About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Tutorial
Backup and restore Red Hat OpenShift cluster applications with OADP
Learn how to effectively use OADP and Velero for reliable backup and restore of OpenShift cluster applications
On this page
The OpenShift API for Data Protection (OADP) is crucial for the reliable backup and restoration of OpenShift cluster applications. OADP, which includes Velero, handles data protection tasks for OpenShift cluster resources and persistent volumes, providing an abstraction layer and APIs to simplify these procedures. Given that OpenShift manages containers, numerous Namespace resources—including Deployments, Replica Sets, Daemon Sets, ConfigMaps, Secrets, Services, Routes, and Persistent Volume Claims—must be preserved during backup to ensure a complete restore. OADP secures and manages data efficiently by backing up and restoring resources from a cloud object storage bucket. This article explores how OADP, utilizing Velero, facilitates backup and restore operations for OpenShift applications.
For a high-level overview of the topics discussed in this tutorial, check out OpenShift API for Data Protection in IBM Cloud. It provides a great summary before diving into this tutorial.
Cluster requirements for OADP
The resource requirements for OADP depend on several factors, such as the size of your cluster, the number of applications and persistent volumes being backed up, and the frequency of backup operations. Since OADP operates as a collection of pods within your OpenShift cluster, it's essential to ensure that your cluster has sufficient CPU and memory resources to accommodate these pods along with your other workloads. Monitoring resource utilization and performance is advisable to prevent any negative impact on the overall stability and performance of your cluster caused by OADP.
Our testing was conducted using OADP version 1.3 on clusters running version 4.12, or later. If your cluster uses an older version, you may need to use an earlier version of OADP. It is recommended to consult the OADP documentation and ensure you are referencing the correct version to obtain the most accurate information.
Integrating OADP with ODF
When used together, the OpenShift API for Data Protection (OADP) and OpenShift Data Foundation (ODF) can provide a comprehensive backup solution for your OpenShift cluster. ODF allows you to provision and manage File, Block, and Object storage for your containerized workloads, creating a layer of virtualized storage that duplicates your application data for high availability. Combining ODF with OADP is ideal for clusters housing critical applications with complex data management needs. While OADP handles backup and restore operations, ODF ensures data resilience within the cluster.
Note that this tutorial focuses solely on using OADP. The complex ODF storage setup was not included in our backup and restore tests; therefore, we cannot guarantee performance or compatibility with the procedures and materials outlined in this tutorial.
Best practices for restoring workloads
Understanding the workload you are restoring is crucial because workloads often need to be restored incrementally to ensure each component is correctly reintegrated without disrupting the system. Operators should not be restored directly; instead, document the operators present in the original clusters and their versions. Our experience shows that iterating through the restore process multiple times helps identify the most efficient approach. Recently, we’ve emphasized the importance of keeping detailed notes during the restore process. This practice accelerates future restores and facilitates knowledge sharing. Additionally, automating the restore process is highly beneficial. Automation enables consistent, efficient restores, reduces the risk of human error, and enhances the overall reliability of the restore process.
For example files discussed in this tutorial, visit the GitHub repository. The repository includes a segment of an automation script to demonstrate practical implementation. This resource aims to provide a comprehensive guide for readers to deepen their understanding and facilitate hands-on learning.
Prerequisites
- Primary ROKS OpenShift cluster
- Secondary ROKS OpenShift cluster
- Application to back up
- IBM Cloud account
- Cloud Object Storage (COS) bucket on IBM Cloud
Step 1. Install OADP operator on Primary and Secondary clusters
Navigate to the OpenShift cluster dashboard.
Ensure you are in Administrator mode.
On the left-hand side, expand Operators and select OperatorHub.
Search for and install the OADP operator.
