About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Exploring the pre-built transforms in Data Prep Kit (DPK)
Streamline data preparation for your AI applications using the diverse set of pre-built transforms in DPK
The Data Prep Kit (DPK) is an open source framework that offers a versatile suite of pre-built transforms, or data prep modules, that can be categorized into these primary domains:
- Data ingestion. These modules facilitate the extraction and loading of data from diverse sources.
- Universal. These modules provide general-purpose data processing and transformation capabilities that are common across different data modalities.
- Natural language: These modules encompass tools for natural language data curation understanding and processing tasks.
- Code: These modules offer functionality for code data analysis, cleansing, and transformation.
To enhance scalability and efficiency, many of these transforms are implemented using distributed computing frameworks such as Ray and Kubeflow Pipelines (KFP) on Ray. Additionally, Spark-based scaling is employed for specific transforms. For pure Python transforms, parallel processing is leveraged through the Python multi-processing pool. The following table shows the current list of built-in data prep modules in DPK.
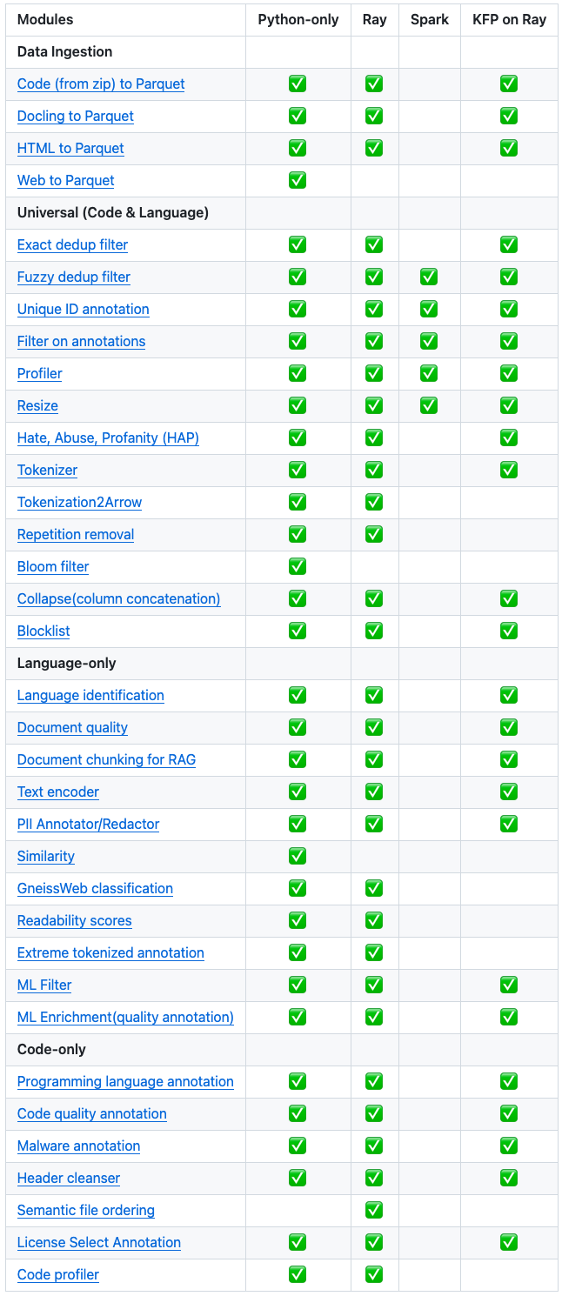
Data ingestion modules
The initial set of transforms focus on ingesting and converting various data formats into a standardized parquet format. The first three transforms are ingesting Code (in the form of Zip files), PDF, and HTML to DPK and converting them to Parquet files. All other subsequent transforms process parquet files as input and create parquet files as output.
- Code2Parquet. This transform processes compressed code files (ZIP) and converts them into parquet format.
- HTML2Parquet. This transform leverages the Trafilatura library to process HTML files and convert them into parquet format. It can handle both single HTML files and ZIP archives containing multiple HTML files. It allows the conversion of HTML documents to the Arrow table which is then processed into parquet files containing the converted document in string format.
- Docling2Parquet. This transform processes mutiple file formats, either individually or in ZIP archives, and converts them into parquet format using the Docling library. Docling supports a wide range of input formats, including PDF, DOCX, PPTX, XLSX, Markdown, images, and ASCII documents.
- Web2Parquet. This transform, built on the Scrapy framework, actively crawls the web, downloads files in real-time, and converts them into parquet format.
