About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Article
Improving and automating your ops
Cloud Pak for AIOps reduces the time SREs spend in issue resolution and avoidance though intelligent context and automation
On this page
Archived content
Archive date: 2025-08-22
This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.In today’s fast-paced digital landscape, the seamless integration of development and operations is more critical than ever. DevOps and SRE practices have revolutionized how organizations manage and deploy their applications. Solutions like Cloud Pak for AIOps are indispensable assets to empower teams to leverage advanced AI-driven insights and automation. This article explores how Cloud Pak for AIOps can help SREs or IT Ops engineers by enabling them to predict, prevent, and resolve issues with precision and agility.
In the past, it used to be that the developer and operations roles were fully separated. The developer received the business requirements, they came up with a design and implemented it. A dedicated QA team wrote tests, and validated that the new application, capability, or change worked as expected, and then the code or application was handed over to the operations team to run it. In most organizations, these roles have now merged into a set of development practices that are commonly referred to as DevOps.
At the same time, DevOps practices brought an expanded role for the operations teams, typically referred to now as a Site Reliability Engineering, or SRE. Red Hat defines the DevOps practice of SRE like this “SRE takes the tasks that have historically been done by operations teams, often manually, and instead gives them to engineers or ops teams who use software and automation to solve problems and manage production systems.”
Often, the SRE role can be either a dedicated engineering position or one that developers frequently take on, either full-time or part-time. The goal of SRE is to create a natural improvement cycle, which one gets by linking the application development and operations portions. The applications can be created such that they are easier to manage and observe, while the insights from monitoring the application, can in turn identify inefficiencies, defects, and potential improvements.
In this article, we will focus on how Cloud Pak for AIOps can help an SRE (site reliability engineer) improve and automate their applications. To reiterate, though, while we will use the term SRE throughout this article, SRE also applies to IT Operations (IT Ops) engineers and application developers who are supporting their products.
An SRE focuses on reacting to problems encountered by the application, but also on crafting ways to improve the time to repair the application (typically measured as MTTR), or even better on avoiding these problems in the first place.
So, what is important to an SRE? When a problem occurs, they need to have a holistic view of what is happening to their application. This means they should have a real-time view of the state of all their components, understand what is relevant in their logs or metrics, and know whether any of their monitors, such as synthetic consumption monitors show any problems. However, they do not want to be inundated with lots of different alerts going off, but rather they want to know where to focus their time and attention. After a problem has been confirmed, they would like guidance on possible solutions, and automation to execute them. Ideally though, this would be available to them before a problem becomes an outage.
Historically, two factors stood in the way here: the sheer volume of data and the fact that a lot of that data was in an unstructured format. As long as there have been applications, there have been simple monitoring tools. For example, an operator would set an alert on the memory consumption of an application, and when it breached a given amount, an alert would go off. Apart from being a blunt instrument (more on that later), this approach might have been practical when the operator was monitoring a handful of monolithic applications.
Now that SREs are monitoring thousands of microservices, this approach is no longer practical. Secondly, with the advent of AI, we now have a way to unlock all the value of unstructured (natural language) data. For example, many problems show early warnings in your logs, long before an application starts showing problems (because, the code takes a different path or the developer knows that there is a condition that they want to warn about, such as a certificate is about to expire), but the problems don’t have an impact yet and thus they won’t fail the main application flow.
As such, some of the features that an AIOps solution like Cloud Pak for AIOps that support SREs are:
- No code changes are required. Your applications and your site reliability processes already output a lot of helpful information. It’s time to take advantage of that data.
- Bring all your disparate data sources together for a holistic view across all parts of your environment. Many organizations have multiple systems for logging and metrics (maybe containerized versus VM, or maybe by department), for tickets, topology, and observability.
- Predict problems and not just react to them. Observability is amazing, and we recommend it fully, but even assuming it’s implemented everywhere, it still focuses on reacting to problems. AIOps can go further and predict problems before they occur.