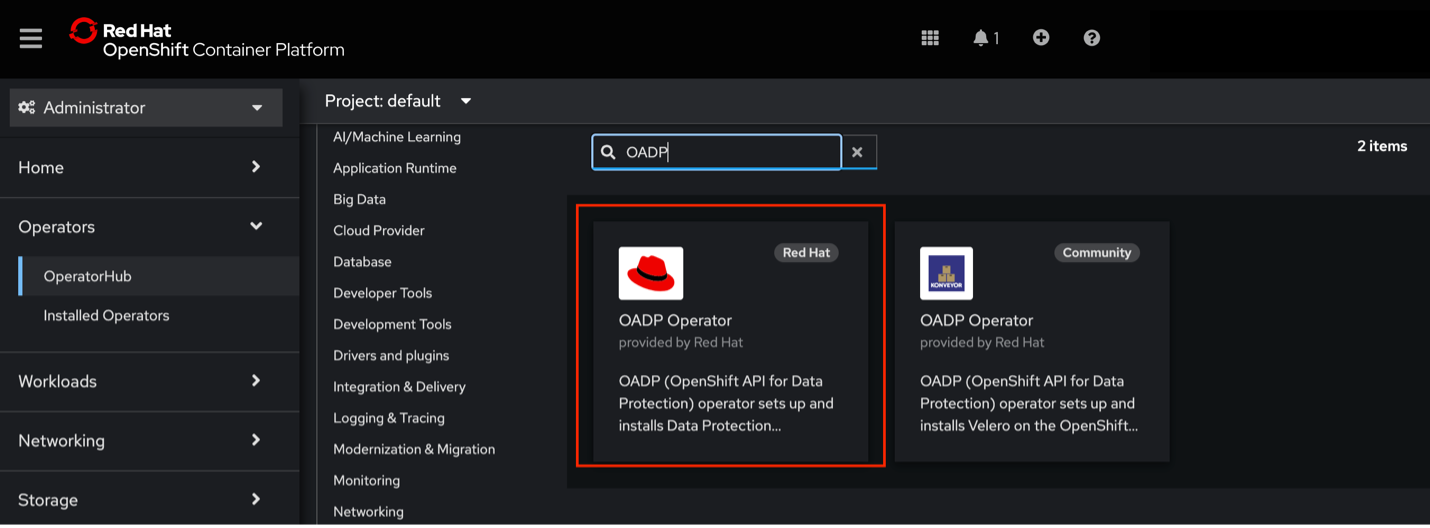
Keep the default settings and ensure OADP is installed in the recommended namespace:
OADP: openshift-adpNote: If you choose to use OpenShift Data Foundation (ODF), install it on both clusters at this time. Refer to the ODF installation guide for instructions. Be aware that using ODF will incur additional costs.
Step 2. Create or identify an IBM Cloud Object Storage (COS) bucket and credentials
Create a COS Bucket (if needed):
Follow the instructions to create a COS bucket.
When setting up your COS bucket and cluster, it's best to keep them in the same region if possible. For added resiliency, consider creating the COS bucket in a different account to protect against potential failures.
Retrieve or Create Service Credentials:
Navigate to your COS instance and select the
Service Credentialstab.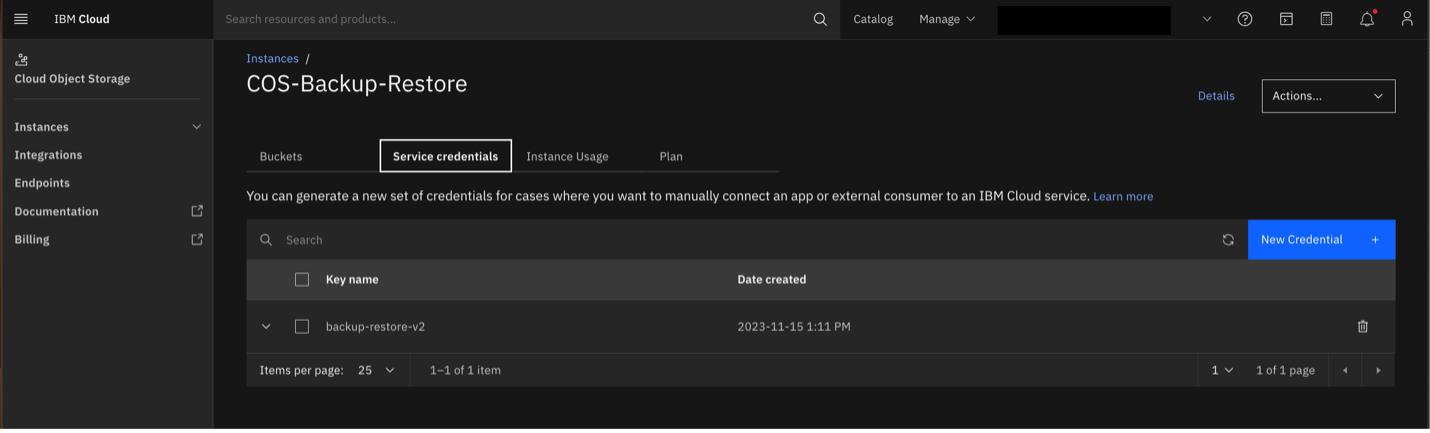
If you need to create service credentials, select the role as Manager and ensure that the
Include HMAC Credentialoption is selected.
