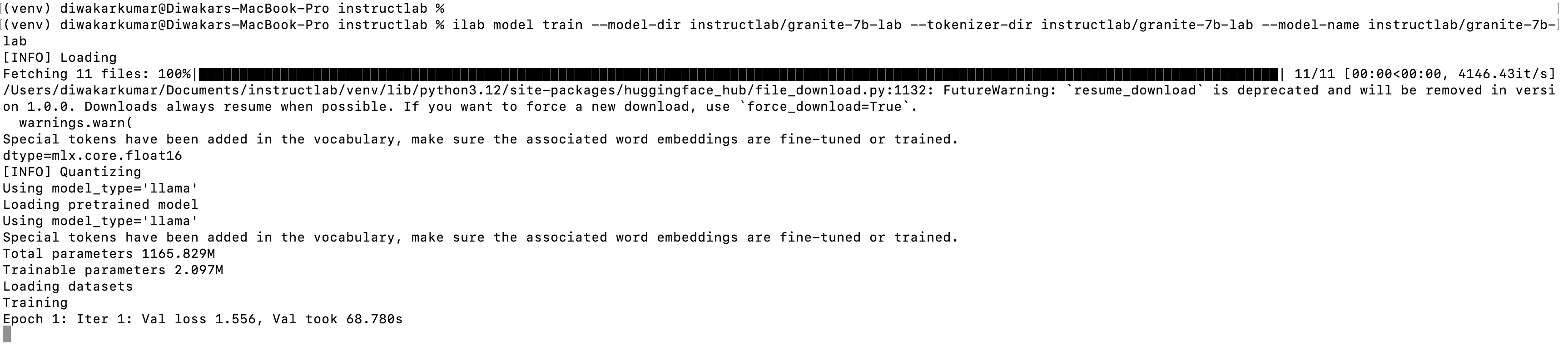
Step 7. Test the trained granite-7b model
Test the granite model:
ilab model test --model-dir instructlab-granite-7b-lab-mlx-q

Step 8. Convert the model to GGUF format
The trained model needs to be converted to quantized GGUF format which is required by the server to host the model in the ilab model serve command. The mlx-q directory gets deleted after running the convert command.
Convert the granite model:
ilab model convert --model-dir instructlab-granite-7b-lab-mlx-q

Step 9. Serve and test the trained model
Serve the trained model:
ilab model serve --model-path instructlab-granite-7b-lab-trained/instructlab-granite-7b-lab-Q4_K_M.gguf

Chat with the trained model:
ilab model chat -m instructlab-granite-7b-lab-trained/instructlab-granite-7b-lab-Q4_K_M.gguf
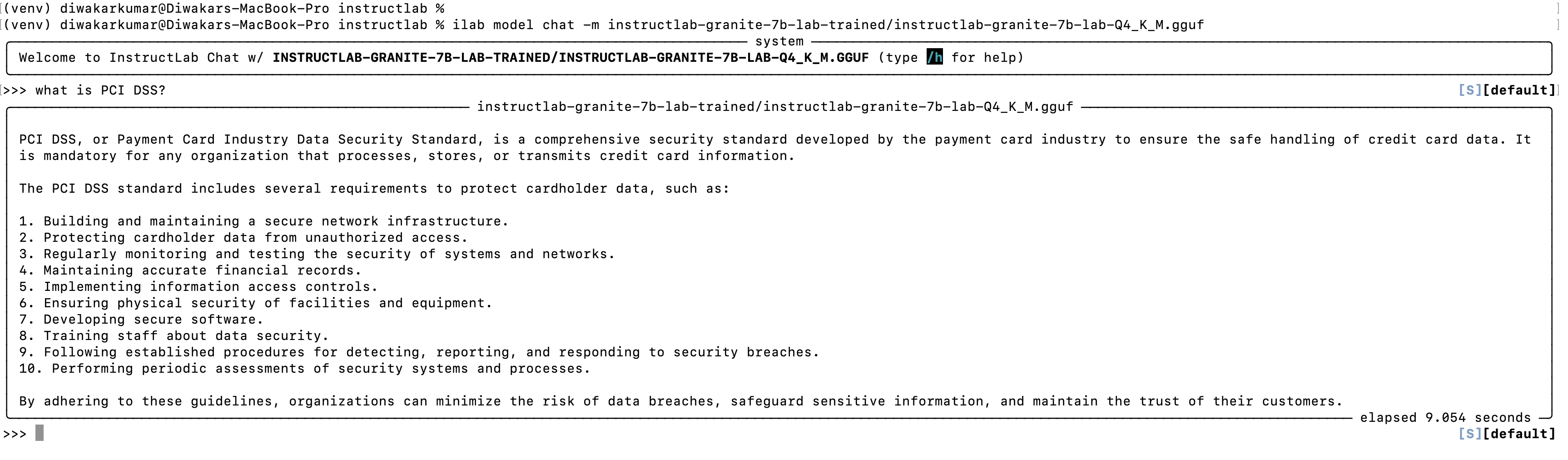
Try asking the same questions as before to the newly trained model:
- What is PCI DSS?
- What are the recommended practices for securing payment systems against common security threats?
You should see that the InstructLab-trained model performs better than pre-trained model for a specific domain.
Summary and next steps
This article delineated the current limitations in handling LLMs including the need for GPUs, human expert intervention to craft data for training, lack of ability for collaborative contribution. It delved deeper on how to use InstructLab to install and generate specialized models from IBM’s Granite model by sourcing synthetic data from the merlinite model using a basic MacOS computer.
Acknowledgements
This article was developed through the Financial Services Market (FSM) AI Engineer Community in IBM Client Engineering.