- AI should be automatic. An SRE does not want to spend their day managing the AIs that are assisting them, nor should a team of data scientists be required to understand the data. The AI should manage itself as much as possible.
- Prioritize insights and give a holistic view across the problem. Having lots of signals is all well and good, but the SRE needs guidance on what to focus on and what to de-prioritize. As such, AIOps reduces the noise, while giving a well-rounded view of the area to focus on. AIOps solutions should also be able to explain why it makes a recommendation, ultimately to build trust with the SRE.
- Automation to avoid issues in the first place. SREs are not there just to react to problems; they are there to engineer a better application. After a problem has been identified, AIOps solutions should create an automation so others can easily resolve it. And, after you have enough trust in the solution, then you can let the AIOps system solve the problem for you.
Let’s look at some details about how Cloud Pak for AIOps delivers on these features.
Seeing your whole environment
SREs have a lot of different parts in their environment to monitor, and with containerized workloads, the number of components and services has been exploding. Therefore, it is important for the SRE to easily be able to view all their environments in one place. In addition, it’s not just the SRE, but the AI assisting them, that needs a comprehensive view. A topology assists in many of the different AIs as well.
Since most environments are dynamically changing constantly, it’s critical that your SRE and Ops teams can visualize an up-to-date view of the relevant interdependencies of the applications, services and resources. But seeing an up-to-date view is only helpful relevant changes are visible, as they happen, as well as a historical view of relevant changes.
As are the set of resources in the environment constantly changing, the definition of which resources belong to an application are also constantly changing. As such the definitions of an application, or a domain is constantly evolving resulting in a need for application or resource groups as policies, rather than as static sets.
It’s also important to note that since all environments are different, the scope of what your SREs and Ops teams need to visualize can vary considerably. Your organization may want to see everything and anything supporting the application and services the business relies upon (whether that's a container, cloud provider, external service to other businesses, local/branch offices, physical machines, virtual machines, skateboards, vending machines, literally - anything), or you may only want to include a subset. It’s critical then that your AIOps solution can observe and correlate anything deemed to be relevant.
Using the Cloud Pak for AIOps topology allows teams to easily integrate many different data sources; for example, you might have Instana deployed which provides a great real-time view into the application stack, but also have ServiceNow deployed for some legacy parts of the business. Cloud Pak for AIOps brings these different views of your environment all together into a single overarching pane of glass in a topology view.
While have a cohesive mapping of your topology is extremely valuable, it could introduce the need to process a large volume of data. The Cloud Pak for AIOps topology observation and mapping capabilities have been market-tested by some of the largest and most sophisticated production environments. It’s high capacity to support connecting and merging relevant data from dozens of tools for millions of resources is a very powerful - and unique in the market.
Structured Data Insights
In operations, we are familiar with Structured data. Structured data is simply data that is structured; that is, it is data that has metadata around it explaining what it is. This could be a time series of values for a given metric, like the value of CPU usage over time, or it could be an event that contains name-value pairs in json, yaml, or xml. The key to structured data is simply that because the contents and meaning is well defined, it is easy for machines to take advantage of it.
Metrics
Metrics are probably the most common type of structured data. Since these are numeric already, they have been the ones that are easiest to understand and monitor. For example, memory consumption is between 0% and 100%. If it gets too high, then alert the operator. The problem with this approach is that it is typically statically done, and thus what should the cut-off be to notify the operator? 100% is too high for sure, but should we set it at 99%? Will that give us enough time? What if we set it at 80%? If there is a spike past it will that produce too many false positives? And it’s fine to set a threshold if you are monitoring a few VMs, but what if you are monitoring 1000s of containers? Do you know the thresholds for all of these? And what about all the other metrics? Does an SRE know what we should monitor for say the heap VM, or the incoming network bytes? So many questions!