Note down the access and secret keys as they will be needed later.
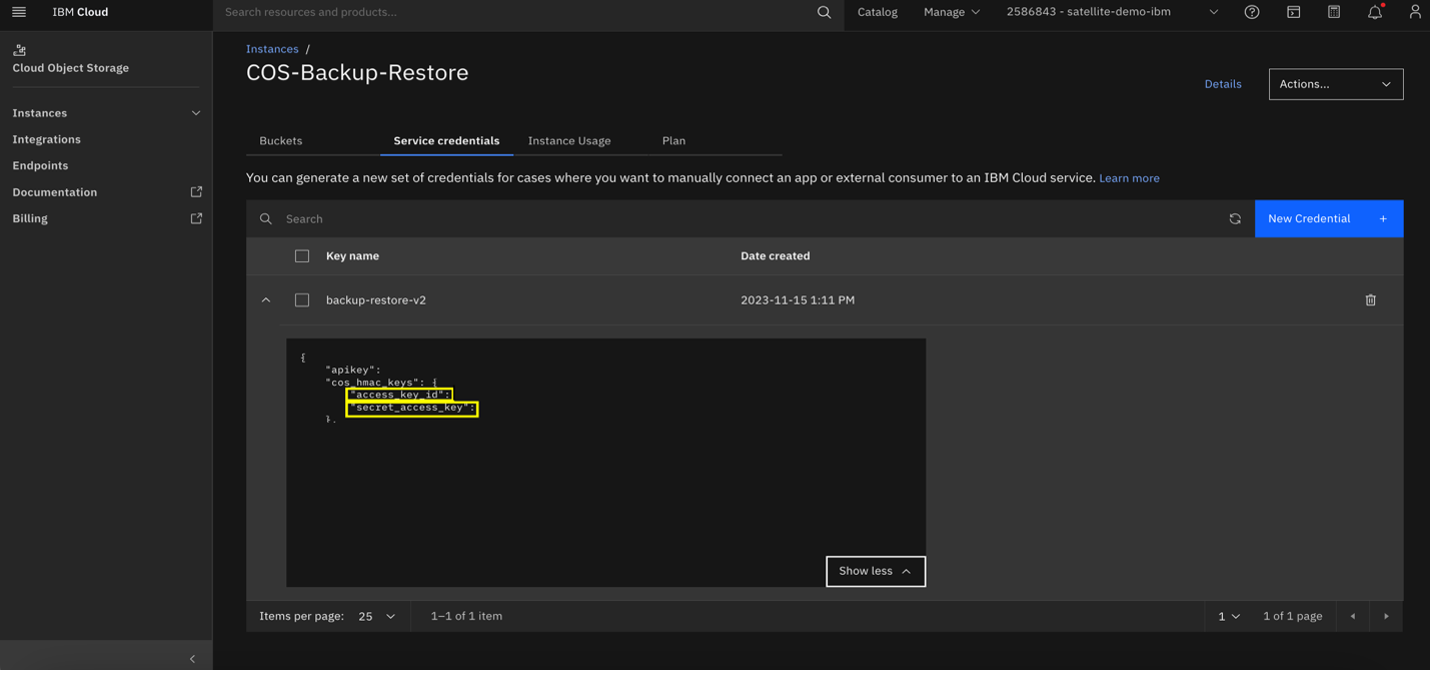
Step 3. Create a Secret on the Primary and Secondary Clusters Containing COS Credentials
Prepare the Credentials File by updating the
ibmcos-bucket-creds.jsonfile with the access and secret keys from your COS instance.Create the Secret in OpenShift:
- Navigate to the OpenShift cluster dashboard.