Universal modules
Universal transforms are a versatile set of tools designed to process both language and code data. They offer a range of capabilities to clean, preprocess, and enhance data quality. Currently, we have the following universal transforms:
- Exact Dedup. This transform identifies and removes exact duplicate records. It employs a hash-based approach for efficient duplicate detection, enabling parallel processing. The assumption here is that a hash is unique to each native document. In the heart of the implementation is a cache of hashes of documents seen so far which allows for easy parallelization of individual document processing.
- Fuzzy Dedup. This transform detects near-duplicate records, even with minor variations. It uses advanced techniques like MinHash and LSH to compare records and identify similarities.
- Unique Doc ID. This transform assigns unique identifiers to documents for tracking and reference. It generates unique integers and content hashes to distinguish each document which later can be used in de-duplication and other operations.
- Filter. This transform applies SQL-like filtering to remove unwanted records. It offers a flexible filtering mechanism based on user-defined criteria. Usage of the SQL-based filtering allows for the creation of a single filtering implementation that can be used for a variety of document filtering.
- Profiler. This transform analyzes data to gain insights into its characteristics. It provides basic word count to assess data quality. Additional profiling implementations can be added to transforms.
- Resize. This transform optimizes file sizes for efficient processing. It splits large files and combines small ones to balance processing load. As much of the transform execution is parallelized, their resizing is very important to avoid skews in the individual file processing times.
HAP. (Hate, Abuse, and Profanity). This transform detects and scores harmful content. Each row in the parquet table represents a document, and the HAP transform performs the following three steps to calculate the HAP score for each document:
- Sentence splitting. NLTK is used to split the document into sentence pieces.
- HAP annotation. Each sentence is assigned a HAP score between 0 and 1, where 1 represents HAP and 0 represents non-HAP.
- Aggregation. The document’s HAP score is determined by selecting the maximum HAP score among its sentences.
Tokenization. This transform breaks down text (sentence, paragraph, document) into smaller units (tokens). It leverages the Hugging Face tokenizer for precise tokenization to prepare input for a model.
- Tokenization2Arrow. This transform is built upon the Tokenization transform. For every input parquet file it generates an
.arrowand two metadata files. The.arrowfile contains actual tokens. One metadata file contains one line summary of file with content and the other metadata file contains details of token count for every document of file. - Repetition Removal. This tranforms performs text repetition removal to remove sequences that frequently occur at documents within a single parquet file level. The work is adopted from here to identify and remove all substrings of a given length that are repeated more than some threshold number of times.
- Bloom Filter. Recently, IBM has introduced GneissWeb; a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. The models trained using GneissWeb dataset outperform those trained on FineWeb by 2.14 percentage points in terms of average score computed on a set of 11 commonly used benchmarks. The Bloom Annotator transform assigns a label of 1 if the document is present in the GneissWeb Bloom filter; otherwise, it assigns 0. This approach provides a clear understanding of which documents in FineWeb are also present in GneissWeb and which are not. The GneissWeb Bloom filter is just one use case; the Bloom Annotator transform can work with any Bloom filter.
- Collapse(Column Concatenation). This transform merges all the text columns specified by the user into a single column. By default, the merged columns will be removed from the parquet file to reduce the overall size of the output parquet file.
- Blocklist. The block listing annotator/transform maps an input table to an output table by using a list of domains that are intended to be blocked (i.e., ultimately removed from the tables).
Language modules
Language transforms are a specialized set of data processing techniques designed to prepare language-specific data for various downstream applications. Here are the key language transforms and their functionalities.
- Language identification. This transform accurately identifies the language of text data. It uses the fasttext language identification model to assign language labels and confidence scores to text data.
- Document quality. This transform evaluates document quality by calculating and annotating relevant metrics, Inspired by Deepmind's Gopher paper, the transform calculates and annotates metrics such as document length, readability, and topic coherence.
- Document chunking. This transform divides documents into smaller, coherent chunks based on their structure (JSON or Markdown). When using documents converted to JSON, the transform leverages the Quackling HierarchicalChunker to chunk according to the document layout segmentation, that is respecting the original document components as paragraphs, tables, enumerations, and so on. It relies on documents converted with the Docling library. When using documents converted to Markdown, the transform leverages the LlamaIndex MarkdownNodeParser, which relies on its internal Markdown splitting logic.
- Text encoder. This transform generates embedding vectors for text data, enabling tasks like sentence similarity, feature extraction, and RAG applications. It uses sentence encoder models to create embedding vectors of the text in each row of the input Parquet table.