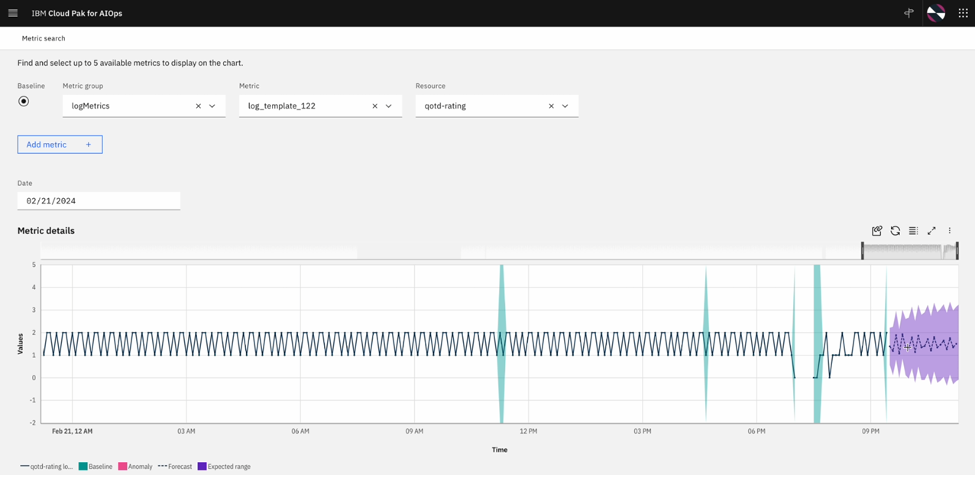
This is where the AI in AIOps comes in. AIOps, can determine not just what the threshold is, but also what pattern it should follow as well as adapting to that pattern changing over time. In Cloud Pak for AIOps, we have 6 different algorithms so that we can monitor KPIs (metrics), that we expect a given KPI (metric) to not flatline (regardless of the value), or that it should stay within certain bounds, or that it should follow another KPI as they are inter-related, and so on. Cloud Pak for AIOps can do this for every KPI (not just the 3 big ones (CPU, Memory, and Disk)) on every component in your environment.
Since environments are constantly changing, Cloud Pak for AIOps can adapt the patterns as the inevitable changes occur over time – making it easier for SREs and Ops teams to deal with constantly changing conditions.
Cloud Pak for AIOps integrates all the different data sources that produce metrics, including metrics collected by market-prevalent monitoring tools like AppDynamics, Dynatrace, and any other data sources such as your network monitoring, applications monitored by other 3rd party components, or really anything that can emit a time series set of metrics.
Cloud Pak for AIOps can also predict where each metric is going. Based on the historical trend for each KPI, we can show when a metric becomes anomalous, and also what it will likely look like into the future (see the purple part of the graph in the previous figure. This predictive analytics allows the SRE to know whether this is likely a temporary spike that they can potentially ignore or if this is trending to stay anomalous or is worsening.
For application developers, metrics are especially valuable as it helps them understand their applications behavior. When debugging a problem such as a memory leak, having metrics available is extremely valuable as it will allow them to pinpoint the problem a lot faster. Application developers can also add custom metrics to track KPIs they are interested in specific to their application. These can be technical, such as a number of items in a resource pool, or non-technical, such as the orders processed per minute.
Events
An event indicates that something happened in your environment. While this something is not necessarily a problem, it is a change and thus could be important. For example, if a machine is powered down, that is something to send an event for, but it could be because this machine is no longer in use or it could be because someone tripped over the power cord.
Cloud Pak for AIOps can consume events from many other tools or applications used by an enterprise. From observability tools like Instana, Dynatrace, AppDynamics (and many others), network monitoring tools, synthetic monitoring tools, and many more, Cloud Pak for AIOps gives SREs a complete view of the situation as it unfolds.
By providing over 150 event sources, as well as customization points, Cloud Pak for AIOps allows SREs to easily hook into any event producer.