- Expand
Workloadsand selectSecrets. - Ensure you are in the
openshift-adpproject. Click Create and select Key/Value secret.
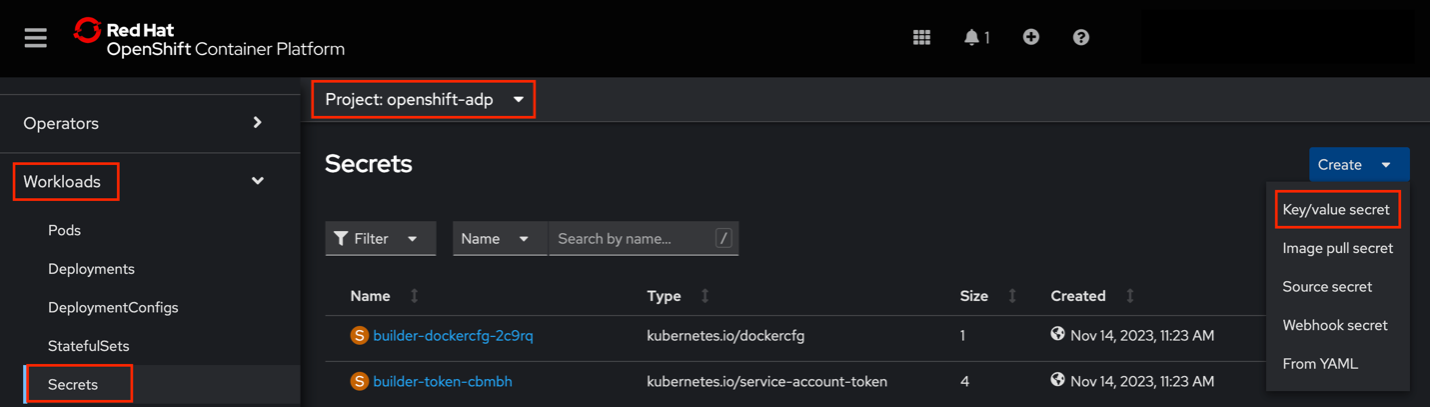
Configure the Secret:
- Set the Secret name to
cloud-credentials. - Set the Key to
cloud. - Select Browse and upload the
ibmcos-bucket-creds.jsonfile. Click
Create.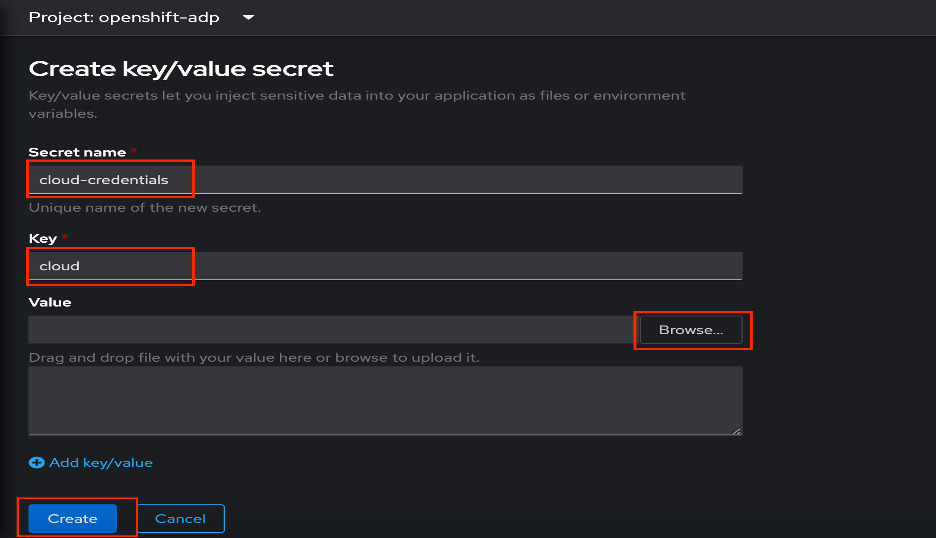
- Set the Secret name to
Step 4. Create a data protection instance on the primary and secondary clusters
The Data Protection Application (DPA) within OADP plays a crucial role in orchestrating backup and restore operations for workloads. It leverages Kubernetes APIs and integrates seamlessly with OpenShift, providing a consistent interface for data management. The DPA can interface with various storage solutions, adapting to different infrastructures, whether on-premises or cloud-based. The DPA resource defines the desired state of OADP.