- PII redactor. This transform protects sensitive information by identifying and masking PII entities. It leverages the Microsoft Presidio SDK for PII detection and uses the Flair recognizer for entity recognition.
- Similarity. This transform annotates each input document with potential matches found in a document collection. The annotation consists of a JSON object proving the ID of the matched document in the collection and the specific sentences deemed as "similar" by the transform. The transform relies on a running ElasticSearch Index. We assume (and provide) a functioning endpoint, but you can spin up your own service (read more about ElasticSearch Configuration in the DPK repo).
- GneissWeb Classification. This transform will classify each text with confidence score using multiple fasttext classification models such as: ibm-granite/GneissWeb.Quality_annotator , ibm-granite/GneissWeb.Sci_classifier , ibm-granite/GneissWeb.Tech_classifier , ibm-granite/GneissWeb.Edu_classifier , and ibm-granite/GneissWeb.Med_classifier.
- Readability Scores. This transform annotates documents of a parquet file with various Readability Scores, originally defined in the textstat github page, that can later be used in Quality Filtering.
- Extreme-tokenized Annotation. This annotator retrieves the tokens generated for a set of documents. Then, it calculates, for each document, the size and the total number of characters. The number of tokens is divided by the size and by the number of characters, and the resulting values are stored in two columns. Documents with extremely high or low number of tokens per character (or tokens per byte) are identified as extreme-tokenized documents and can be excluded in the filtering step.
- ML Filter. This multilingual (ML) transform filters the data using conditions specified in a corresponding configuration
yamlfile. Here is a sample configuration file. The config file has to contain a section for each language that it accepts. - ML Enrichment (Quality Annotation). This transform computes a number of features that can be later used to estimate the data quality. It adds a large number of columns to the document with each column showing a metric that is indicative of document quality, e.g., "num_paragraphs" , "num_words" , "num_chars" , "total_non_newline_chars" , "avg_word_length", "avg_paragraph_length_chars", etc.
Code modules
Code transforms are a suite of specialized transforms designed to process and prepare code-specific data. By effectively using these code transforms, users can prepare high-quality code and natural language datasets for various machine learning and AI applications.
Currently, there are these ccode transforms:
- Programming Language Select. This transform identifies and categorizes code samples based on their programming language. It adds a new annotation column that can specify a boolean True/False based on whether the rows belong to the specified programming languages (for example, Python, Java, or C++).
- Code Quality. The transform captures code-specific metrics of input data. The implementation is inspired by the CodeParrot and StarCoder projects along with ast-based checks.
- Malware. This transform scans code samples for malware. It scans the 'contents' column of an input table using ClamAV and adds a new column to the dataset indicating whether a virus was detected and, if so, its signature.
- Header cleanser. This transform removes license and copyright headers from code samples. It leverages the ScanCode Toolkit to accurately identify and process licenses and copyrights in various programming languages, ensuring a clean dataset for further analysis.
Repository Level Ordering. This transform organizes code samples within a repository based on file path or semantic ordering. It also groups code samples by their dominant programming language. It requires the input data to have at least the following columns:
- Repo name. Name of the repo, it is used for grouping in this transform.
- Title. This is usually the file path.
Language. Programming language of content
For more information on this transform, please see the paper here.
License Select Annotation. This transform filters code samples based on their license. It checks the license against a predefined list of approved and denied licenses. This filter scans the license column of an input data set and appends the license_status column to the dataset. The type of the license column can be either string or list of strings. For strings, the license name is checked against the list of approved licenses. For list of strings, each license name in the list is checked against the list of approved licenses, and all must be approved. A new column is added to the data set, indicating whether the license is approved or denied.
- Code profiler. This transform extracts the base syntactic concepts from the multi-language source codes and represents these concepts in a unified language-agnostic representation that can be further used for multi-language data profiling. While programming languages expose similar syntactic building blocks to represent programming intent (such as importing packages or libraries, functions, classes, loops, conditionals, comments, and others), these concepts are expressed through language-specific grammar, which is defined by distinct keywords and syntactic form.
Example Jupyter Notebooks
The Data Prep Kit includes multiple Jupyter Notebook examples of using these pre-built transforms, as either a single transform or in combination with other transforms.
Summary
The Data Prep Kit (DPK) offers a diverse set of pre-built transforms to streamline data preparation for AI applications. These transforms cater to various data formats, including text, code, and structured data. While the next article will delve into creating custom transforms, DPK's built-in options provide a strong foundation for handling common data processing tasks. This rich collection of built-in transforms empowers one to efficiently prepare the data for various AI and machine learning applications.