Events typically consist of a set of name-value pairs describing what triggered it. It will include fields such as the initial severity, the resource affected, the type of event, and so on. Cloud Pak for AIOps will aggregate these events, along with metrics and log anomalies, into the same noise reduction and automation processes (described later in this article).
Unstructured Data Insights
Up until recently, almost all monitoring was done using structured data as previously described. However, now with the advent of AI, an SRE can finally take advantage of all the unstructured data they have available. Unstructured data in short, is data that is not structured. That seems obvious, but another way of saying this in our context here, is that this data is natural language. Two great examples of unstructured data are the contents of tickets and logs.
Logs
Logs have several great characteristics, but first let’s differentiate between structured log analysis and unstructured log analysis. Both have advantages, but the types of insights (and the related complexities to derive them) are very different. Structured log analysis uses metrics about logs. For example, the volume, or lack thereof, of logs. Unstructured log analysis uses the log text itself for detecting insights. In Cloud Pak for AIOps, structured log analytics are covered in the metric anomaly capabilities.
When looking at logs, it is helpful to split them into two high level use cases:
- The ability for logs to help explain an incident
- The ability to predict incidents
When using logs to explain a problem, the value that Cloud Pak for AIOps provides is in helping point an SRE to a specific portion or portions of the logs that are out of the ordinary. SREs can spend less time trying to parse all the logs and instead focus on areas of interest. This log analysis works best when combined with other issue resolutions tools. For example, if an incident occurs, and the SRE is provided several events, some pointing at logs which are anomalous, some pointing at metrics that are out of bounds, and some pointing at other events such as monitors that failed or those events provided by observability tools like Instana and others, all grouped together. Then, the SRE can quickly draw a conclusion and get to work resolving the incident.
When using logs to predict a problem, logs are helpful because they typically contain information preceding a problem. A simplified example of this scenario is one of certificates that are about to expire. Because they have not expired yet, there are no problems in the metrics, traces, or any of the other places. However, frequently, a log entry will start to show up warning of a problem. The log anomaly AI in Cloud Pak for AIOps can detect and allow for the avoidance of problems to come.
Logs are the classic go-to tool for an application developer. Just as narrowing in on anomalous log entries is valuable for an SRE, it is equally valuable for a developer debugging their application as it allows them to see un-expected behavior. And, of course, developers have the ability to add in extra log messages for areas of the code not well exposed.
Tickets
Support or incident tickets are a treasure trove of information that has been hidden away until now. SREs typically keep track of an incident in a ticket. This will include any information gathered to help with the incident, steps they tried to debug the issue, and finally any resolution steps that they performed.
Cloud Pak for AIOps uses advanced natural language capabilities to parse through the different tickets, understanding that a given ticket might have multiple proposed solutions. Based on this insight, it not only prioritizes and groups the proposed solutions, but also synthesizes a recommendation to the SRE with both the action taken and the entity (or object) it was taken on.

Now, the SRE can just skim the list, and if they all agree, jump straight to resolution. And, the sources are right there, so they can read more in the ticket.
Noise reduction
Cloud Pak for AIOps integrates all of this structured and unstructured data for the SREs. It also provides “noise reduction” capabilities to help filter the data.
Cloud Pak for AIOps operates as a sort of funnel for all this data. It ingests the raw monitoring data from many different data sources. Some are already events (aka “something happened in the environment”), while others like logs and metrics go through anomaly detection. These anomalies are then provided as events.