Open the
oadp-dpa.yamlfile and update it as needed.Retrieve the COS bucket public URL:
- Navigate to your COS bucket and select
Configuration. Scroll down to find Endpoints and copy the URL for the Public Endpoint.

- Navigate to your COS bucket and select
Create the Data Protection Application:
- On the cluster dashboard, go to
Operators>Installed Operators. - Ensure you are in the
openshift-adpproject. - Select the
OADP Operator. Navigate to
DataProtectionApplication.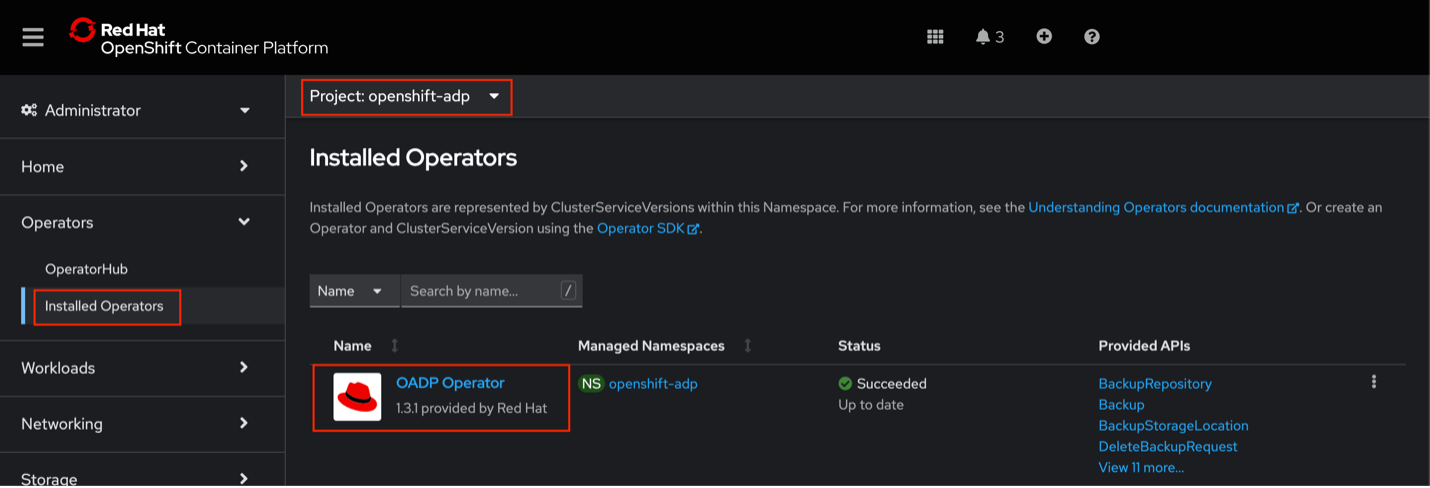
- On the cluster dashboard, go to
Configure and deploy:
- Click
Create DataProtectionApplication. - Switch to the YAML view and paste the contents of the
oadp-dpa.yamlfile. Click Create.

- Click
If everything is configured correctly, the DataProtection instance will have a status of
Condition: Reconciled.
Step 5. Create a backup instance on the primary cluster only
OADP offers different methods for backing up data, including the Container Storage Interface (CSI) backup method and the Filesystem backup method.
CSI backup method
For workloads utilizing CSI drivers for storage, the CSI backup method aligns seamlessly with the Kubernetes-native approach. CSI facilitates the creation of consistent snapshots of persistent volumes, which is ideal for applications like databases requiring point-in-time data consistency. Leveraging CSI snapshots, if supported by your storage solution, streamlines backup integration with your storage layer. These snapshots are typically efficient, utilizing the storage system’s snapshot capabilities.
When using the CSI backup method in ROKS clusters, it's crucial to ensure that the target cluster is in the same account as the snapshots and encryption keys. CSI relies on block storage snapshots, so these snapshots and their associated encryption keys must remain accessible within the same cloud account. Unlike other methods that might use COS buckets, CSI’s dependence on block storage snapshots requires careful management of both snapshots and encryption keys to enable smooth restores. This approach ensures reliable backup and recovery operations within ROKS clusters.
During restores using CSI, we found effective strategies to ensure smooth recoveries. We focused on restoring volume snapshots and addressed issues where restored volumes requested more storage than needed by reformatting the volumes to match the original cluster’s requested storage size. This ensured consistency and functionality.
Filesystem backup method
In cases where your storage provider lacks CSI support or your persistent volumes aren’t managed via CSI drivers, filesystem backups offer a more universal solution. Additionally, filesystem backups offer versatility in storage locations and formats, granting flexibility in managing backup data. They are also more portable across different platforms and storage solutions, making them suitable for multi-cloud environments.
The filesystem backup method enables you to restore data in a different account because all data is stored in the COS bucket.
During filesystem restores, we ensured that persistent volumes were mounted to a pod. If a volume was not already mounted, we created a temporary pod for this purpose. Following this, we restored the pods within the namespace containing the desired volumes.
Steps to create a backup
Prepare the Backup File:
Open either the
backup-csi.yamlor thebackup-filesystem.yamlfile and update it according to your needs.Ensure to list all namespaces required for your application.
Create the Backup:
On the cluster dashboard, navigate to
Operators>Installed Operators.Ensure you are in the
openshift-adpproject.Select the OADP Operator.
Navigate to Backup.
Click
Create Backup.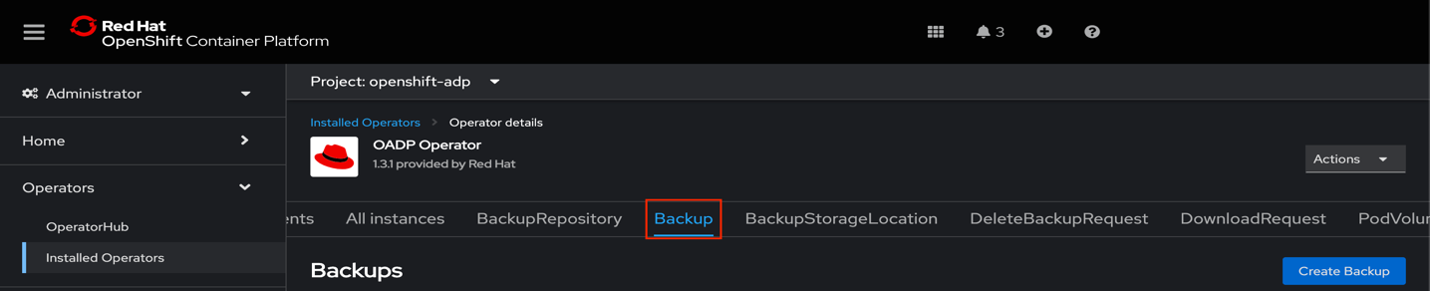
Switch to the YAML view and paste the contents of the backup file.
Click Create.
If everything is configured correctly, the Backup instance will have a status of
Phase: Completed. At this point, you can check your COS bucket; you should see files from your application in the bucket.
Note: If you encounter an error when creating the backup, check your COS bucket for an error log file that you can use to troubleshoot.
Step 6: Create a restore instance on the secondary cluster only
Open one of the restore files (
restore-1-example.yamlorrestore-2-example.yaml) and update it according to your needs.Create the Restore:
On the cluster dashboard, navigate to
Operators>Installed Operators.Ensure you are in the
openshift-adpproject.Select the OADP Operator.
Navigate to Restore.