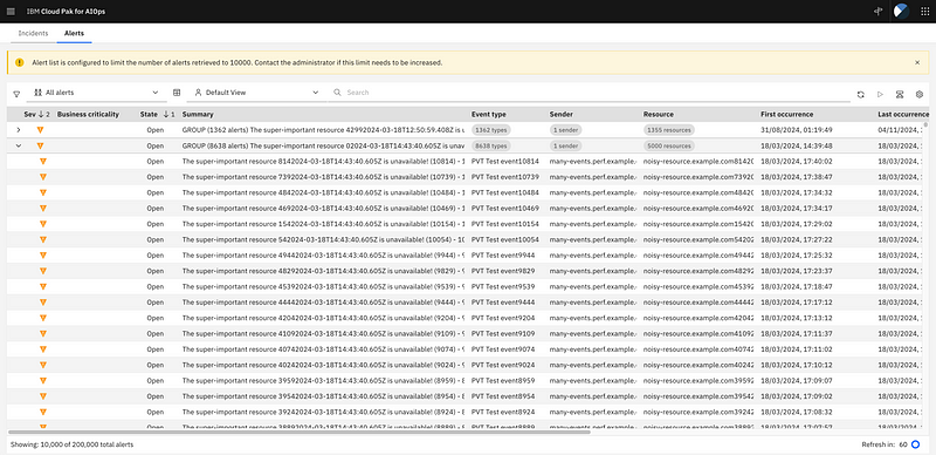
Now, all these events represent valid “something happened” events, but there is often a lot of repetition of events. For example, a metric which is out of bounds, may stay that way for a while. Every few seconds though it may send another event indicating that it is still out of bounds. The first step that Cloud Pak for AIOps takes is to filter and de-duplicate the events into alerts. An alert here is something that we care about (for example, we may filter out all user sign out events) and is unique (that is, an ongoing series of events get consolidated into a single alert).
In the following screen shot, dozens of occurrences of an event are de-depulicated into a single alert.
Next, we have these alerts, but we don’t want to notify the SRE on each individual one. Cloud Pak for AIOps groups related events together using various algorithms, based on:
- Historical co-occurrence (temporal correlation)
- Connected services (topological correlation)
- Shared values for certain attributes (scope-based correlation)
All these algorithms are trained and kept up to date automatically so that the SRE can focus on more important things.
In addition to grouping related events together into alerts, Cloud Pak for AIOps also identifies a subset of the most important alerts and creates stories that are synchronized to the ticketing system, such as ServiceNow, and then notifies the SRE using ChatOps. Cloud Pak for AIOps adds insights such as probable cause, the associated topology, a journal of changes, and more.
Automations
In addition to all the analysis and prioritizing, Cloud Pak for AIOps can automate some of the tedious and repetitive work for an SRE. It can automate all the known problems so that SREs can focus on the new problems and focus on improving the efficiency of the applications.
In Cloud Pak for AIOps, you can create runbooks to document the process that an SRE should follow. These runbooks are provided directly in a story, which makes it easier than having to go look up a process in a wiki or external document. These runbooks can be customized to be more dynamic by scripting in sone parameters for a specific cluster in your environment. SREs can create automated runbooks that include automation actions that execute over webhooks, SSH, or Ansible.
An SRE can click a button, and a repeatable process runs the same way each time. SREs can reuse existing scripts that they are already familiar with. And, when the SREs develop enough trust in the runbooks, because of the explanations for Cloud Pak for AIOps making the recommendations, the automation can be executed automatically.
As we have seen, DevOps and SRE's evolving roles and practices have significantly transformed how applications are managed and maintained. This transformation has required more sophisticated tools and methodologies to address the increased complexity and volume of data associated with modern applications. Cloud Pak for AIOps enhances SRE and IT Ops roles by integrating data, predicting issues, automating solutions, helping teams anticipate and resolve problems before they escalate, and ensuring optimal performance and reliability.
Conclusion
In conclusion, Cloud Pak for AIOps makes the jobs of an SRE (and application developer), Ops team responders, and Ops team administrators, easier and allows them to focus more on proactively avoiding incidents and providing automation. Cloud Pak for AIOps allows SREs and Ops Teams to have a holistic view of all applications or services they are responsible for, brings together insights from both structured and unstructured data, provides noise reduction to focus the SRE on the important problems at hand, and allows them to automate repetitive tasks both for accuracy and to avoid manual intervention.