Initiate the Restore Process:
Click
Create Restore.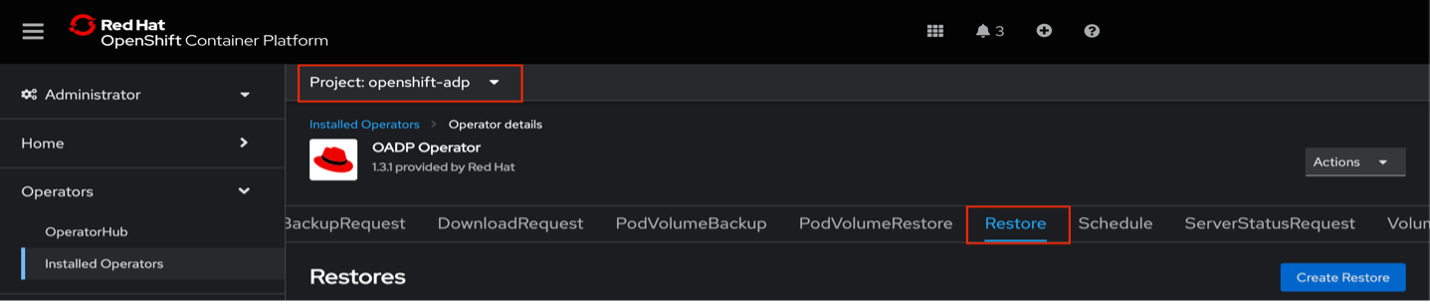
Switch to the YAML view and paste the contents of the restore YAML file.
Click Create.
If everything is configured correctly, the Restore instance will have a status of
Phase: Completed. You can now check that your application is running on the new cluster.
Considerations when restoring resources
Velero supports a feature called a resource modifier, which allows the alteration of resources during the restoration process using JSON patches. These patches are defined in a ConfigMap and applied to the resources before they are restored. Refer to an example resource modifier YAML file at Github repository.
Creating a temporary pod for file system backup
- Scenario: You have a persistent volume (PV) containing important data that is not currently mounted. If the volume is not mounted, it will not be included in the backup.
- Action: Create a temporary pod to mount the volume.
- Explanation: The temporary pod runs with a sleep loop, ensuring the volume remains mounted during the backup process.
Patching secrets
- Scenario: Secrets contain the original cluster domain.
- Action: Patch these secrets to match the new cluster domain.
- Explanation: This prevents services from referencing outdated endpoints, ensuring they point to the correct resources in the new cluster.
Updating credentials in secrets
- Scenario: Secrets contain credentials that must match the new cluster settings.
- Action: Update or revalidate the credentials.
- Explanation: Ensures the credentials are valid for the new environment, maintaining secure access to necessary resources.
Reviewing and updating ConfigMaps
- Scenario: ConfigMaps hold configuration data relevant to the cluster.
- Action: Review and update the configuration data as necessary.
- Explanation: Ensures that configuration settings reflect the new cluster environment, maintaining consistency and functionality.
Patching routes
- Scenario: Routes still point to the old cluster domain.
- Action: Patch these routes to reflect the new domain.
- Explanation: Ensures traffic is directed correctly to the new cluster, avoiding disruptions in service availability.
Recycling TLS secrets
- Scenario: TLS secrets must be updated for the new domain.
- Action: Recycle the TLS secrets.
- Explanation: Ensures secure communication with valid encryption, maintaining the integrity and security of data transmissions.
Restarting pods
- Scenario: Changes in secrets, ConfigMaps, or other configurations need to take effect.
- Action: Restart pods that reference these resources.
- Explanation: Applies updates, ensuring applications and services use the updated configurations, thus maintaining stability and performance in the new cluster environment.
Conclusion
Reliable backup and restore of OpenShift cluster applications depends on the OpenShift API for Data Protection (OADP) utilizing Velero. By managing the preservation of various Namespace resources and persistent volumes, OADP ensures comprehensive recovery capabilities. Our testing highlights the necessity of appropriate version matching and diligent documentation consultation, performed on current OpenShift versions with OADP 1.3. OADP’s Data Protection Application (DPA) leverages Kubernetes APIs to facilitate consistent backup operations using both Container Storage Interface (CSI) and filesystem backup methods. The use of JSON patches for resource modification further enhances the flexibility of OADP across diverse storage systems. This tutorial provided detailed procedures and automated strategies for effective data protection, emphasizing the critical role of OADP in safeguarding OpenShift environments.